GPT-3는 in-context learning 방식으로 Few-shot 세팅에서 NLU 태스크를 잘 수행할 수 있다는 것을 보여주었다.
이러한 성과는 1750억 개에 달하는 엄청난 양의 파라미터로 수많은 텍스트에 대해 진행한 사전학습을 통해 달성할 수 있었는데, 이 모델을 학습시키는 데에 드는 비용이 $4.6 million, 약 52억 원에 달할 것으로 추정된다.
으아니... few-shot learning이 가능해진 대가가 52억이라니... (?)
천문학적인 학습 비용 이외에도 GPT-3가 가지는 한계는 존재한다. GPT-3에서 사용하는 in-context learning은 모델이 컨텍스트에 주어진 태스크에 대한 설명이나 예시를 통해 어떤 태스크를 수행해야 하는지를 추론 단계에서 '유추'해내는 것을 의미한다. 이 방법은 GPT-3가 학습한 LM이 아주 잘 작동할 때만 작동한다. 뿐만 아니라, Transformer의 구조상 컨텍스트에 밀어 넣을 수 있는 토큰의 개수는 몇백 개에 불과하기 때문에 예제 자체가 길어지거나 더 많은 예제를 넣고자 할 때 scalable하지 않을 수 있다.
그런데, 이러한 in-context learning 대신 <PET 알고리즘>을 사용해 작은 모델로도 few-shot learning이 가능하다고 도전장을 내민 논문이 있으니... <It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners>라는 논문이다. 바로 읽어보았다. 개념이 생소하고 어려웠지만 나에겐 52억이 없으므로 열심히 읽고 정리해보았다.
이 논문에서 제안한 모델은 다음과 같은 방식으로 few-shot 셋팅에서 NLU태스크를 풀어냈다.
(1) 텍스트 인풋을 태스크에 대한 묘사를 포함한 Cloze 스타일의 질문으로 바꾼다.
(2) 그라디언트 기반의 최적화를 수행한다.
(3) 라벨링되지 않은 데이터로부터 정보를 추가적으로 활용하여 성능을 향상한다.
이러한 방법을 통해 작은 모델로도 SuperGLUE 태스크에 대해 GPT-3를 능가하는 성적을 달성했다.
아래의 그래프는 32개의 학습 샘플만으로 SuperGLUE 태스크를 풀었을 때의 결과이다.
GPT-3에 사용된 파라미터의 0.1%만으로 SuperGLUE에서 더 높은 성적을 낸 것을 확인할 수 있다.

Pattern Exploiting Train (PET)
PET의 작동 원리는 다음과 같다.
먼저 원래 태스크를 Cloze 타입으로 변형한다.
Cloze 스타일 질문은 ~~~, 정답은 ___. 와 같이 빈칸을 뚫어놓는 질문 스타일을 말한다.
예를 들어 두 문장의 entailment(함의) 관계를 분류해야 하는 태스크를 생각해보자.
x : ( 문장 1- 유가가 오른다 , 문장 2- 유가가 다시 내린다 )
두 문장은 함의 관계가 존재하지 않으므로, 이 문제에 대한 정답 y는 <not entailment>이다.
이 태스크를 Cloze 질문으로 바꾸면 아래와 같이 나타낼 수 있다.
P(x) : 유가가 오른다 ? ___ , 유가가 다시 내린다 .
이렇게 인풋을 하나의 빈칸(mask)을 포함하는 Cloze 질문으로 매핑하는 것을 P, pattern이라고 정의한다.
이제 빈칸에 들어가야 할 정답은 'not entailment'가 되어야 하는데,
빈칸은 하나이기 때문에 이 정답을 하나의 토큰으로 표현해주는 verbalizer v가 필요하다.
예를 들어
- y = not entailment -> v(y) = No
- y = entailment -> v(y) = Yes 로 매핑해주는 v를 생각할 수 있다.
** 잠깐 정리하자면...
인풋 X를 아웃풋 Y로 매핑하기 위해 PET 알고리즘은 pattern-verbalizer pairs(PVPs)의 집합이 필요하다.
* a pattern P: X → T* 는 인풋을 마스크 하나를 포함한 Cloze 질문으로 매핑
* a verbalizer v : Y→ T는 아웃풋을 패턴 내에서 태스크의 의미를 나타낼 수 있는 하나의 토큰으로 매핑
이제 모델은 인풋으로부터 생성된 패턴 P(x)에 있는 빈칸에 v(y)가 적절한 토큰일 점수를 모델링한다.
그리고 모든 가능한 v(y)가 빈칸에 들어갈 토큰일 점수를 Softmax를 통해 확률처럼 나타낸다.
예를 들어 위의 예시에서는 다음과 같은 계산이 이루어질 수 있다.
- 유가가 오른다 ? No , 유가가 다시 내린다 -> 1.2점 -> y = not entailment 73%
- 유가가 내린다 ? Yes , 유가가 다시 내린다 -> 0.2점 -> y = entailment 27%

수식으로 나타내자면 v(y)가 P(x)의 마스킹된 자리에 올 점수를 아래의 식과 같이 나타낼 때
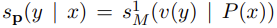
인풋 x에 대한 정답이 y일 확률은 아래와 같이 계산한다.
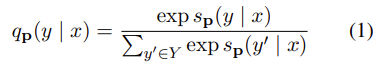
이제 관건은 인풋 x와 아웃풋 y에 대해, Cloze 스타일로 태스크를 잘 정의하는 P와 v를 알아내는 것이다.
그런데 어떤 PVP가 잘 작동하는지 알아내는 것은 어렵기 때문에 여러 개의 PVP들을 조합해서 사용한다.
방법은 다음과 같다:
1. 주어진 few examples에 대해 MLM 학습하기
- 다양한 PVP에 있는 각각의 패턴 P_i에 대해 학습 데이터셋 (x, y)를 사용해 MLM fine-tuning을 한다.
- 이때 학습은 실제 정답 y와 모델이 예측한 v(y)가 빈칸에 올 확률 사이의 cross-entropy를 최소화하는 방향으로 이루어진다.
2. 라벨링 되지 않은 데이터셋 annotate 하기
- 이제 학습된 모델들을 앙상블 하여 라벨링되지 않은 데이터들의 라벨을 생성하는 데에 사용한다.
- 각각의 데이터는 확률분포에 따라 soft-labeling을 통해 annotation한다.
- 여기서 확률은 각각의 패턴들이 1단계의 학습을 거치기 전에 few example들에 대해 가지는 정확도를 가중치로 하여 예측값을 가중합하여 계산한다.

3. Soft-labeling 된 데이터를 이제 일반적인 텍스트 분류 모델을 학습시키는 데에 사용한다.
참고로 2와 3에서 사용하는 방은 힌튼 교수님이 제안한 knowledge distillation 방법과 유사하다.
여기서 각기 다른 패턴을 사용해 학습한 MLM 모델들이 다른 모델로부터 배울 수 있도록 iPET을 사용할 수 있다.
여러 generation을 거치며 PET가 진화하는 양상을 보이는 이 방법은 다음과 같이 학습한다.
1. 일반적인 PET 알고리즘을 사용해 MLM들의 앙상블을 학습한다.
2. 각각의 모델에 대해 랜덤하게 선택된 다른 모델들의 집합을 사용해 라벨링되지 않은 데이터를 라벨링하여 학습 데이터로 준다. 그리고 모델을 이렇게 새로 만들어진 학습 데이터를 사용해 다시 학습
3. 이 과정을 몇 세대에 거쳐 반복하며, 갈수록 생성하는 학습 데이터를 일정량씩 늘린다.
요약하자면 iPET = 만들어진 모델로 학습 데이터 계속 만들어내서 모델 계속 좋게 만드는 알고리즘
PET의 마스크를 여러 개로 확장하기
위에서 살펴본 PET 알고리즘은 verbalizer가 가능한 아웃풋 y를 하나의 토큰으로 매핑한다.
하지만, 하나의 토큰으로 태스크를 묘사하는 것은 실용적이지 않거나 맞지 않는 경우가 많다.
본 논문에서는 두 가지 측면에서 기존의 PET 알고리즘을 일반화(generalize)한다.
1. verbalizer v를 v: Y→ T*, 즉 아웃풋을 여러 개의 토큰으로 매핑하도록 일반화한다.
2. 각각의 인풋에 대해 아웃풋 공간은 서로 같지 않을 수 있도록 일반화한다.
이에 따라 각각의 인풋 x에 대해 해당 인풋이 주어질 때 나올 수 있는 아웃풋의 집합을 Y_x로 명명한다. (Y_x는 Y에 포함된)
PVP p=(P,v)에 대해 인풋 x에 대해 v(y)가 가질 수 있는 최대 길이를 l(x)로 정의하는데,
이때 l(x)는 verbalizer가 Y_x에 있는 어떠한 아웃풋이든 표현할 수 있는 길이이다.
또한 마스크를 포함한 P(x)는 k개의 마스크를 가진 Cloze 스타일의 질문인 P^k(x)로 일반화한다.
Inference
각각의 x, y, |v(y)| = k에 대해 패턴 p에 대해 인풋 x의 결과를 y로 예측할 확률(q_p(y | x))을 autoregressive하게 정의한다.
P^k(x)에서 시작해 k번의 연속적인 추론을 실행하는데, MLM의 컨피던스에 기반해 다음 토큰을 선택한다.
이를 수식으로 표현하면 다음과 같다:


이제 기존의 PET와 다르게 이 결과는 확률 값처럼 해석할 수 없으며, 합은 1이 아닐 수 있다.
Training
위에서 (3)번 식을 학습 단계에서 계산하는 것은 계산 비용이 매우 비싸질 수 있다.
하나의 forward pass에서 모든 필요한 확률분포를 계산하기 위해 q_p(y | x)를 다음과 같이 approximate 한다
(1) 항상 어떠한 아웃풋이든 예측할 수 있는 최대 개수의 마스크 개수를 사용
(2) 각각의 Y_x에 있는 각각의 y'에 대해 v(y')=t_1, ..., t_k에 대한 예측을 병렬적으로 수행

위에서 계산된 q는 Y_x에 대한 확률분포가 아니기 때문에, 더 이상 cross-entropy loss를 사용할 수 없다.
그 대안으로 multi-class hinge loss를 사용해 다음 식을 최소화하도록 모델을 학습시킨다:

실험 결과
SuperGLUE 태스크에 속해 있는 각각의 태스크에 대해
- 32개의 학습 데이터셋을 샘플링
- 20,000개의 unlabeled 데이터셋을 활용함
- RTE와 CB 태스크는 unlabeled 데이터조차 적기 때문에 MNLI의 문장들을 활용함.
본 논문에서 샘플링해 구성한 데이터는 FewGLUE라는 이름으로 깃허브에 공개
태스크를 PVP로 변환하기
SuperGLUE의 태스크를 PVP 집합으로 변환하여 제안한 알고리즘을 학습한다.
태스크별로 다양한 패턴과 verbalizer를 조합하여 PVP set을 생성했는데, 예를 들어 BoolQ는 다음과 같이 풀어낸다.
BoolQ : 문단 q와 yes/no 질문 q로 구성된 태스크
- 6개의 PVP 사용
- P: 아래의 세 가지 패턴 사용

- v: {yes/no} {true/false}로 매핑하는 두 가지 사용
WSC의 경우 verbalizer가 여러 개의 토큰을 매핑해야 하는데 (논문에서 제안한 알고리즘), 다음과 같이 푼다.
WSC: 문장 s에 대해 주어진 대명사 p이 명사 n을 지칭하는지 판단하는 태스크
이 태스크는 생성 태스크로 바꿔서 푸는데, 대명사 p를 하이라이팅 하고 이것이 가리키는 명사를 생성하도록 한다.
- P:

- v: 정답 n와의 identity function을 사용.
이렇게 풀면 free-form completion 문제가 되기 때문에, 학습과 추론에 수정을 가했다고 한다 (부록 A)
SuperGLUE 결과

- ALBERT xxlarge-v2를 베이스라인 Language Model으로 사용.
- 맨 아래 SOTA는 SuperGLUE 전체 데이터셋을 사용해 달성한 SOTA 성적을 보여줌
- test셋 기준으로 full-train set을 사용한 것에 미치지는 못하지만, 평균적으로 GPT-3보다 높은 성적을 얻음
결과 분석
Few-shot 셋팅에서 좋은 성능을 얻기 위해 중요한 몇 가지 요소들에 대해 조사함
- PVP의 선택
- 라벨링된 데이터와 라벨링되지 않은 데이터를 모두 활용하기
- 베이스로 사용한 LM 모델의 특성
5.1 패턴의 선택
사실 NLU 태스크를 Cloze 스타일로 바꾸는 것이 쉬운 일은 아니다. GPT-3에서는 WSC 태스크를 풀기 위해 30글자에 달하는 설명을 썼는데, 이러한 formulation을 어떻게 최적화했는지는 불분명하다. 본 논문에서는 패턴과 verbalizer 선택의 중요성에 대해 조사하기 위해 세 가지 PVP 패턴에 대해 조사해봤다.
a. 논문에서 제안한 방식 (P_ours)
b. GPT-3에서 사용한 방식 (P_gpt3)
c. 두 방식의 콤비네이션 (P_both)

그 결과 RTE 태스크에서는 GPT-3 방식이 좋았고, MultiRC에서는 논문 방식이 더 좋았다.
특히 성능 차이가 꽤 큰 것을 통해 좋은 패턴을 선택하는 것이 성능 향상에 중요하다는 것을 알 수 있다.
하지만 많은 양의 데이터에 대해 패턴들을 테스트해보지 않는 이상, 어떤 패턴이 좋은지 알기 어렵다.
즉, few-shot 셋팅에서 사용한 LM이 잘 이해하지 못하는 PVP를 어떤 식으로든 보강하는 것이 큰 챌린지가 될 것이다.
여기서 (c) 방식, 즉 패턴들을 조합해 사용한 결과가 성능이 오르는 것을 볼 수 있다.
PET 알고리즘은 모든 PVP를 사용하여 성능이 안 좋은 패턴을 보강하고, 더 나은 성적을 얻을 수 있도록 한다는 것이다.
적절한 패턴들을 신중히 엔지니어링 하는 것이 하나의 패턴을 띡 사용하는 것보다 중요하다는 것이다.
5.2 라벨링되지 않은 데이터셋 활용
GPT-3와 다르게 이 알고리즘은 여러 개의 PET들이 학습한 지식을 하나의 classifier로 distill하기 위해 라벨링되지 않은 데이터가 필요하다. iPET를 사용하려면 세대에 걸쳐 학습 데이터를 생성해야 하기 때문에 또 unlabeled데이터가 필요하다.
라벨링되지 않은 데이터를 사용하여 PET 결과를 하나의 classifier로 distil하는 것의 성능을 보기 위해
a. PET 결과를 distil한 모델의 성능
b. k개의 PVP들이 추론한 결과를 앙상블한 것을 최종 예측으로 사용
(b) 방법은 unlabeled 데이터를 전혀 필요로 하지 않는다.
하지만 이 방법은 (a)방법에 비해 파라미터의 개수가 3*k배가 된다는 단점이 있다. (하나의 PVP당 3개의 모델을 학습하므로)
그럼에도 불구하고 이 숫자는 GPT-3에 비하면 아주 작은 숫자이다.
결과적으로 CB, RTE, MultiRC에서 평균적으로 (b) 방법이 성능이 더 좋았다.
좋은 성능만을 위해서라면 unlabeled data는 아예 필요하지 않을 수도 있다는 뜻이다.
하지만 하나의, 가벼운 모델을 위해서는 distillation이 필요하다.
근데 RTE와 CB 태스크의 경우, 데이터셋이 워낙 적기 때문에 MNLI에서 unlabeled 데이터를 가지고 왔다고 했음.
비슷한 태스크라 하더라도 혹시 domain shifting이 있었기 때문에 distil 방법이 덜 유효했던 것은 아닌지...?
세 가지 태스크에 대해서만 실험한 것이 아쉬움 ㅎㅎ
5.3 라벨링된 데이터셋의 활용
패턴을 전혀 사용하지 않는 일반적인 지도 학습과 PET, 그리고 완전히 비지도 학습으로 학습한 모델을 비교해보았다.
32개의 example에 대해 PET는 두 개의 baseline보다 성능이 좋았다.

다음으로 priming 방법이랑 비교를 해보았다. Priming은 예시 데이터를 문맥으로 넣어주는 것을 의미한다.
이 방법은 512 토큰 제한 때문에 ALBERT로는 풀 수가 없어 XLNet을 사용해 실험을 진행했다.
그 결과
- PET 방법이 priming보다 좋았고, 심지어 RTE 태스크에서 priming은 찍은 거보다도 성적이 낮았다.
- MultiRC는 32개의 예제를 다 넣으려면 10,000 토큰이 넘어가고, 트랜스포머의 self-attention에서 기인하는 제곱 시간 복잡도로 인해 아예 실험이 불가하여 결과가 없다. <실험이 불가능하다>는 것 자체가 priming 방법의 한계를 보여주는데, 예제를 몇 개 이상 주는 것이 어렵다는 것이다. GPT-3도 2,048 토큰까지만 처리할 수 있기 때문에 이러한 한계점을 피해 갈 수는 없다.
(세 가지 측면에 대한 분석이 더 있었으나 정리 생략)
5.4 기저 LM 모델에 따른 비교 -> ALBERT가 RoBERTa나 GPT-2 베이스보다 좋았음
5.5 제안한 Multiple Mask에서 사용한 max-first 디코딩 기법에 대한 분석
5.6 32개의 학습 데이터 랜덤 샘플링에 대한 분석 -> GPT-3에서와 다르게, '좋은 학습 예제'를 선택하는 것이 그다지 중요하지 않았음.
결론
- GPT-3의 1/1000개의 파라미터만으로 SuperGLUE에서 그에 상응하는 성적을 얻을 수 있었다.
- 이는 태스크를 Cloze 스타일로 바꾸고 다양한 패턴에 대한 모델을 앙상블하는 PET 알고리즘을 사용한 결과이다.
- 뿐만 아니라 여러 개의 토큰을 예측할 수 있는 PET 학습 & 추론 방법도 제시했다.
- 실험 결과를 분석한 결과 PET는 학습 데이터를 Cloze 질문으로 바꾸는 다양한 패턴들을 적절히 활용하고, 덜 좋은 패턴을 보상하며 라벨링된 데이터를 사용해 파라미터를 적절하게 업데이트하는 것을 발견했다.
- 또한, 같은 셋팅에서 다른 Few-shot 알고리즘을 실험 & 비교할 수 있도록 사용한 데이터를 공개했다.
오... 뭔가 큰 바람이 부는구나 하는 것이 느껴질 때가 있다. BERT 논문을 처음 읽었을 때도 그랬다. 아등바등 아키텍처를 디자인하는 대신 언어를 이해할 수 있는 거대한 모델을 학습해놓고, 그 능력을 활용해 이것저것 잘하는 세상이 오고 있었다. 모델이 너무 크고 느린 건 아닌가도 싶었지만 MobileBERT, DistilBERT 같이 서비스화 니즈에 따른 모델들도 개발되고, 구글에서도 검색 BERT를 활용하고 있다고 하니 일단 대다난 모델을 만들고 나면 그걸 쓸 수 있는 방법은 어떻게든 나오나 보다!
그래서 GPT-3가 나왔을 때는 "너무 커서 어케 써!"라는 회의적인 마음은 잠시 접어두고, 그 대단함에 마음껏 감탄해 보았다. 개인적으로 GPT-3에서는 모델의 <생성 능력>보다는 few-shot 셋팅에서 태스크를 수행한다는 점에 더 큰 감명을 받았었다. 좋은 언어 모델이 있어도 결국엔 데이터를 모으기 위해 엄청난 비용과 시간이 들고, 혹시라도 덜 모으면 여지없이 overfitting 되어버린다는 현재의 한계를 극복할 방법이 보였기 때문이다.
GPT-3가 few shot의 가능성을 보여준 후 꽤나 빨리(?!)이 논문이 나온 거 같다. Unlabeled 데이터가 필요하고, 적용할 수 있는 태스크에 한계는 있어 보이지만 (생성/ 대화모델에도 사용할 수 있을까? ) 데이터 증축 / 태스크 스타일 변환을 통한 성능 향상 등에 사용해보면 재밌을 거 같다.

'AI' 카테고리의 다른 글
| [논문리뷰] Tinybert: Distilling bert for natural language understanding (0) | 2020.11.30 |
|---|---|
| 모델 경량화 - BERT 경량화 / 추론 속도 향상 기법 정리 (0) | 2020.11.08 |
| AI는 딥러닝을 넘어 "깊은 이해"의 단계로 넘어가야 한다 (0) | 2020.09.12 |
| Active Learning - ② 액티브 러닝 쿼리 전략 다섯 가지 (0) | 2020.08.19 |
| Active Learning - ① 액티브 러닝이란 무엇인가 (0) | 2020.08.16 |



