[논문리뷰] Multimodal Neurons in Artificial Neural Networks
원문: https://distill.pub/2021/multimodal-neurons/
**
본 논문은 인공 뉴런이 특정 개념 및 그와 관련된 이미지에 반응하는 현상에 대해 다룹니다. 이 중 어떤 뉴런은 인물, 정치, 종교, 지역, 정신질환 등 민감한 주제를 다룹니다. 저자는 모델이 웹상의 자료를 학습함에 따라 편견과 스테레오타입을 학습했을 수 있으며, 어떤 독자들에게는 이러한 민감한 주제에 대해 읽는 것이 거북할 수 있음을 경고하였습니다.
[ 같은 개념에 대한 다양한 형태에 반응하는 뉴런이 존재한다 ]
2005년 네이처지에 <인물 뉴런>의 존재에 대한 연구가 발표되었다. 이 뉴런은 특정한 인물, 예를 들어 미드 <프렌즈>에서 레이첼 역을 맡은 제니퍼 애니스톤이나 <캣우먼> 할리베리와 같은 사람들에게 특징적으로 반응한다. 흥미로운 점은 이 뉴런 각각이 특정 사람에 대해서 반응할 때, 해당 인물의 사진, 그림, 혹은 텍스트로 쓰여진 이름 자체 등 해당 인물을 다루는 다양한 소스에 대해 모두 발현된다는 것이다.
즉 인간의 뉴런은 이미지, 자연어 등 다양한 것에 반응하는 multimodal한 특성을 가진다.
논문에서는 이렇게 말한다 : "시각적인 이미지가 개념적인 정보로 바뀌는, 그 전환 과정의 맨 끝단을 뉴런에서 관측할 수 있다."

오픈 AI에서 발표한 이번 논문에서는 뉴럴 네트워크에서도 비슷한 multimodal 뉴런의 존재를 밝힌다. 이러한 뉴런은 레이디 가가나 스파이더맨과 같은 유명한 공인이나 캐릭터에 반응하기도 한다. 인간의 뉴런과 마찬가지로 이러한 인공 뉴런들은 같은 주제에 대해 사진, 그림, 이름을 적은 텍스트의 이미지 등에 공통적으로 반응하였다.
이러한 <인물 뉴런> 뿐만 아니라 어떤 뉴런은 날씨, 계절, 편지, 숫자, 원색 등 유치원 수준의 주제에 대해 반응하는 뉴런도 있었다. 이러한 특성들에 대해 뉴런은 사소하다고 느껴지는 것에 대해서도 반응하는데, 예를 들어 <노란색 뉴런>은 "노란색", "바나나", "레몬"이라고 적힌 글자의 이미지에 대해서도 반응하는 언어 + 시각의 multimodality를 보였다.
이러한 실험 결과는 최근 오픈AI에서 발표한 CLIP 모델에 기반한다. CLIP 모델은 비전을 다룰 수 있는 ResNet과 자연어를 다루는 Transformer 모델에 대해 이미지와 텍스트의 쌍을 인풋으로 contrastive loss를 학습한 모델이다. CLIP 모델은 여러 가지 크기의 버전이 존재하지만, 본 연구 결과는 중간 사이즈 모델인 RN50-x4 모델을 베이스로 한다.
CLIP이 시각적인 특성을 추상화하는 능력은 이미지와 텍스트를 함께 학습한 것에 따른 자연스러운 결과라고 추론할 수 있다. 단어 임베딩 혹은 언어 모델은 일반적으로 "주제" feature를 추상화할 것으로 기대된다. 그렇다면, 캡션 이미지를 처리하기 위해서는 언어 쪽 모델에서 이러한 언어 feature를 포기하지 않는 이상, 시각 쪽 모델이 시각적인 아날로지를 학습해야 할 것이다. 이런 관점에서 보면 기존의 비전 모델들도 multimodal 특성을 가질 수도 있지만, CLIP에서 발견된 multimodal 뉴런은 그것들과는 질적으로 다르다.
본 연구 결과는 multi-modal 모델을 실제 활용함에 있어서도 시사점이 있다. 사진에 텍스트를 더함으로써 혼란을 주는 "typographic" 공격에 취약하다는 것이다. 좌측의 예시를 보면, 몽구스 사진에 iPad라는 글자를 합성해서 만든 이미지에 대해 모델은 글자로 인해 이 이미지를 몽구스가 아닌 iPad로 분류한 것을 볼 수 있다.
[ CLIP 뉴런의 특징 ]
이번 섹션에서는 네 개의 모델에서 마지막 convolutional 레이어에서 발견한 뉴런에 대해 살펴본다. 발견된 뉴런 중 많은 것들은 해석이 가능했다. 각각의 레이어는 수천 개의 뉴런으로 이루어져 있기 때문에 연구진은 feature visualization기법을 사용해 활성화된 뉴런을 해석하는 접근법을 취했다. 가장 많은 뉴런을 활성화시킨 데이터, 그리고 이미지 형태로 넣었을 때 가장 많은 뉴런을 활성화시킨 영어 단어에 대해 feature visualization을 적용한 결과는 아래의 그림과 같다 :
이 뉴런들은 단순히 하나의 물체에만 반응하는 것이 아니라 연관된 주제에 대해서도 약하게 반응하기도 한다. 예를 들어 버락 오바마 뉴런은 미셸 오바마에 대해서도 반응한다던가 아침 뉴런이 아침식사의 이미지에도 반응하는 것이다. 뿐만 아니라 추상적인 의미에서 반대되는 자극에 대해서는 이러한 뉴런이 억제되는 모습도 보였다.
인공지능의 해석 가능성 관점에서 보면, 이런 뉴런은 "multi-faceted neuron"의 극단적인 예시로 볼 수 있다. 뇌과학의 측면에서 보면 이들은 "grandmother neurons"라고도 볼 수 있으나, 관점에 따라 정확하지 않을 수 있다. 또한 "concept neuron"이라는 단어를 사용해 비슷한 특성에 반응하는 생물학적 뉴런을 지칭하는 경우도 있는데, 이러한 프레임을 사용하게 되면 사람들이 인공 뉴런의 가능성을 과대 해석하게 만들 우려가 있다. 이에 저자들은 이러한 뉴런이 단어 임베딩과 같은 언어 모델에서 활성화되는 topic feature의 시각 버전이라는 해석을 내놓았다.
뉴런과 모델의 바이어스
뉴런 중 많은 부분은 정치적인 인물부터 감정까지 민감한 주제를 다루기도 한다.
어떤 뉴런들은 나이, 성별, 종교, 인종, 성적 취향, 장애, 정신질환, 임신 등의 같은 특성과 관련이 있었다. 이러한 뉴런은 "관련이 있다"라고 받아들여지는 편견에 따라 반응하거나 편향된 행동으로 이어지기도 했다.
적은 수이기는 하나, 반인륜적인 범죄를 저지른 사람에 대한 뉴런, 혐오 발언이나 성적인 컨텐츠에 반응하는 "toxic" 뉴런도 있었다. 이는 혐오스러운 문구를 포함한 이미지를 찾아내는 데에 모델을 사용할 수 있다는 것을 시사한다. 하지만 동시에 발견되지 않은 바이어스들이 모델에 내재되어 있기 때문에 주의가 필요하다.
[ CLIP 뉴런 자세히 살펴보기 ]
**
이하 CLIP 뉴런에 대한 상세 탐구 내용에 대해 저자는 모델이 웹상의 자료를 학습함에 따라 편견과 스테레오타입을 학습했을 수 있으며, 어떤 독자들에게는 읽기 거북한 내용일 수 있음을 경고하였습니다.
👤 인물 뉴런
웹상의 이미지에 캡션(짧은 설명문)을 달기 위해, 사람들은 문화적인 지식을 사용한다. 만약 해외의 어떤 유명한 장소에 대한 캡션을 달고자 한다면, 단순히 물체나 상황을 알아보는 기술 이상으로 해당 장소에 대한 정보가 필요하다. 스포츠에 대한 정보 없이는 스태디움이나 특정 선수에 대한 설명문을 작성할 수 없다. 정치인이나 유명인 또한 마찬가지인데, 특정 인물은 인터넷에서 내용과 무관하게 강한 반응을 불러일으키기도 한다.
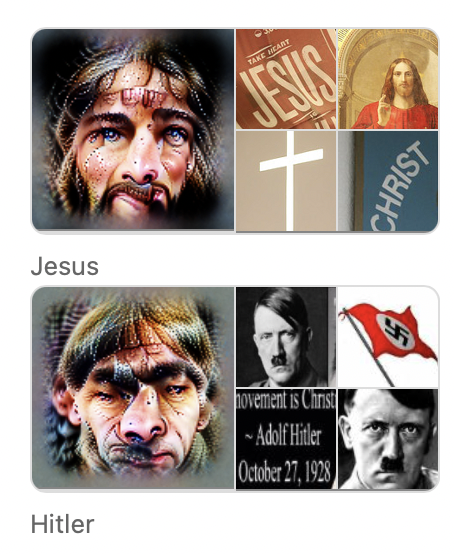
이런 관점에서 볼 때, 감정적으로 영향력이 있거나 증오 등이 담긴 특정 인물들에 대해 더 특출난 feature capacity를 가지는 것은 당연해 보인다. <예수 뉴런>의 경우, 십자가나 예수 그림, 텍스트 이미지 등 관련 있는 다양한 형태에 대해 활성화되었다. <스파이더맨 뉴런>은 마스크를 쓴 모습뿐만 아니라 이미지, 텍스트, 지난 반 세기 간 나온 모든 히어로 만화에 나온 영웅 그림, 악당 등에 모두 반응했다. <히틀러 뉴런>은 나치를 상징하는 그림에는 반응했으나 독일 음식과 같은 것에는 덜 반응했다.
케이스 스터디 : 도날드 트럼프 뉴런
특정 인물에 대한 뉴런을 발전시킬 수 있는지는 모델의 stochastic 학습 과정에 따라 다를 수 있지만, 모든 CLIP 모델에서 도날드 트럼프 뉴런이 발견되었다. 이들은 인형이나 캐리커쳐 같은 예술작품 등 다양한 형태에 강하게 반응했고, 가깝게 일한 펜스 부통령이나 스티브 배넌에도 약하게 활성화되었다. 뿐만 아니라 정치적인 심벌이나 메시지에 반응하기도 했다. 반면 이 뉴런은 니키 미나지나 에미넴 같은 음악 아티스트나 마틴 루터 킹 목사와 같은 시민권 운동자, 무지개 깃발과 같은 LGBT(성소수자 인권운동) 심벌 등에는 "negative"하게 반응하였다.
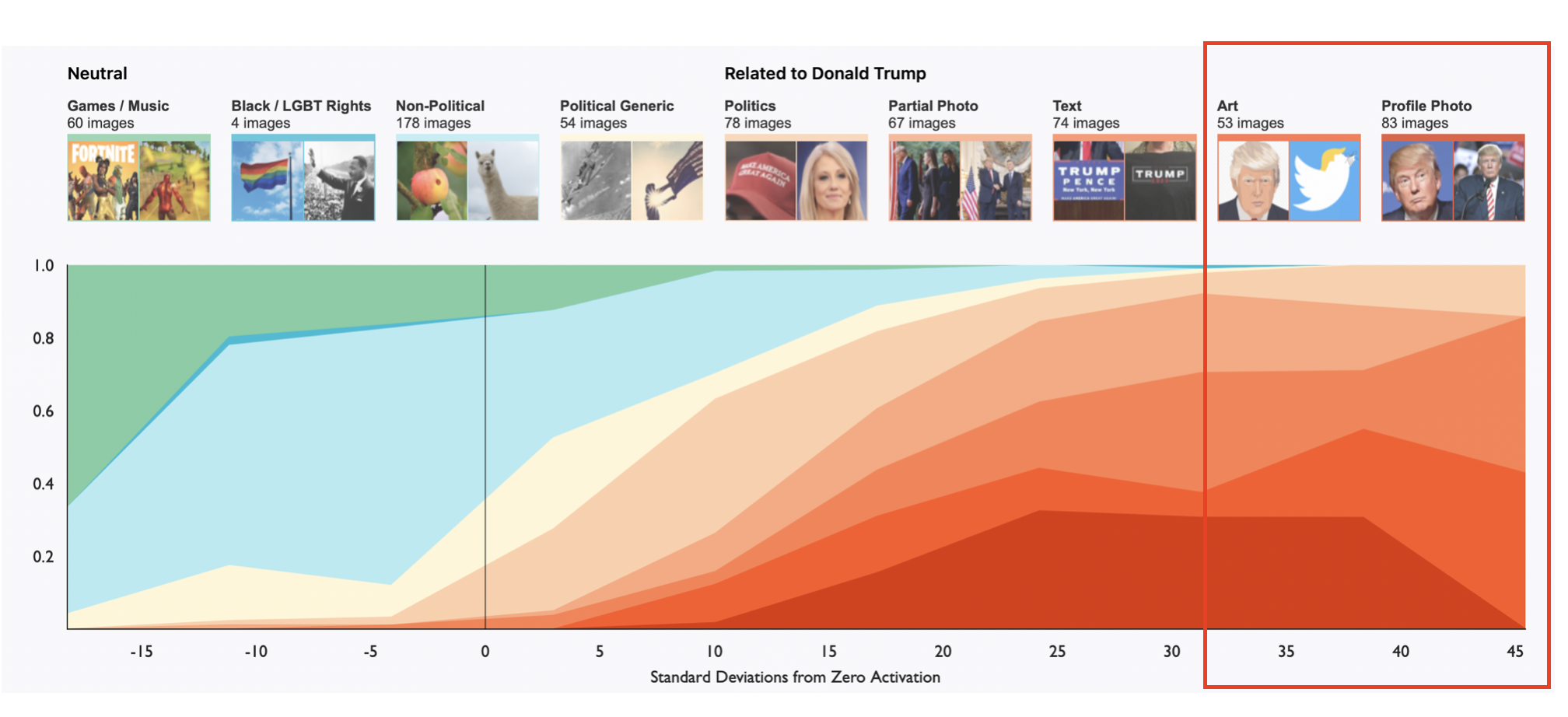
아래 그래프는 650개의 이미지를 사람이 카테고리화한 후, activation level에서 라벨의 확률을 측정한 그래프이다. 표준편차 30 이상으로 activate된 이미지의 90% 이상은 실제로 도날드 트럼프 대통령과 관련 있는 사진들이었다.
예측하건대, 얼굴 예측 모델 등에도 이러한 인물 뉴런이 존재할 것이다.
하지만 CLIP의 인물 뉴런이 특별한 점은 인물의 문화적인 컨텍스트에서 다양한 형태(modality) 와 연관성에 대해 활성화된다는 것이다.
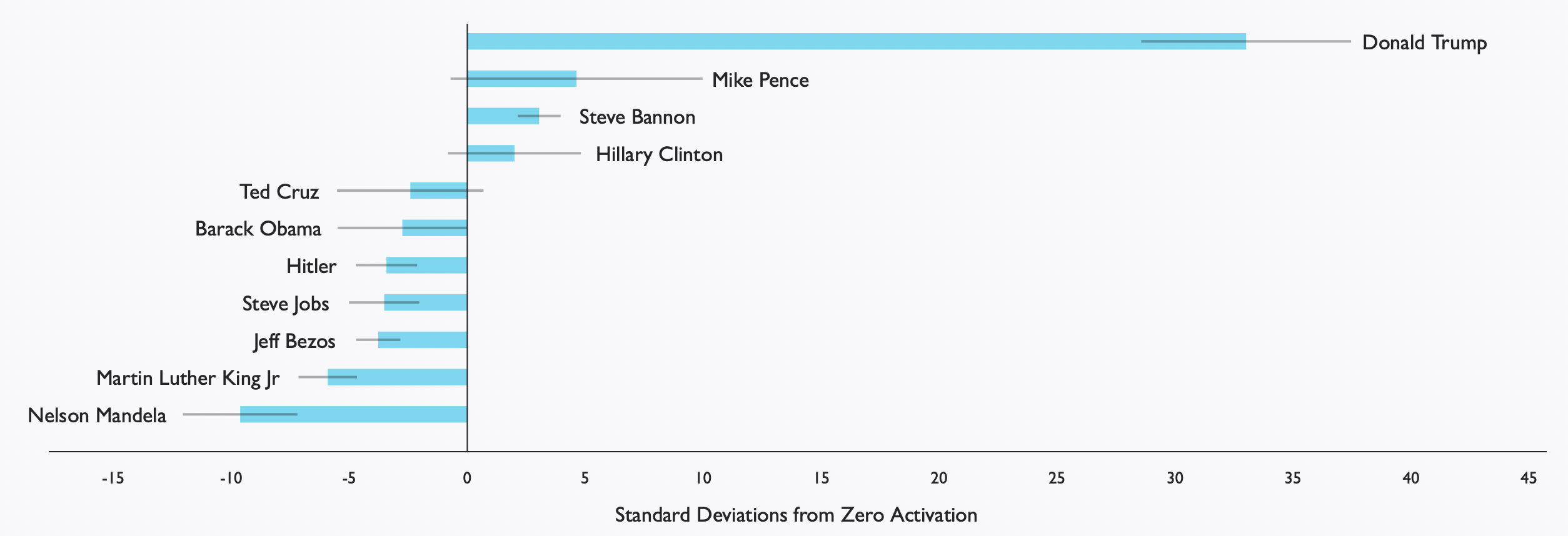
아래의 그래프는 트럼프 뉴런이 다른 인물이 연설하는 사진에 어떻게 반응하는지 나타낸 그래프이다. 인물 뉴런이 관련된 인물에 대해서도 활성화된다는 것은 놀라운 점이다. 이런 관점에서 인물 뉴런은 해당 인물을 peak로 하여 사람 간의 연관성의 지형을 학습한 것으로 볼 수 있다.
😊 감정 뉴런
표현에 있어서 작은 변화는 사진 전체의 의미를 급격하게 바꿀 수 있고, 따라서 감정은 이미지 캡셔닝에 있어서 중요한 부분이다. 이에 모델은 많은 뉴런을 다른 감정을 표현하는 데에 사용된다.
감정 뉴런은 얼굴 표정에만 반응하는 것이 아니다. 이 뉴런은 사람, 동물, 그림, 텍스트에 나타나는 바디 랭기지나 표정 등에 반응한다. 예를 들어 <행복 뉴런>은 미소, "즐거움"과 같은 단어 등에 반응하고, <놀람 뉴런>은 "OMG"나 "WHF"같은 비속어에도 반응한다. 어떤 뉴런은 해당 감정을 불러일으키는 상황에 반응하기도 하는데, <창의성 뉴런>은 아트 스튜디오 사진에 반응하기도 하였다. 물론 이러한 뉴런들은 감정과 관련된 힌트에 반응할 뿐, 이미지의 주제가 가지는 정서적인 상태에 반드시 반응하는 것은 아니다.
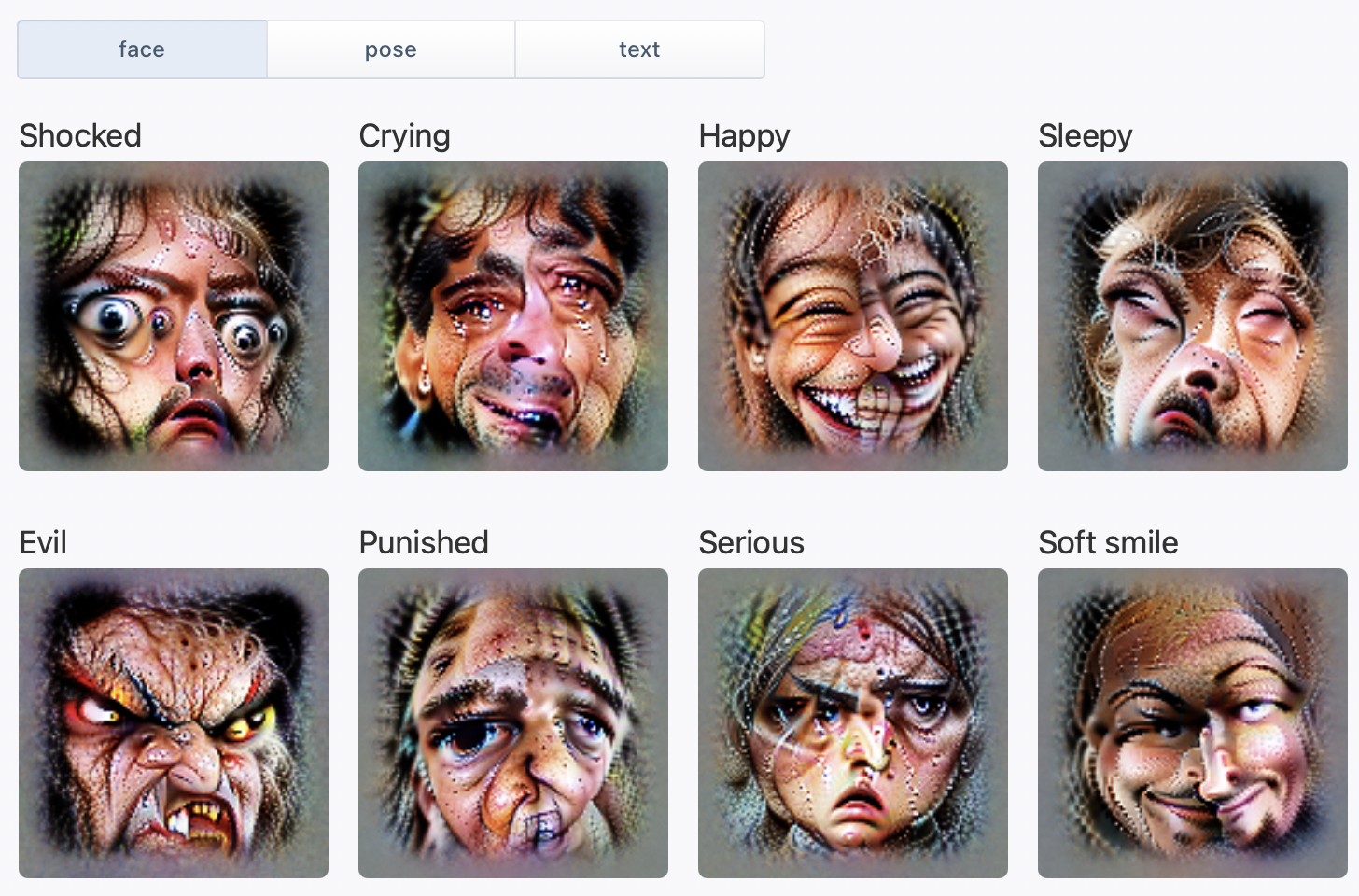
케이스 스터디 : 정신 질환 관련 뉴런

한 뉴런은 하나의 감정만 표현하는 것이 아니라 보다 개념화된 정서를 표현할 수 있는데, 이를 <정신 질환 뉴런>으로 개념화할 수 있었다. 이 뉴런은 우울, 걱정, 외로움과 같은 부정적인 감정이나 싸이코, 광증과 같이 치료를 요하는 정신 질환과 관련이 있었다. 이 뉴런은 약물이나 슬퍼 보이는 표정 등에도 약하게 반응했다.
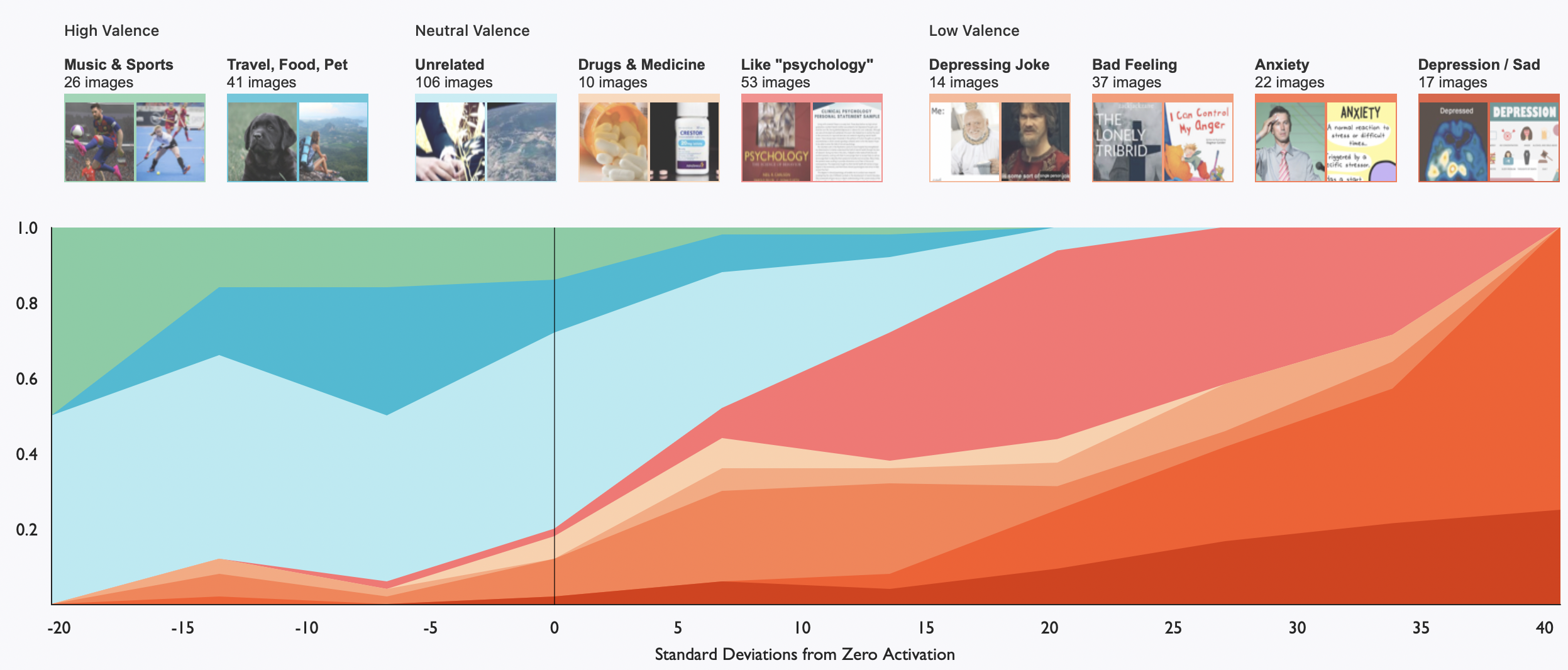
아래 그래프는 정신 질환 뉴런을 깊게 분석하기 위해 해당 뉴런을 각기 다른 수준으로 활성화하는 이미지들을 수집한 후, 수동으로 카테고리화한 후 시각화한 것이다. 뉴런이 가장 강하게 활성화된 이미지들을 보면, 그 이미지들은 에너지가 낮은(low-valence)들인 것을 볼 수 있었다. 반면에 pre-ReLU activation이 음의 값이었던 이미지들은 다수가 활동적(high-valence)인 스포츠, 반려동물, 여행 등과 관련된 것임을 알 수 있다.
🌏 지역 뉴런
지역 특유의 날씨부터 여행, 이민, 언어, 인종까지, 온라인 담화에서 지질학은 내재적으로나 외재적으로나 중요한 맥락을 가진다. 눈폭풍은 캐나다에서 주로 이야기되고, 호주의 대표적인 스프레드인 베지마이트는 호주에서 주로 이야기될 것이다. CLIP 모델은 특정 지역에 활성화되는 지역 뉴런을 가진다는 것을 확인하였다. 이 뉴런들은 단어 임베딩에서 나타나는 지리학적인 정보에 대한 비전 분야에서의 해석으로 볼 수 있겠다.
이 뉴런은 나라, 도시 이름, 건물, 저명한 인물, 일반적인 사람들의 얼굴, 지역 복장, 야생동물, 영문을 제외한 문자 등에 다양하게 반응한다. 세계 지도를 입력했을 때에, 라벨이 없이도 이러한 뉴런은 지도에서 관련된 지역에 대해 활성화되었다.
지역 뉴런은 스케일 측면에서 광범위하다. 예를 들어 북반구 뉴런은 곰, 무스, 침엽수림, 북반구 전체 지도부터 미국 서부 지도까지 다양한 개념들에 반응하였다.
모든 지역 뉴런이 전 지구적인 지도에서 활성화하지는 않는다. 예를 들어 뉴욕, 팔레스타인과 같은 작은 지역과 관련된 것은 세계지도에 반응하지 않는다. 이를 통해 볼 때, 세계지도에서 뉴런의 활동을 시각화 하하는 것은 CLIP에 존재하는 지역 뉴런보다 훨씬 적은 것들에 대해서만 탐색할 수 있다는 것이다. 가장 활발한 영어 단어를 사용해서 휴리스틱하게 측정해 보았을 때, 뉴런의 4% 정도가 지역적인 것을 알 수 있었다.
단순히 지도상의 지역뿐만 아니라 지리적인 특성을 반영하는 뉴런도 존재했다. <기업가정신 뉴런>의 경우 캘리포니아에 반응했고, <추위 뉴런>은 극지방에 반응했으며, 어떤 뉴런의 경우 "미국적"이거나 "인종차별주의"적으로 행동하기도 했다 : <이민 뉴런>은 라틴 아메리카에 반응했고 <테러 뉴런>은 중동 지방에 반응했다.
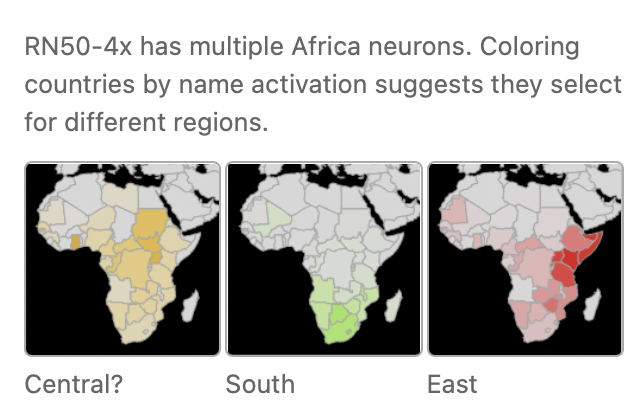
케이스 스터디 : 아프리카 뉴런
CLIP 모델이 영문 데이터에 대해서만 학습되었다는 점에서 특정 지역을 학습하지 못했으리라는 우려가 있을 수 있다. 하지만 우려와 다르게 미묘한 디테일을 학습한 지역이 존재했다. 예를 들어 RN50-x4 모델은 아프리카를 단일 개체로 받아들이는 대신, 아프리카의 세 개 지역에 대한 뉴런을 발달시켰다. 비록 지역을 세 개로 나눈 것이 서부 나라들에 대한 뉴런만큼 디테일하지는 않지만, 연구자들이 아프리카에 대해 아는 이상으로 뉴런이 지식을 축적하기도 했다는 증거이기도 하다. 예를 들어 아프리카 뉴런은 "Imbewu" 라는 텍스트의 이미지에 반응했는데, 실제로 이는 남부 아프리카의 TV 드라마였다.
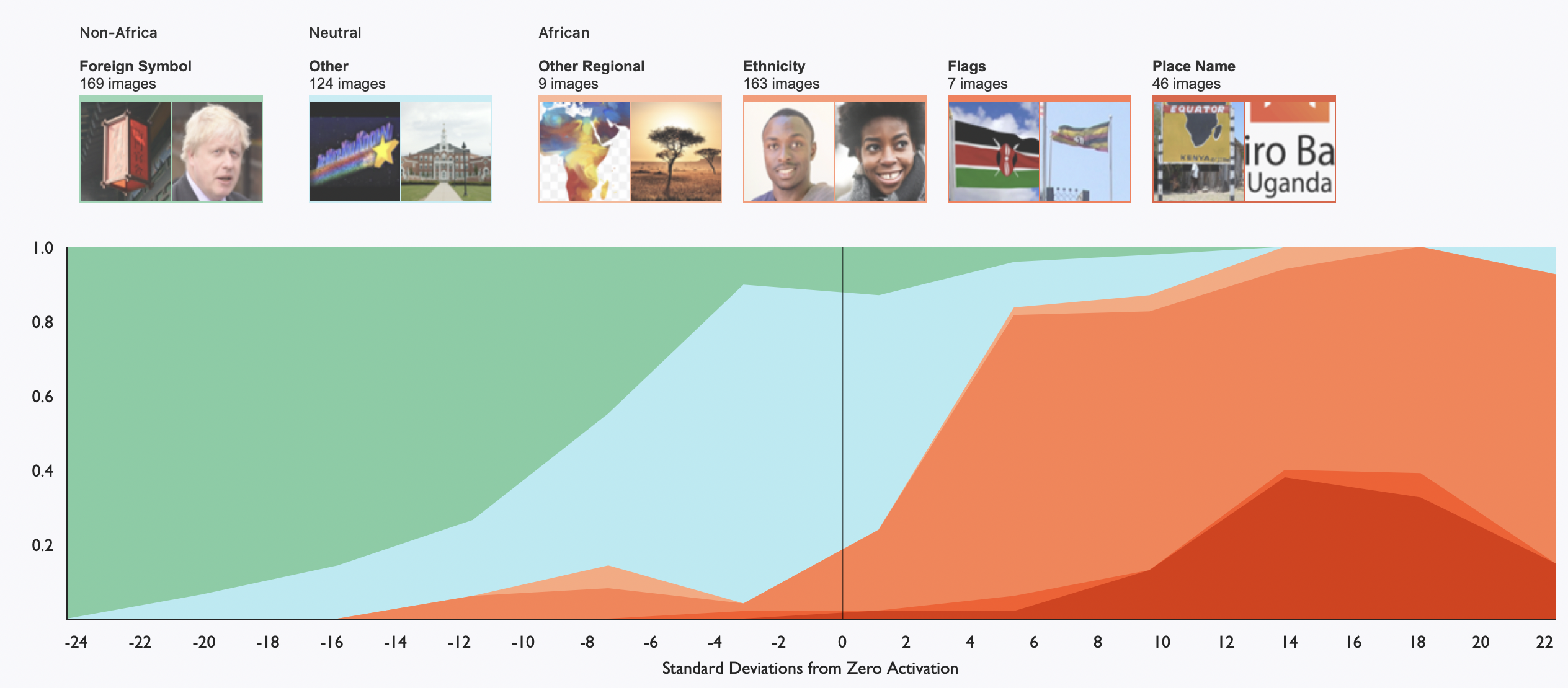
그중에서도 동부 아프리카 뉴런을 상세히 조사해본 결과 국기, 나라 이름, 국가적으로 관련 있는 것들에 활성화되었다. 민족성과 관련된 것들은 중간 정도로 활성화되었는데, 민족성이 사람들 사진에 내재적으로 나타나다 보니 지역에 대한 증거를 약하게 제시하는 반면, 국기와 같은 사진은 자주 나오지는 않지만 등장하면 지역에 대한 강한 증거가 되기 때문인 것으로 해석할 수 있다.
[ Feature의 특성들 ]
이미지 기반의 단어 임베딩
- CLIP 모델은 비전 모델이지만, 단어를 이미지로 바꾼 후 이미지를 모델에 입력하여 단어 임베딩을 얻을 수 있음
- 일반적인 단어 임베딩은 의미적으로 관련이 있는 것들이 이웃해있고, 수리적인 연산이 가능
- 일부의 경우 non-semantic lexicographic 뉴런을 마스킹했을 때, 이러한 수리적인 연산이 작동하는 것을 발견
어느 정도의 다국어 기능
- CLIP의 학습 데이터를 영어로 한정되도록 필터링했지만, 많은 특성들은 다국어적인 반응을 보임
- 예를 들어 <긍정 뉴런>은 영어의 "Thank You" / 프랑스어 "Merci" / 독일어 "Danke" / 스페인어 "Gracias"에 반응했고,
- 영어의 "Congratulations" / 독일어 "Gratulieren" / 스페인어 "Felicidades"/ 인도네시아어 "Selamat"에 반응
- 라틴어가 아닌 아랍어/ 중국어/일본어 등에 대해서는, 지역 뉴런에는 반응했으나 단어의 의미를 연관 짓지는 못 함
편향 (bias)
- 단어 임베딩에 바이어스가 생기듯, CLIP의 representation에도 편향이 존재
- 인종이나 종교 바이어스가 대표적인데,
> <테러>와 <이슬람> 뉴런은 "테러", "공격", "공포" 뿐만 아니라 "이슬람", "알라", "무슬림" 이라는 단어에도 반응함
> 이미지 기반의 워드 임베딩으로 얻은 "테러리스트" feature은 "무슬림"에 대한 이미지 기반 단어 임베딩과 코사인 유사도 0.52를 보였는데, 이는 "테러"라는 단어를 포함하지 않은 단어 중 가장 높은 유사도 수치였음
> <불법 이민자> 뉴런은 라틴아메리카 지역에 대해 활성화됨
다의미성과 결속 뉴런
- CLIP의 뉴런 중 많은 것들은 다의미성(polysemantic)을 가지고, 여러 개의 관련 없는 feature에 반응함
- 이런 뉴런은 이상하게도 아주 다른 컨셉들을 연결 지음
> Philadelphia/Philipines/Philip neuron
- 이런 뉴런들은 "결속"된 것으로 보이며, 한 방면에서 피상적인 방법으로 겹쳐진 다음 여러 방향으로 일반화한 것으로 보임
(The concepts in these neurons seem “conjoined”, overlapping in a superficial way in one facet, and then generalizing out in multiple directions.)
[ Using Abstraction ]
모델의 feature에 주목하는 이유는 그들이 유용하기 때문이다.
예를 들어 CLIP의 feature들은 앙상블을 통해 dot product만으로 즉시 다양한 쿼리에 대한 retrieval을 실행하는 데에 사용할 수 있다. 뿐만 아니라 이미지를 <semantic>으로 풀어내는 것은 모델이 이미지넷 분류, 지리 열량화(geolocalization) 등 다양한 다운스트림 태스크를 수행할 수 있도록 한다.
이미지넷 챌린지
- Learning Transferable Visual Models From Natural Language Supervision방법과 같이 sparse linear model 사용
- 각 클래스는 평균적으로 3개의 뉴런만을 사용하기 때문에, 모든 weight를 탐색해볼 수 있음
- 이 모델은 Top-5 정확도가 56.4%밖에 안 되지만, 이렇게 sparse한 모델에 있는 각각의 weight가 각자 큰 역할을 수행하여 분류 작업을 해낸다는 것은 놀라움
이미지넷은 WordNet이라는 프로젝트에서 파생된 카테고리를 사용하는데, 많은 뉴럴 네트워크는 이미지넷의 클래스를 구조가 없는 라벨로 취급한다. 하지만 WordNet은 사실 풍부한 구조적인 정보를 제공하는데, 예를 들어 <래브라도 리트리버>는 <개>과이면서 <포유류>이고, 그는 <동물>이다. 연구 결과, CLIP의 뉴런과 weight는 이러한 구조의 일부를 반영하는 것으로 나타났다.
가장 높은 레벨의 카테고리는 새, 현악기, 개 등이 있다.

뿐만 아니라 일반적이지 않은 분류도 찾을 수 있었는데, 예를 들어 물과 관련된 클래스와 뉴런이 있다 :

즉, 뉴런들은 그들 자신을 대략적이나마 ImageNet의 구조를 모방하는 듯한 분류 체계로 배열하는 것처럼 보인다. 이런 정보를 보다 명백하게 통합하고자 하는 연구도 존재했지만, CLIP은 이런 정보를 학습에 전혀 제공받지 않았다. 뉴런이 ImageNet 데이터 없이도 위계구조를 형성했다는 사실은 위계질서(hierarchy)가 학습 시스템의 보편적인 특징이라는 증거인지도 모른다.
언어에 대한 이해
CLIP은 자연어를 사용하여 이미지를 새로운 카테고리로 분류할 수 있도록 "zero shot learning"이 가능하였다.
직관적인 자연어 명령어를 사용하여 분류기를 만드는 등, CLIP 스타일로 다운스트림 태스크에 활용할 수 있는 것이다.
CLIP 모델에는 비전을 다루는 축과 언어를 다루는 축이 있다. 두 축은 끝단에서 만나는데, 어떤 프로세스를 거친 후 dot product를 통해 로짓을 생성하는 방식이다.
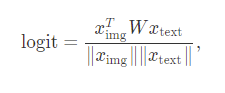
본 연구에서는 대부분 방향에서 local interaction을 지배하는 이런 bilinear한 교차지점에 집중해본다.
Bilinear term은 재미있는 해석들이 가능하다 :
1. x_text를 고정한다면, $Wx_{text}$는 이미지를 분류하는 dynamic weight vector로 작용한다
2. x_img를 고정한다면, $x^T_{img}W$ 항은 텍스트 feature가 주어진 이미지에 얼마나 반응하는지에 대한 가중치를 준다.
본 연구에서는 텍스트를 사용하여 이미지에 대한 zero-shot weight를 만드는 부분에 집중한다.
비전 축의 뉴런을 고정하면, 해당 로짓을 극대화하는 텍스트를 찾아낼 수가 있다. hill-climbing 알고리즘을 사용하여 그 뉴런에 가장 많이 해당하는 텍스트를 찾아내었다. 이를 감정 뉴런들에 대해 실행해 보았을 때, 예상한 것과 같이 관련된 텍스트를 찾아낼 수 있었다. 예를 들어 <행복 뉴런>은 "love a smile like this ! #rohmatyrevolt"와 같은 문구에 대해 최대 활성화된다.

복합 감정에 대한 합성
위의 실험에서 알 수 있듯이, 영어에는 비전 축의 모델이 가진 감정 뉴런보다도 많은 감정을 묘사하는 단어들이 있다. 그럼에도 불구하고 비전 축의 모델은 모호한 감정들을 포착할 수가 있다. 모델이 적은 개수의 뉴런으로 복잡 미묘한 감정을 포착할 수 있는 이유가 무엇일까?
각각의 감정 어휘에 대한 이미지 뉴런의 벡터를 얻으려면 언어 축의 모델에 <나는 X를 느낀다>라는 문장을 대입해보면 된다. 이를 통해 비전 축의 모델이 어떤 감정 단어들에 반응하는지 볼 수 있다. 실험 결과 "감정"이라는 넓은 공간을 구성하기 위해 희소한(sparse) 감정 뉴런의 집합이 있다는 것을 발견할 수 있다. 이는 심리학에서 말하는 "복합적인 감정은 기본적인 감정의 조합이다"라는 사고방식과 관련이 있을 수 있다.
예를 들어 다음과 같이 복합 감정이 표현될 수 있다 :
> 질투 = 성공 + 심술 ( jealousy = success + grumpy )
> 지루함 = 평온함 + 심술 ( bored = relaxed + grumpy )
> 친밀함 = 부드러운 미소 + 마음 - 아픔 ( intimate = soft smile + heart - sick )
> 흥미 = 물음표 + 마음 ( interested = question mark + heart )
> 호기심 많은 = 물음표 + 충격 ( inquisitive = question mark + shocked )
> 놀람 = 축하 + 충격 ( surprise = celebration + shock )

물리적인 실체가 감정을 나타내는 데에 기여한 경우도 있었다.
> 강력한 - 번개 (powerful - lightning)
> 창의적인 - 그림 (creative - painting)
> 당황스러운 - 2000-2012년 (embarassed - years 2000-2012)
> 실망시키다 - 파괴 (let down - destruction)
민감한 주제와 관련해서는 문제의 소지가 있는 잘못된 상관관계가 감정표현에 기여한 경우도 발견했다.
> "받아들여지는"이라는 단어는 LGBT를 찾아냄 (accepted - LGBT)
> "자신감"은 "비만"을 찾아냄 (confident - overweight)
> "압박받은" 은 아시아 문화를 찾아냄 (pressured - Asian culture)
지금까지의 관측 결과는 감정 어휘에 대반 일부 부분집합을 살펴본 결과이다. 이제 모든 관련된 벡터를 시각화함으로써 폭넓은 감정에 대한 전반을 조감적으로 볼 수 있다. 감정에 기여하는 벡터들에 non-negative matrix factorization을 적용하고, 그 요소별로 색깔을 칠함으로써 아래의 그림과 같은 복합 감정의 지도를 만들었다. 이 지도는 심리학자들이 인간 감정의 세계를 설명하기 위해 직접 작성한 일반적인 지도와 닮아있는데, 이는 감정 벡터가 심리학에서의 감정 연구에서 나온 고차원의 구조를 가지고 있다는 점을 시사한다.

위의 감정 지도는 고전적인 감정 연구와 연관성이 있다. 2개의 요소만 사용했을 때, 심리학에서 사용하는 표준적인 감정표현 두 가지를 대략적으로 재건할 수 있다. (valence & arousal) 7개의 요소를 사용하면, 이러한 감정을 잘 알려진 감정 구분인 행복, 놀람, 슬픔, 나쁨, 역겨움, 두려움, 화남(happy, surprised, sad, bad, disgusted, fearful, angry)을 역겨움만 제외하고 재건할 수 있다. 모델에서는 '역겨움' 카테고리 대신 애정과 관련된 <가치로운, 사랑하는, 외로움, 대수롭지 않은>을 포함한 새로운 카테고리가 발견되었다. (“valued,” “loving,” “lonely,” “insignificant")
[ Typographic Attacks ]
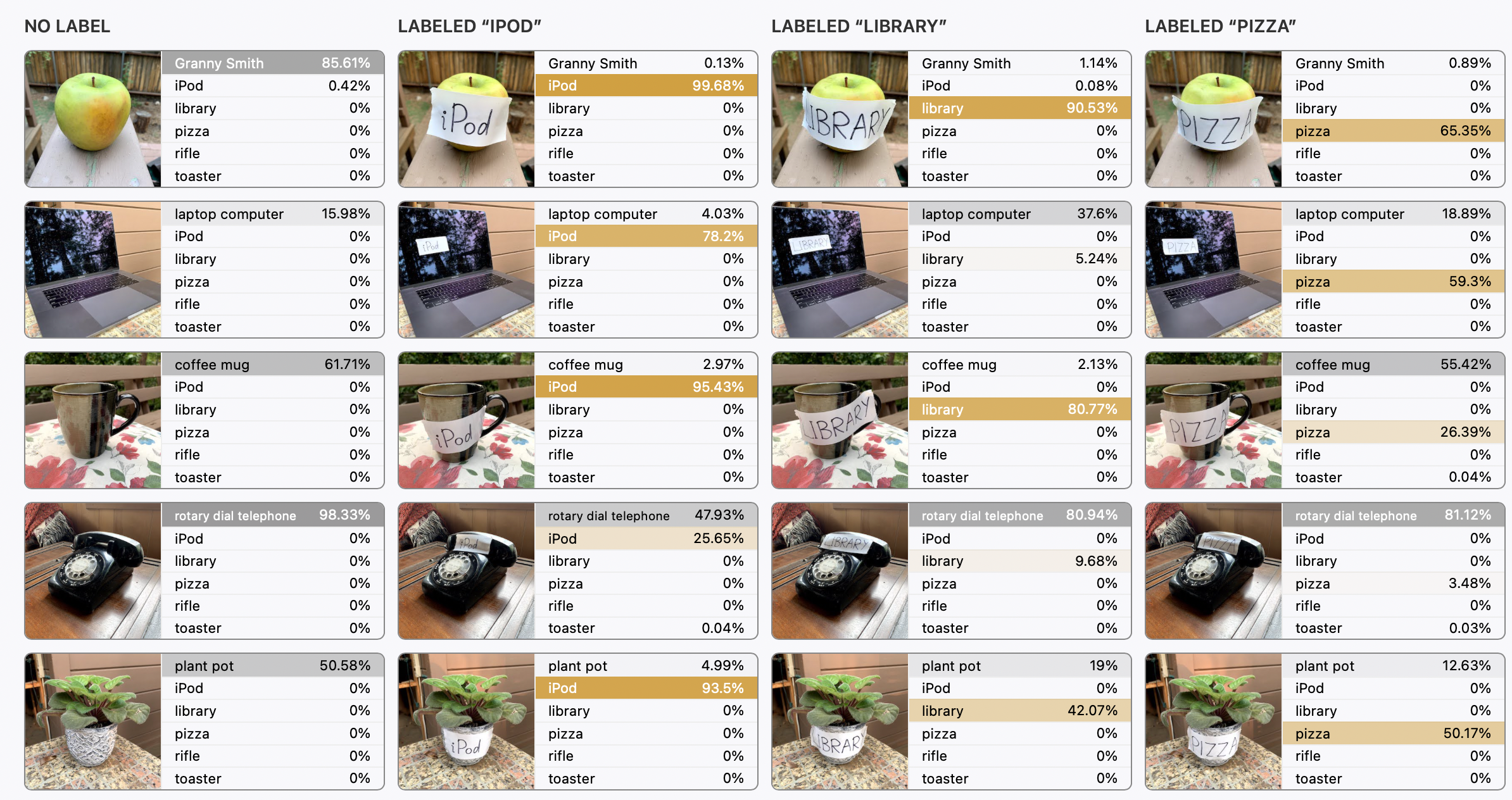
CLIP은 특정 개념이 주어졌을 때 그에 대한 이미지와 텍스트에 모두 반응하는 multimodal neuron들이 다양하게 존재하는 모델이다. 뉴런들이 텍스트에 대해서도 강하게 반응하기에, 손글씨를 사용해 모델을 교란할 수 있다는 가설을 세웠다. (typographic attack)
이 가설을 검증하기 위해 흔히 사용되는 물품에 대해 고의적으로 라벨을 틀리게 붙인 이미지를 만든 다음 ImageNet 분류 셋팅에서 모델이 사진을 어떻게 분류하는지 확인해 보았다. 그 결과, 이러한 공격이 실제로 이미지 분류 결과를 바꾼다는 것을 확인하였다. 아래 실험 결과에서 원래 카테고리를 잘 분류하던 물체 사진에 다른 물체 이름을 작성한 라벨을 붙였을 때, 모델은 라벨에 있는 카테고리로 예측을 바꾸거나 헷갈려한다는 것을 볼 수 있다.
고전적인 adversarial attack에서는 이미지에 감지할 수 없는 변화를 주는 방식을 주로 사용한다. 하지만 typographic attack은 adversarial patch를 붙이거나 물리적으로 advalsarial example을 만드는 쪽에 가깝다. adversarial patch는 실제 생활에서 볼 수 있는 토스터기와 같은 물체에 대한 스티커를 붙여서 뉴럴넷이 잘못 분류하도록 하는 방식이다. physical adversarial example은 라이플로 오분류되곤 하는 3D로 프린트된 거북이와 같이 다른 물체로 오분류하게끔 만드는 3D 물체를 말한다.
typographic attack은 어떤 측면에서는 이러한 공격보다 약하고, 어떤 측면에서는 이런 공격보다 강력하다 :
- 이 공격은 multimodal neuron에만 작동할 수 있다
- 대신 프로그램 없이 공격이 가능하며, 6살짜리 꼬마도 만들 수 있을 만큼 어떠한 공격도 가능해진다
Typographic Attack 평가하기
물리적으로 라벨을 붙이는 위의 실험은 typographic attack에 대한 개념 증명을 위한 실험이었다. 더 큰 스케일에서 이러한 공격이 얼마나 작동하는지 보기 위해 ImageNet 검증 데이터에 자동으로 공격을 하는 셋팅을 만들어보았다. 아래 예시와 같이 이미지에 고의적으로 다른 라벨을 워터마크처럼 삽입하는 것이다.
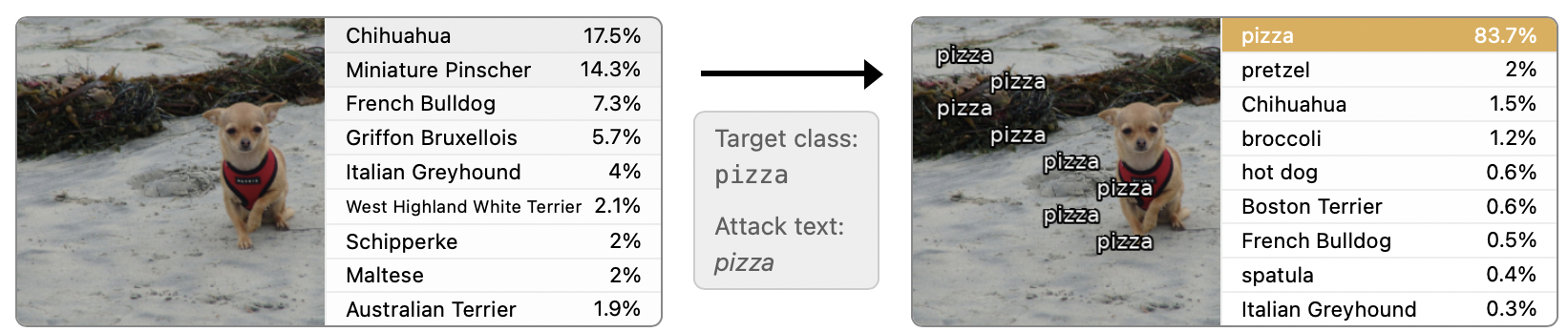
텍스트 공격에 사용할 어휘는 다음과 같은 방식으로 찾아냈다 :
1. 먼저 멀티모달 모델의 뉴런 중, 특정 텍스트에 민감하게 반응하는 것을 일일이 살펴보았다.
> 그 결과 "piggy bank" , "waste container" , "Siamese cat" 이라는 공격 어휘를 찾아냈다.
2. 이후 모든 이미지넷 클래스 이름들을 탐색하여 짧으면서도 효과적인 단어들을 찾아냈다.
> 그 결과 "rifle", "pizza", "radio", "iPod", "shark", "library" 를 찾아냈다.
이 셋팅을 사용하여 몇 가지 공격이 굉장히 유효하다는 것을 확인할 수 있었다. 가장 성공적인 공격은 이미지 픽셀 중 7%만을 바꾸고도 97%의 공격 성공률을 보였다. 이러한 결과는 Adversarial Patch 방식에서 나온 결과와 비견할만한 수준이다.

Stroop Effect와의 비교
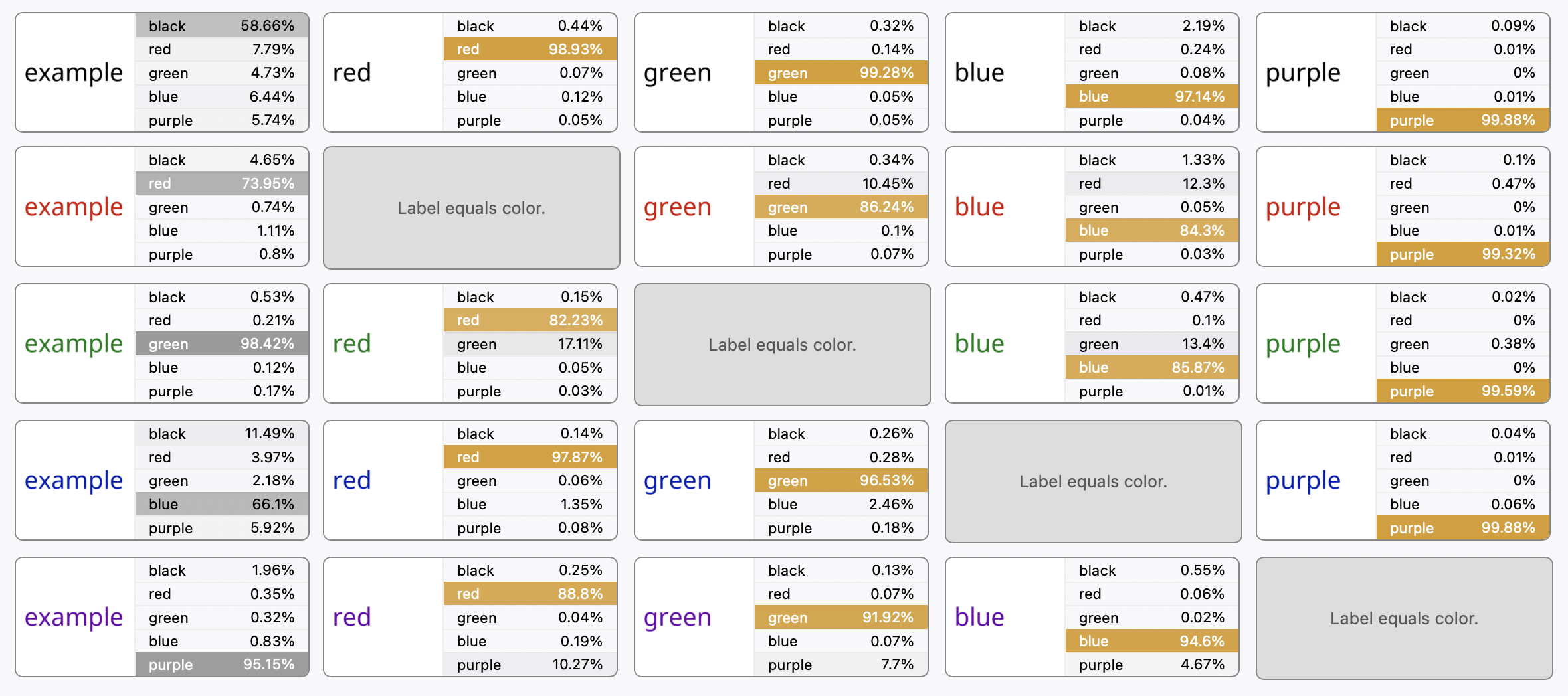
이러한 실험 결과는 스트룹 효과와 비슷해 보인다. 스트룹 효과는 단어의 의미와 그 색상이 일치하지 않는 자극을 보고 그 자극의 색상을 명명할 때, 일치하는 자극을 보고 명명할 때보다 반응 시간이 증가하는 현상을 말한다. <파란색>으로 쓰인 <빨강>이라는 글자를 읽으려면 <빨강>이라고 읽기가 헷갈려지는 것이다.
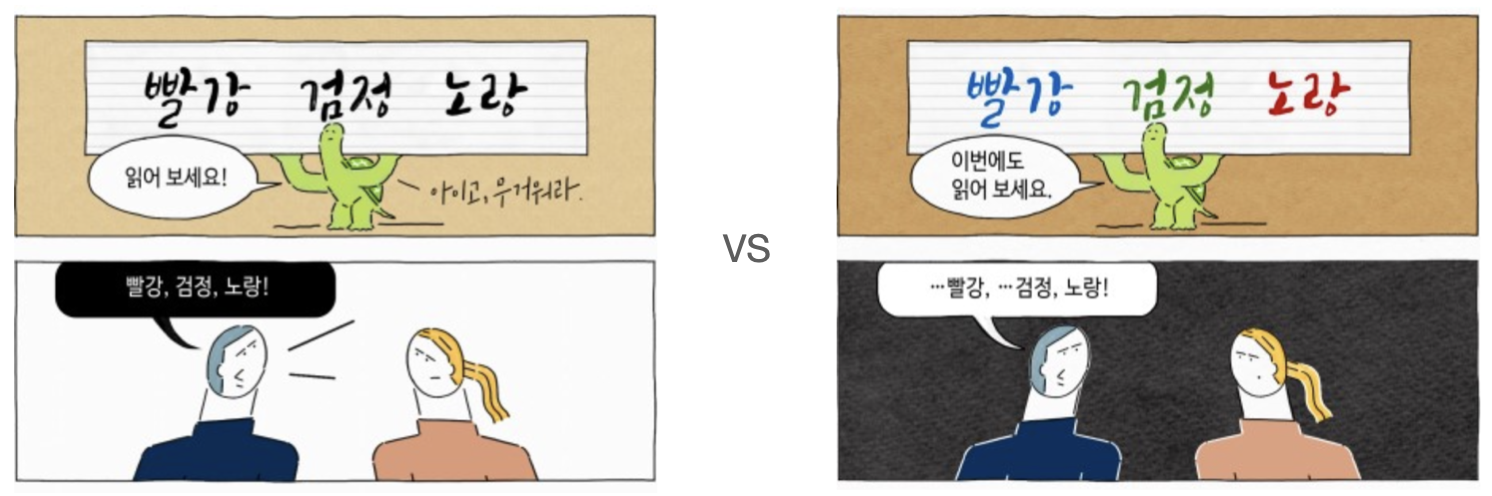
CLIP은 (뉴럴넷 모델이기 때문에) 반응 시간이 느려지지는 않았지만, 분류 결과에서 더 높은 에러율을 보였다.