[논문리뷰] SOLAR 10.7B: Scaling Large Language Models with Simple yet EffectiveDepth Up-Scaling
논문 링크: https://arxiv.org/pdf/2312.15166.pdf
SOLAR 10.7B
NLP 분야는 언어 및 사람과의 상호작용에 대한 이해가 강화된 대규모 언어모델의 등장 이후 그 장세가 크게 변화하였다. 성능에 대한 scaling law에 따라 더 큰 모델을 학습해야 하는 부담이 생긴 것이다. 대규모 학습에 대해 언어 모델을 scaling 하기 위해 MoE(Mixture of Experts)와 같은 방법이 제안되기도 하였지만, 이러한 구조는 학습 및 추론 프레임워크에 있어 변경이 필요하기에 활용성에 제약이 생긴다. 효율적이면서 효과적으로 LLM을 scale up하면서 그 간결성(simplicity)을 유지하는 것은 중요한 연구 분야이다.
SOLAR에서는 depth up-scaling(DUS) 기법을 도입하여 이러한 문제를 해결하였다.
DUS는 기본 모델을 depth 차원으로 scaling하는 부분과 scale된 모델을 계속적으로 사전학습하는 부분으로 구성된다.

DUS는 모듈에 대한 변형 없이 모든 transformer 아키텍처에 적용이 가능하며, 이렇게 scaling된 SOLAR 10.7B 모델은 Llama2나 Mistral 7B보다 좋은 성능을 보였다. 또한 학습된 SOLAR-10.7B 모델에 대해 instruction tuning을 진행한 SOLAR 10.7B-Instruct 모델의 경우, Mixtral-8x7B-Instruct 모델을 다양한 벤치마크 태스크에서 outperform 하였다.
Depth Up-Scaling
LLM을 효율적으로 up-scaling하기 위해 베이스 모델의 사전학습된 weight를 활용하여 이를 scaling up하는 접근법을 선택하였다. 이 방법은 EfficientNet (Tan and Le, 2019) 에서 아이디어를 착안한 것이다. Scaling 후 사전학습을 추가로 수행하지 않으면 성능 저하가 발생하기에, SOLAR에서도 DUS를 통해 모델을 scale-up한 뒤 continual pretraining을 수행한다.
Base Model
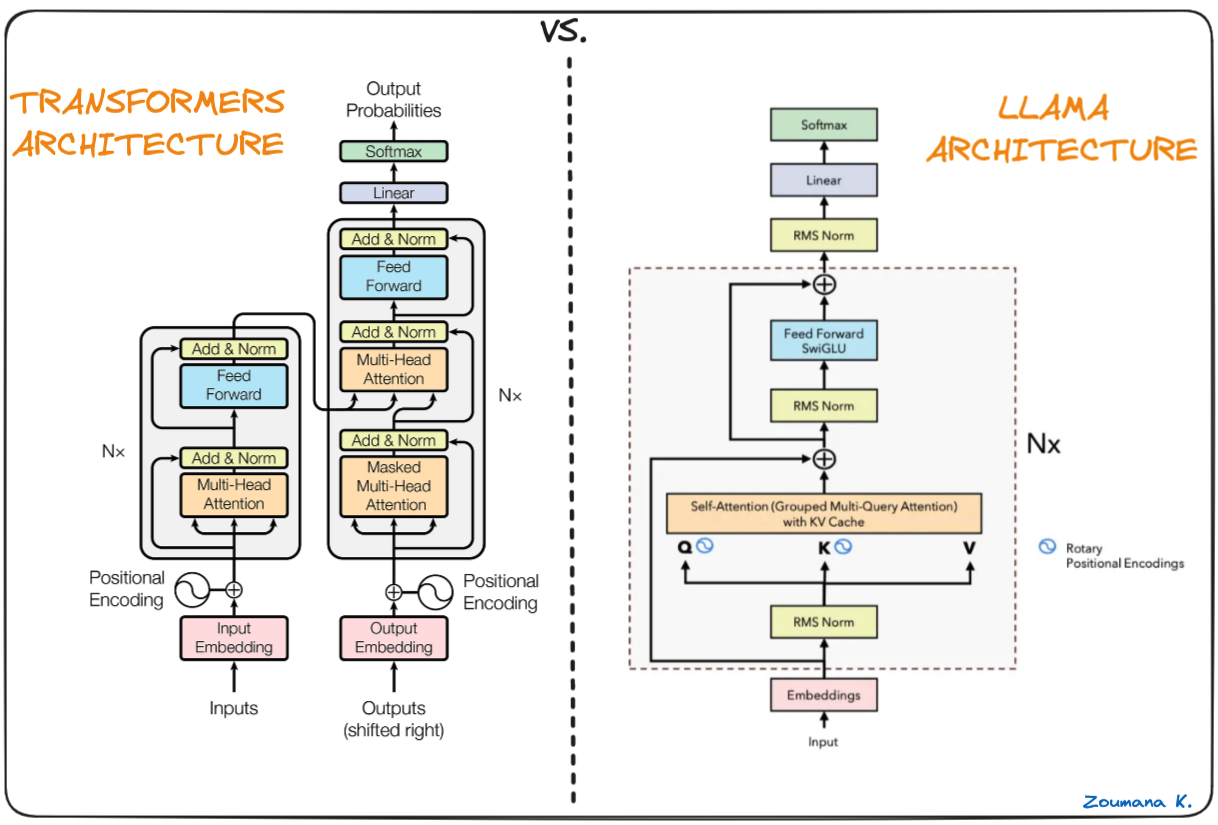
n개의 레이어를 가진 트랜스포머 아키텍처라면 DUS를 적용할 수 있지만, SOLAR에서는 32개 레이어의 Llama 2 아키텍처를 기본 모델로 선택하였다. Llama2 아키텍처와 호환되는 이후 모델 중 가장 성능이 좋은 Mistral 7B 모델으로 가중치를 초기화한다.
(참고) Llama2
- 기본 아키텍처는 LLama1과 거의 동일
- Pre-normalization 사용 (학습 안정성 개선을 위해 transformer sub-layer의 입력을 정규화)
- RMSNorm Normalizing 함수 사용
- SwiGLU activation function 사용
- Rotary Embedding 사용
- Multi Head Attention 대신 Grouped Query Attention을 사용하여 학습 및 추론 비용을 절감함
- Grouped Query Attention:
- Query head를 n개의 그룹으로 나누어 각 그룹에 하나의 Key와 Value head를 할당하는 방식
- 계산량이 많은 MHA보다 적은 head를 사용하면서도 key, value head를 하나만 사용하는 Multi Query Attention보다는 좋은 성능을 내는 아키텍처
- Grouped Query Attention:
Depthwise Scaling
n개의 레이어를 가진 베이스 모델에서 시작하여 scaling된 모델에 대한 타겟 레이어의 개수를 s라고 표기한다.
이제 depthwise scaling 프로세스는 다음과 같이 진행된다:
(1) 모델 수정을 위해 먼저 n개 레이어를 가진 베이스 모델을 복사해둔다
(2) 원본 모델에서 끝단의 m개의 레이어를 제거하고, 복제본에서 초기 레이어의 m개의 레이어를 제거하여, (n-m)개의 레이어를 가진 모델 두 벌을 준비해둔다.
(3) 이 두 모델을 연결하여 s=2(n-m)개의 레이어를 가진 scaling된 모델을 완성한다.
SOLAR에서는 하드웨어 사양과 모델 효율성(7-13B 파라미터 사용)을 고려하여 n=32, s=42로 설정되었다. 이로 인해 자연스럽게 m=8개의 레이어를 제거하여 depthwise scaling을 진행하게 된다.
Continued Pretraining
DUP를 진행한 모델은 처음에는 베이스 모델보다 성능이 떨어지기 때문에 계속적인 사전학습 단계가 필요하다.
이 과정에서 빠르게 성능 지표가 원복 되는 것을 확인하였고, depthwise scaling이 스케일 된 모델의 이질성을 분리했기 때문에 이렇게 빠른 성능 복구가 가능하였다고 본다.
스케일된 모델의 이질성(heterogenity)와 관련하여, scale-up을 할 때 DUS 대신 레이어를 그저 반복하여(n층~2n층까지) 업스케일하는 방법을 생각해 볼 수 있다. 이렇게 되면 n번째 층과 n+1번째 층이 연결된 이음매에서 레이어 거리가 최대가 되는 결과를 야기한다. 그리고 이 거리는 continued pretraining이 빠르게 학습하기에 너무 큰 차이일 수 있다. DUS에서는 2m개의 중간층을 희생함으로써 이음매 부분에서의 레이어 거리를 줄이고, 사전학습을 지속함으로써 빠르게 원래 성능을 회복한다.
학습 디테일
DUS를 진행한 후, SOLAR 10.7B 모델에 대해 instruction tuning과 alignment tuning을 진행한다.
Instruction tuning
Instruction tuning 단계에서는 QA 포맷으로 모델이 instruction을 따르도록 하는 방식을 사용했다. 대부분 오픈소스 데이터를 사용했지만, 수리 능력을 향상하기 위해 mathQA 데이터도 활용하였다.
Synth.math Instruct 구성 방법
(1) Math에서만 원천 수리 데이터를 수집하여 벤치마크 데이터와 겹치지 않도록 seed 데이터를 구성함
(2) MetaMath와 비슷한 과정을 거쳐 질문과 답변을 재구성
(3) (2)의 결과로 얻은 재구성된 질문-답변 쌍을 QA 데이터셋 형태로 구성하고, Synth.Math-Instruct라고 명명

Instruction tuning에 활용한 데이터
| 데이터셋 | 데이터 개수 | 사용한 최대 샘플 개수 | 설명 / 예시 |
| Alpaca-GPT4 | 52,000 | 52,000 | instruction: Give three tips for staying healthy. output: 1. Eat a balanced and nutritious diet: Make sure your meals are inclusive of a variety of fruits and vegetables, lean protein, whole grains, and healthy fats. This helps to provide your body with the essential nutrients to function at its best and can help prevent chronic diseases. 2. Engage in regular physical activity: Exercise is crucial for maintaining strong bones, muscles, and cardiovascular health. Aim for at least 150 minutes of moderate aerobic exercise or 75 minutes of vigorous exercise each week. 3. Get enough sleep: Getting enough quality sleep is crucial for physical and mental well-being. It helps to regulate mood, improve cognitive function, and supports healthy growth and immune function. Aim for 7-9 hours of sleep each night. |
| OpenOrca | 2,910,000 | 100,000 | system_prompt: You are an AI assistant. You will be given a task. You must generate a detailed and long answer. question: Generate an approximately fifteen-word sentence that describes all this data: Midsummer House eatType restaurant; Midsummer House food Chinese; Midsummer House priceRange moderate; Midsummer House customer rating 3 out of 5; Midsummer House near All Bar One response: Midsummer House is a moderately priced Chinese restaurant with a 3/5 customer rating, located near All Bar One. |
| Synth.Math-Instruct | 126,000 | 52,000 | (-) Open Source 데이터 아님 |
Alignment tuning
Instruction tuning된 모델에 대해 추가 fine-tuning을 통해 사람, 혹은 강력한 AI(GPT4) 등의 선호와 align될 수 있도록 DPO(direct preference optimization) 학습을 수행하였다. 이 단계에서도 대부분 오픈소스 데이터를 활용하였으나, math에 대해서는 데이터를 생성하여 사용했다.
Synth. Math-Alignment 구성 방법
Synth.Math-Instruct 데이터셋에 있는 재작성된 질문-답변 쌍은 모델의 수리적인 능력을 향상하는 데에 도움이 된다. 따라서 재구사된 질문에 대한 재구사된 답변이 원래의 답변보다도 나을 것이라고 추측한다. 이에 재구사된 질문을 프롬프트로 설정하고, 재구사된 답변을 선택된 응답으로, 원래 답변을 거부된 응답으로 사용해 {prompt, choosed, rejected} DPO 튜플을 생성하였다.
Alignment tuning에 활용한 데이터
| 데이터셋 | 데이터 개수 | 사용한 최대 샘플 개수 | 설명 / 예시 |
| Orca DPO Pairs | 12,900 | 12,900 | system: You are an AI assistant. You will be given a task. You must generate a detailed and long answer. question: Generate an approximately fifteen-word sentence that describes all this data: Midsummer House eatType restaurant; Midsummer House food Chinese; Midsummer House priceRange moderate; Midsummer House customer rating 3 out of 5; Midsummer House near All Bar One chosen: Midsummer House is a moderately priced Chinese restaurant with a 3/5 customer rating, located near All Bar One. rejected: Sure! Here's a sentence that describes all the data you provided: "Midsummer House is a moderately priced Chinese restaurant with a customer rating of 3 out of 5, located near All Bar One, offering a variety of delicious dishes." |
| Ultrafeedback Cleaned | 60,800 | 60,800 | prompt: Suggest two inputs for the following instruction in the field of psychology Instruction: Generate two potential titles for a research paper exploring the relationship between social media usage and adolescent depression. chosen: [ { "content": "Suggest two inputs for the following instruction in the field of psychology\nInstruction: Generate two potential titles for a research paper exploring the relationship between social media usage and adolescent depression.", "role": "user" }, { "content": "As a helpful and respectful assistant, I'm happy to provide two potential titles for a research paper exploring the relationship between social media usage and adolescent depression. Here are my suggestions:\n\n1. \"The Double-Edged Sword of Social Media: Examining the Impact of Online Engagement on Adolescent Depression.\"\n2. \"Social Media and the Adolescent Mind: Uncovering the Links between Online Behavior and Mental Health.\"\n\nBoth titles aim to capture the complex and multifaceted nature of the relationship between social media usage and adolescent depression, while also highlighting the importance of exploring this topic in depth.\n\nThe first title, \"The Double-Edged Sword of Social Media,\" emphasizes the idea that social media can have both positive and negative effects on adolescent mental health, depending on how it is used. This title suggests that the research will explore the potential benefits and drawbacks of social media usage, and how these may impact depression in adolescents.\n\nThe second title, \"Social Media and the Adolescent Mind,\" emphasizes the idea that social media use is a significant aspect of adolescent life, and that understanding its impact on mental health is crucial. This title suggests that the research will delve into the ways in which social media usage affects adolescent depression, and what we can learn from these findings.\n\nBoth titles are factually coherent, socially unbiased, positive in nature, and designed to engage the user. They also acknowledge the complexity of the topic and the need for a thorough exploration of the relationship between social media usage and adolescent depression.", "role": "assistant" } ] chosen-rating: 4.75 chosen-model: llama-2-13b-chat rejected: [ { "content": "Suggest two inputs for the following instruction in the field of psychology\nInstruction: Generate two potential titles for a research paper exploring the relationship between social media usage and adolescent depression.", "role": "user" }, { "content": "Sure. Here are two potential titles for a research paper exploring the relationship between social media usage and adolescent depression:\n\n1. The Relationship Between Social Media Usage and Adolescent Depression: A Meta-Analysis\n2. Social Media Use and Adolescent Depression: A Longitudinal Study\n\nI hope these titles are helpful!", "role": "assistant" } ] rejected-rating: 4.5 rejected-model: bard |
| Synth.Math-Alignment | 126,000 | 20,100 | (-) Open Source 데이터 아님 |
Results
실험 상세 내용
✔ 학습 데이터

학습 데이터는 위와 같이 구성하였으며, 항상 전체 데이터를 사용한 것은 아니다.(예. OpenOrca 데이터에 대해 subsample 사용) Instruction 데이터셋을 알파카 스타일의 채팅 템플릿으로 변환하였다. OpenOrca와 같은 데이터에 대해서는 벤치마크 데이터와 겹치는 데이터는 필터링하여 구성하였다. Alignment 데이터는 {prompt, chosen, rejected} 트리플로 구성하였다.
✔ 평가
Huggingface OpenLLM Leaderboard에 있는 5가지 벤치마크 데이터에 대해 평가한다
- ARC, HellaSWAG, MMLU, TruthfulQA, Winogrande, GSM8K
✔ 모델 병합
모델 병합을 통해 추가적인 학습 없이 모델 성능을 향상시키는 것이 가능하기 때문에 일부 모델을 병합하였다.
Instruction tuning 및 alignment tuning 과정에서 나온 모델을 병합하였고, 오픈소스 방법인 MergeKit 등이 존재하나, 자체적으로 개발한 모델 병합 기법을 사용하였다.
주요 실험 결과
아래 [Table 2]에서 SOLAR 10.7B 및 SOLAR 10.7B-Instruct 모델에 대한 평가 결과를 볼 수 있다.

SOLAR 10.7B는 Qwen 14B 및 Mistral 7B와 같이 비슷한 크기의 다른 사전 훈련된 모델보다 성능이 뛰어나며,
이는 DUS가 기본 LLM을 향상시키는 효과적인 방법임을 보여준다.
Ablation Study
✔ Instruction Tuning

Table 3은 인스트럭션 튜닝에 사용한 다양한 학습 데이터셋에 대한 ablation 실험 결과이다.
먼저, 알파카-GPT4와 OpenOrca가 훈련된 모델에 어떤 영향을 미치는지 결과를 보자. 훈련에 AlpacaGPT4 데이터 세트만 사용한 첫 번째 제거 모델인 'SFT v1'은 H6의 경우 69.15를 기록했다. OpenOrca 데이터 세트를 추가하여 훈련한 두 번째 절제 모델인 'SFT v2'를 훈련했을 때, 그 결과 H6 점수는 69.21로, 69.15의 69.15에서 거의 변화가 없다. GSM8K에서는 'SFT v2'가 57.32점으로 'SFT v1'보다 훨씬 더 높은 점수를 받았지만, ARC, HellaSwag 및 TruthfulQA에서는 전반적으로 눈에 띄게 낮은 점수를 받았기 때문에 태스크별 점수에는 다양성이 존재했다. OpenOrca를 사용하는 것은 Alpaca-GPT4만 사용하는 것과는 다른 모델 행태를 야기한다는 것을 알 수 있다.
다음으로 Synth. MathInstruct 데이터의 유효성을 살펴보자.'SFT v3'의 경우 Synth Math-Instruct 데이터 세트를 추가하여 G20K 점수를 64.14로 높이고 다른 작업에서도 비슷한 점수를 얻었다. 흥미롭게도 Synth. Math-Instruct 데이터 세트를 'SFT v1'에 추가하여 'SFT v4'를 훈련하면 모든 작업에서 'SFT v3'보다 높은 점수로 최고 H6 점수인 70.88점을 얻었다. Synth Math-Instruct 데이터의 유효성을 알 수 있다.
마지막으로 OpenOrca를 사용한 모델과 그렇지 않은 모델을 병합함으로써 성능 향상이 가능한지 확인해보았다. 첫 번째 분석에서 OpenOrca를 사용하면 OpenOrca 없이 학습한 모델과 다르게 작동하는 모델과 다르게 작동하는 것을 확인했다. 이러한 직관을 바탕으로 'SFT v3'와 'SFT v4'를 병합해보는 실험을 진행했다. 놀랍게도 병합된 모델인 'SFT v3+v4'는 'SFT v4'의 비 GSM8K 작업에 대한 높은 점수를 유지하면서도 또한 'SFT v3' 또는 'SFT v4'보다 더 높은 GSM8K 점수를 획득했다. 따라서 서로 다른 작업에 특화된 모델을 서로 다른 작업에 특화된 모델을 병합하는 것이 유망한 방법임을 알 수 있다.
✔ Alignment Tuning
실제 얼라인먼트 튜닝에 DPO를 활용하기 때문에 SFT 기반의 모델에 등에 대한 ablation study가 필요하다. 따라서 훈련에 사용되는 다양한 훈련 데이터 세트, DPO 모델을 초기화하기 위한 다양한 SFT 기본 모델, 마지막으로 최종 정렬 조정 모델을 얻기 위한 모델 병합 전략에 대해 ablation 실험을 진행했다.
학습 데이터에 대한 Ablation

Table 4에서 DPO에 사용되는 다양한 alignment data에 대한 결과이다.
먼저 Ultrafeedback Clean 및 Synth.Math-Alignment 데이터가 어떻게 작동하는지 테스트했다. 'DPO v1'의 경우 H6에서 73.06을 달성하여 SFT 기본 모델 점수인 70.03보다 크게 향상되었다. 그러나 ARC, Hellaswag, TruthfulQA와 같은 작업의 점수는 모두 큰 폭으로 향상되었지만, GSM8K의 점수의 점수는 58.83점으로 기본 모델 점수인 SFT 기본 모델 점수인 64.14점보다 낮다. Synth. Math-Alignment를 추가하여 'DPO v2'를 학습하면 GSM8k 점수는 60.27로 향상되어 SFT 기본 모델보다 SFT 기본 모델보다 낮지만 여전히 높은 점수이다. 다른 태스크에 대한 점수도 Synth.Math-Alignment 를 추가해도 부정적인 영향을 받지 않는다. 즉, Synth.Math-Alignment 데이터가 H6에 도움이 된다는 결론을 내릴 수 있다.
다음으로 'DPO v1'과 'DPO v2'를 병합하는 것이 유리한지 실험해 보았다. 안타깝게도 'DPO v1+v2'는 H6에서 73.21점으로 'DPO v2'보다 성능이 하락했다. 더 중요한 것은 Synth.Math-Alignment 추가에 따른 GSM8K 점수의 상승이다. MathAlignment를 추가했을 때 얻는 이득이 1이라는 점은 바람직하지 않다. 이러한 현상의 원인으로는 DPO v2가 DPO v1보다 확실하게 개선되었기 때문에 모델 병합이 성능을 저하했을 수도 있다.
SFT 베이스 모델에 대한 Ablation
DPO를 적용할 때는 이미 인스트럭션이 튜닝된 모델에서 시작하기 때문에 다른 SFT 모델을 사용하는 경우에 대한 ablation study도 진행해보았다.
'SFT v3+v4'가 'SFT v3'에 비해 모든 작업에서 더 높은 점수를 받았으며, 특히 ARC(+1.45)와 GSM8K(+2.43)에서 그 격차가 컸다. 놀랍게도 H6에서는 두 모델의 성능이 비슷하다. 개별 작업의 점수를 자세히 살펴보면 GSM8K의 점수에서 약간의 차이만 있을 뿐 다른 작업 점수는 거의 차이가 없다. 따라서 SFT 기본 모델의 특정 작업에서 발생하는 성능 격차가 항상 얼라인먼트 튜닝 모델에 그대로 이어지지는 않는다.
다른 merge 방법에 따른 Ablation

모델 병합을 alignment tuning 모델에도 활용하기 위해 'Cand. 1'과 'Cand. 2'라는 두 모델을 'DPO v2' 및 'DPO v3'와 동일한 훈련 데이터 세트와 SFT 기본 모델을 사용하지만 각 모델의 강점을 극대화하기 위해 하이퍼파라미터를 다르게 설정하여 학습하였다. 'Cand. 1'과 'Cand. 2'를 Tab. 6에서 'Cand. 1'은 GSM8K 점수는 높지만 다른 작업에서 상대적으로 낮은 점수를 받은 반면, 'Cand. 2'는 GSM8K 점수는 낮지만 다른 작업에서 높은 점수를 받았다. 다양한 방법을 사용하여 이 두 모델을 병합하고 그 결과를 Table 7에 표기하였다.
논문에서는 두 가지 병합 방법을 사용해보았다:
1) 평균(a, b) - 여기서 a와 b는 'Cand 1'과 'Cand. 2'의 가중치를 평균화
2) SLERP(Shoemake, 1985) - 평균(a, b)에는 (0.5, 0.5), (0.4, 0.6), (0.6, 0.4)를 사용
그 결과 다양한 병합 방법이 H6 점수에 거의 영향을 미치지 않는다는 것을 알 수 있다. 개별 과제에 대한 점수 역시 큰 차이가 없어 병합 후보의 강점이 충분히 다르다면 정확한 병합 방법은 그다지 중요하지 않을 수 있음을 시사한다
