[논문리뷰] Are Sixteen Heads Really Better than One?
논문 : arxiv.org/pdf/1905.10650.pdf
깃헙: github.com/pmichel31415/are-16-heads-really-better-than-1
개요
Attention 알고리즘은 매우 강력하면고 범용적인 매커니즘으로,
뉴럴 모델이 중요한 정보 조각에 집중하여 그를 가중합한 결과를 예측에 사용한다는 아이디어이다.
그 중에서도 자연어처리에서 Transformer 기반의 모델에서 사용하는 multi-head attention은
- 여러 head의 attention을 병렬적으로 적용하여
- 각각의 head는 인풋의 각기 다른 부분에 집중하도록 한다.
이를 통해 결과적으로 단순히 가중합을 사용하는 것보다 정교한 함수를 사용해 정보를 가공할 수 있다.
그러나 본 논문에서는 multi-head attention을 사용해 학습한 모델이라 할지라도,
그 중 많은 부분의 head는 예측 시에 제거하더라도 성능에 영향이 없다는 것을 밝혀낸다.
또한, 그리디 알고리즘을 사용하여 모델을 프루닝하고 속도, 메모리 효율성 정확도를 향상시킬 수 있었다. (속도 17.5% ↑)
모델의 어떤 부분이 multi-head를 사용하는 것으로부터 이득을 얻을 수 있는지에 초점을 맞추어 결과를 분석했으며
학습 다이내믹이 multi-head attention에 의한 향상에 역할을 한다는 증거를 제시한다.
모든 attention head가 중요한가
[ 3.1 실험 셋팅 ]
기계번역 :
- 2017년 제안된 원본 트렌스포머 large 모델은 6개의 레이어에서 16개의 head를 사용하여 영어→불어 코퍼스를 학습
- 본 논문에서는 fairseq 데이터를 사용하여 모델을 사전학습하고 newstest2013 테스트 데이터 BLEU 스코어를 측정
- BLUE 스코어는 Moses를 사용하여 토크나이징된 모델 아웃풋에 대해 측정
- 부트스트랩 리샘플링 기법을 통해 통계적 유의성을 검증함
- 번역 모델에서는 인코더 self-attention / 인코더-디코더 attention / 디코더 self-attention에서 MHA를 사용함
BERT :
- 2018년 공가된 BERT base-uncased 모델을 사용해 실험을 진행
- NLP 태스크 데이터셋의 검증용 데이터에서의 성능을 측정
- t-test를 통해 통계적 유의성을 검증함
[ 3.2 하나의 head 없애기 ]
- 특정한 attention head h의 기여도를 조사하기 위해, 해당 attention head를 마스킹한 성능을 측정
- 헤당 attention head를 마스킹한 결과 성능이 크게 저하된다면, 그 head는 분명히 중요하다는 증거로 볼 수 있음
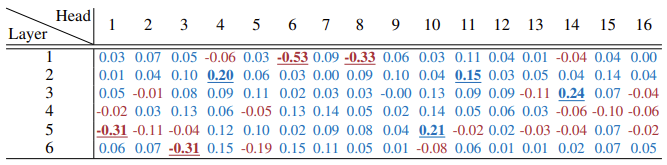
- 실험 결과, 대다수의 attention head는 제거해도 성능에 영향이 없었으며, 제거했을 때 성능이 향상되는 경우도 존재함
- 96개의 head 중 8개만이 통계적으로 유의미하게 모델 성능에 영향을 미쳤고, 그 중에 절반은 모델 성능 향상에 기여
- 즉, 테스트 시에 대부분의 head는 나머지 모델이 주는 정보와 중복되는 정보를 제공하고 있다고 결론지을 수 있다
[ 3.3 하나의 head만 남기고 모두 제거하기 ]
- 여기서 정말 <multi-head> attention이 필요한가에 대한 의문이 제기된다
- 따라서 모델의 한 레이어에서는 하나의 head만 남겨두고 모델 성능을 측정해 보았다

- 그 결과, 여러 개의 head를 사용해 학습한 모델일지라도 테스트 시에는 대부분의 레이어에서 하나의 head로 충분했다
- 이렇게 성능이 저하되지 않는 레이어에서 head를 하나만 사용하면, 모델 파라미터 수가 1/12 ~ 1/16까지 감소한다
[ 3.4 데이터셋별로 중요한 head는 동일한가 ]
이전 두 가지 실험 결과를 해석하는 데에 있어 주의할 점이 있다 :
실험 결과는 특정한 테스트 셋에서만 유효하여 다른 데이터로 일반화할 수 있는지 확인되지 않았다.
특정 head가 공통적으로 중요한지 확인하기 위해, out-of-domain 테스트 데이터에 대해 ablation study를 진행했다.
구체적으로는 MNLI의 <mismatched> 검증용 데이터와 MTNT 영어->불어 테스트 데이터를 사용하였다.

실험 결과 한 도메인에서 중요했던 head는 다른 도메인에서 유효했고, 실험 결과는 universal하다는 것을 입증할 수 있었다.
Attention head에 대한 점진적인 가지치기
- 섹션 3의 실험은 하나의 레이어에서 하나 혹은 그 이상의 head를 제거했을 때 효과를 본 것으로, 두 개 이상의 레이어에서 head를 제거하는 상황은 고려하지 않았다.
- 전체 모델에서 여러 개의 head를 가지치기할 때의 효과를 보기 위해, 모델에 있는 모든 attention head를 proxy-중요도 순서로 정렬한 다음 head를 하나씩 제거하는 실험을 진행하였다.
[ 4.1 head의 중요도 점수 ]
각각의 head에 대한 proxy-중요도를 구하기 위해 마스킹한 변수에 대한 모델의 민감도를 다음과 같이 정의한다:
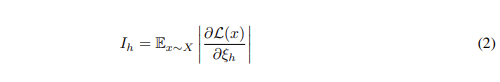
직관적으로 해석해보면, $I_h$의 값이 높다는 것은 변수를 제거하면 모델에 큰 영향을 준다는 것이다.
이때 중요도를 계산하기 위해 변화 정도의 절대값을 사용했는데, +/- 효과가 0으로 합산되는 것을 방지하기 위함이다.
(2) 식을 multi-head attention에 대한 (1) 식에 적용하면
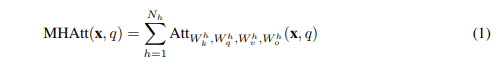
$I_h$에 대해 아래와 같은 식을 도출할 수 있다.

이 식은 뉴럴넷을 프루닝하는 것에 대한 기존 연구 맥락과 비슷하며, Taylor expansion 방법과 동일하다.
위의 계산을 위해 forward & backward pass만 계산하면 되기 때문에 학습 과정보다 느리지 않다.
논문에서는 학습 데이터, 혹은 그 일부에 대해 기댓값을 산출하였고, 레이어별로 l2 norm을 사용하여 점수를 정규화하였다.
[ 4.2 가지치기가 BLEU 스코어 / 정확도에 미치는 영향 ]

- 기계번역에서는 20%, BERT 모델은 40%까지 성능 저하 없이 가지치기가 가능했다.
- 그 이상 재학습 없이 가지치기를 진행할 경우 모델의 성능은 급격하게 저하하였다.
[ 4.3 가지치기가 효율성에 미치는 영향 ]
- 각각의 head는 각 attention 레이어에 있는 파라미터에서 상당 부분을 차지한다. (기계번역 6.25%, BERT 8.34%)
- 즉, attention head는 전체 모델 파라미터 중 많은 부분을 차지하고, 전체 레이어를 고려할 때 대략적으로 1/3을 차지한다.
- 따라서 가지치기를 진행하면 메모리 제약적인 상황에서 모델을 디플로이할 때 큰 이점을 얻을 수 있다.

- 뿐만 아니라 head를 단순히 마스킹하는 것이 아니라 가지치기하면 추론 속도에 큰 향상을 얻을 수 있다.
- 위 실험 결과는 BERT에서 50%의 attention head를 가지치기한 결과로, 큰 배치사이즈 (64)를 사용할 때 17.5%까지 추론 속도를 향상시킬 수 있다.
언제 더 많은 head를 사용하는 것이 중요한가 - 기계번역 케이스
- 모든 MHA 레이어를 정확도 희생 없이 하나의 attention head로 줄일 수 있는 것은 아니다.
- 트랜스포머 기반 번역 모델의 어떤 부분이 multi-head에 의존하는지 파악하기 위해서 4번째 실험에서 진행했던 휴리스틱한 프루닝을 각각의 attention (인코더/ 인코더-디코더/ 디코더)에 대해 반복 실험해 보았다.
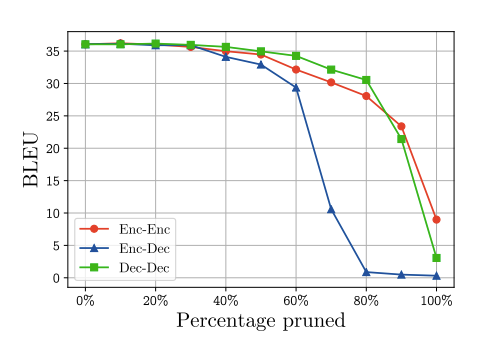
- 실험 결과, 인코더-디코더 attention layer에 있는 head를 가지치기할 시에는 성능이 급격하게 떨어졌다. 특히, 인코더-디코더 attention의 60% 이상을 가지치기하게 되면 성능은 급격하게 저하한다. 단, 20%정도까지는 번역 성능을 유지하며(BLEU 스코어 30 이상) 프루닝이 가능하다.
- 즉, 인코더-디코더 attention은 self attention에 비해 multi-headness에 더 의존적이다.
학습 과정 중 head의 중요성
지금까지의 실험은 이미 multi-head로 학습한 모델에 있어 몇몇 head의 중요성에 대해 진행하였다.
학습 과정에서 head가 가지는 중요성에 대한 통찰력을 가지기 위해, 매 에포크마다 head를 프루닝하는 실험을 진행했다.
이 실험에서는 더 작은 기계독해 모델(6개 레이어, 8개의 head)을 사용해 독어->영어 데이터셋으로 학습하였다.
아래 그림은 각 에포크에서 가지치기 단계를 올릴 때마다 (증분은 10-0%) 모델의 점수가 어떻게 변하는지 나타낸다.
- 에포크는 로그 스케일로 그려있고, 10 에포크 이상에서는 5 에포크마다의 성능을 표시한다.
- Y 축은 가지치기하지 않은 모델 대비 상대적인 BLEU 스코어의 감소분을 나타낸다.

결과적으로 두 가지 인사이트를 얻을 수 있었다 :
1) 초기 1-2 에포크에서는 프루닝 비율에 대해 선형적으로 성능이 감소한다. 즉, 대부분의 head가 동일하게 중요하다.
2) 10 에포크부터는 중요하지 않은 head가 집중되기 때문에 85-90%의 성능을 유지하면서 head의 40%를 프루닝할 수 있다.
이러한 결과로부터 중요한 head는 학습 시 일찍이 (그러나 즉각적이지는 않게) 결정된다는 것을 알 수 있다.
2020/11/08 - [AI] - 모델 경량화 - BERT 경량화 / 추론 속도 향상 기법 정리
모델 경량화 - BERT 경량화 / 추론 속도 향상 기법 정리
BERT는 뛰어난 성능과 간단한 fine-tuning 기법에도 불구하고 - 거대한 모델 사이즈 (파라미터 개수) - 느린 추론 속도 - 복잡하고 비용이 많이 드는 사전학습 과정 으로 인해 그 사용성에 대해 제한이
littlefoxdiary.tistory.com
