
BERT는 뛰어난 성능과 간단한 fine-tuning 기법에도 불구하고
- 거대한 모델 사이즈 (파라미터 개수)
- 느린 추론 속도
- 복잡하고 비용이 많이 드는 사전학습 과정
으로 인해 그 사용성에 대해 제한이 있다.
이에 모델을 경량화하고 추론 속도를 높이고자 하는 니즈가 강했고, 많은 연구가 이루어져왔다.
BERToloty - BERT 아키텍처에 대한 연구
: BERT의 구성 요소 각각과 그 유효성 / 역할에 대한 연구
Are sixteen heads really better than one? (Michel et al., 2019, 논문)
- BERT가 잘 작동하기 위해 실제로 필요한 attention head의 개수에 대해 연구
2020/12/29 - [AI] - [논문리뷰] Are Sixteen Heads Really Better than One?
[논문리뷰] Are Sixteen Heads Really Better than One?
논문 : arxiv.org/pdf/1905.10650.pdf 개요 Attention 알고리즘은 매우 강력하면고 범용적인 매커니즘으로, 뉴럴 모델이 중요한 정보 조각에 집중하여 그를 가중합한 결과를 예측에 사용한다는 아이디어이
littlefoxdiary.tistory.com
Revealing the dark secrets of BERT (Kovaleva et al., 2019, 논문)
- 언어 모델이 언어적인(lexical) 특성과 의미적인(semantic) 특성을 다른 레벨에서 학습
- 스페셜 토큰 및 핵심적인 대상에 특히 집중하게 된다는 것을 밝혀냄
Knowledge Distillation
: 성능이 좋고 모델 사이즈도 큰 teacher 모델의 결과를 작은 모델에게 가르치는 접근방법
딥러닝에서 Knowledge Distillation이 본격적으로 메인스트림에 오르게 된 것은 힌튼 교수님의 논문 이후이다.
a) 각 로짓 아웃풋에 대해 temperature를 조절하는 softmax-temperature
b) 라벨링되지 않은 transfer용 데이터셋을 활용하는 것이 잘 작동한 것으로 연구되었다.
일반적으로 머신러닝에서 분류 문제를 풀기 위해서는 cross-entropy loss를 사용하지만
KD에서는 <정답이 아닌> 라벨에게도 작은 non-zero 확률을 줌으로써 테스트 데이터에서의 일반화 성능을 높인다.
Tinybert: Distilling bert for natural language understanding (Jiao et al., 2019, 논문/깃헙)
- BERT base 모델보다 7.5배 작고 9.4배 빠르면서도 성능을 유지 (4 layer / 6 layer 버전)
- 사전학습과 다운스트림 태스크 fine-tuning 과정에서 transformer distillation 사용

2020/11/30 - [AI] - [논문리뷰] Tinybert: Distilling bert for natural language understanding
[논문리뷰] Tinybert: Distilling bert for natural language understanding
개요 모델 경량화는 모델 사이즈를 줄이고, 추론 속도를 향상시키면서 정확도를 유지하는 것을 목표로 한다. 대표적으로 사용하는 경량화 기법에는 아래와 같은 세 가지 접근법이 있다. 1) Quantiz
littlefoxdiary.tistory.com
Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. (Sanh et al., 2019, 논문/깃헙)
- BERT 크기를 40%까지 줄이면서도 성능의 97%를 유지하며 추론 속도는 60% 향상됨
- teacher 모델에 대해 soft target probability 를 사용해 distillation 손실함수를 정의하고 학습함
- 힌튼 교수가 제안한 것과 같이 softmax-temperature를 사용해 학습
- 또한 cosine embedding loss를 도입하여 student모델과 teacher모델의 히든 벡터의 방향성이 유지되도록 함.
Well-read students learn better: On the importance of pre-training compact models (Turc et al., 2019, 논문)
- 사전학습의 중요성 / KD의 유효성 등을 검증하는 논문
모델 구조의 변형을 통한 경량화
Albert: A lite bert for self-supervised learning of language representations (Lan et al., 2019, 논문/깃헙)
- Transformer 인코더 레이어간의 파라미터 공유
- 임베딩 레이어의 projection 분할을 통해 모델 파라미터 개수를 줄인 논문
MobileBERT: a compact task-agnostic BERT for resource-limited devices (Sun et al., 2020, 논문/깃헙)
- 핸드폰에서도 돌아갈 정도로 가벼운 BERT
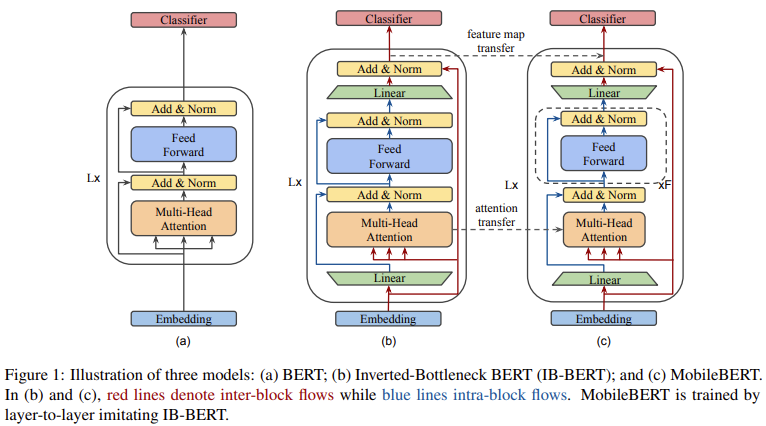
2020/12/18 - [AI] - [논문리뷰] MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
[논문리뷰] MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
* 논문 : https://arxiv.org/pdf/2004.02984.pdf * 깃헙 : https://github.com/google-research/google-research/tree/master/mobilebert 개요 성능은 좋지만 무거운 BERT_large, 다이어트 시켜보자! - Bottleneck..
littlefoxdiary.tistory.com
Bert-of-theseus: Compressing bert by progressive module replacing (Xu et al., 2020, 논문/깃헙)
- BERT를 여러 개의 모듈로 분할한 다음 compact해진 버전의 대체 모듈로 대체하는 압축 기법을 제안
- 이때 대체된 모듈이 원래 모듈의 행동을 모사할 수 있도록 학습시킴

Optimal Subarchitecture Extraction For BERT (Wynter and Perry, 2020, 논문/깃헙)
- BERT 아키텍쳐에서 NAS를 통해 최적의 파라미터를 추출하여 더 작고 효율적인 아키텍처로 만듦
- BERT-large의 16% 크기, 추론 속도는 ROBERTa의 1.21%, 사전학습은 288 GPU hours만 소요, CPU에서 8배 빠름
- Fully Polynomial Time Approximation Scheme에 따라 모델 크기/ 추론속도/ 에러율을 최적화함

'AI' 카테고리의 다른 글
| [논문리뷰] MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices (0) | 2020.12.18 |
|---|---|
| [논문리뷰] Tinybert: Distilling bert for natural language understanding (0) | 2020.11.30 |
| [논문리뷰] Small Language Models Are Also Few-Shot Learners (2) | 2020.10.09 |
| AI는 딥러닝을 넘어 "깊은 이해"의 단계로 넘어가야 한다 (0) | 2020.09.12 |
| Active Learning - ② 액티브 러닝 쿼리 전략 다섯 가지 (0) | 2020.08.19 |



