개요
모델 경량화는 모델 사이즈를 줄이고, 추론 속도를 향상시키면서 정확도를 유지하는 것을 목표로 한다.
대표적으로 사용하는 경량화 기법에는 아래와 같은 세 가지 접근법이 있다.
1) Quantization (논문)
2) Weight Pruning (논문)
3) Knowledge Distillation (논문1, 논문2)
본 논문에서는 이 중 Knowlege Distillation 방법을 사용하여 모델을 경량화하는 방법을 제안한다.
특히 Transformer 기반의 모델에 유효한 새로운 Knowledge Distillation 기법을 제안하였다.
그 결과
- 4개 층으로 이루어진 TinyBERT 모델은 GLUE 벤치마크에서 BERT_base의 96.8% 성능 유지
- 이는 BERT_base보다 7.5배 작고 9.4배 빠른 모델
- 6개 층으로 이루어진 TinyBERT 모델의 경우 티쳐 모델에서 성능 감소가 없다
는 결과를 얻었다.
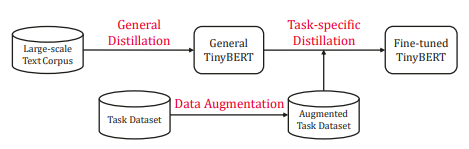
TinyBERT는 Transformer Distillation을 사전학습과 태스크 특화된 fine-tuning 단계에서 둘 다 진행한다.
이로써 Tiny모델은 BERT에 있는 general domain의 지식 뿐만 아니라 task-specific 지식까지 학습하게 된다.
모델의 핵심
[세 가지 Loss 사용]
Transformer distillation에서 세 가지 loss 함수를 적용하여 다음의 representation을 학습하도록 한다
1) 임베딩 레이어의 아웃풋
2) Transformer layer에 있는 히든 벡터와 어텐션 행렬
: Teacher BERT가 학습한 attention weight는 언어학적인 지식을 포함하기 때문 (논문)
이 지식은 구문이나 상호참조 정보 등 NLU에 필수적인 정보들을 포함함
3) 예측 레이어의 아웃풋 로짓
[두 단계의 distillation 진행]
1) general distillation
: TinyBERT는 선생님의 행동을 모사하게 되고, 그 결과 general TinyBERT를 얻을 수 있음
2) task-specific distillation
: Step 1에서 얻은 general 모델을 시작점으로 하여
- Data augmentation
- augment된 데이터셋에 대해 fine-tuning 하는 단계를 거쳐 좋은 모델을 얻음
모델의 목적 함수
[Knowledge Distillation]
KD의 목적은 커다란 선생님 네트워크 T의 지식을 작은 학생 네트워크 S에게 전달하는 것이다.
학생 네트워크는 선생님 네트워크의 행동을 모사할 수 있도록 학습된다.
수식적으로 $f^T$를 선생님의 행동 함수, $f^S$를 학생의 행동 함수라고 표기한다.
Transformer의 Multi-Head Attention, FFN 레이어, 중간 representation(어텐션 행렬 등)을 행동 함수로 둘 수 있다.
이제 KD는 다음의 목적함수를 최소화하는 것으로 모델링할 수 있다.
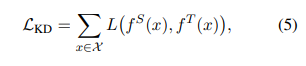
여기서 L(.)은 선생님과 학생 네트워크간의 차이를 평가할 수 있는 함수를 의미한다.
즉, 이러한 관점에서 볼 때 KD의 핵심은 행동 함수와 손실함수를 얼마나 잘 정의하는가로 귀결된다.
[Transformer Distillation 개괄]
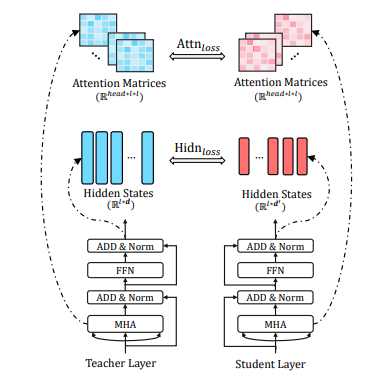
본 논문에서 사용하는 선생님과 학생 네트워크는 모두 Transformer 기반이다.
Transformer 구조에서 KD를 위해, Attention 기반의 distillation과 Hidden state 기반의 distillation을 제안한다.
선생님 모델이 N개, 학생 모델이 M개의 레이어를 가지고 있을 때, KD는 N개 중 M개 레이어를 고르는 문제부터 시작한다.
레이어를 선택했으면, n = g(m) 에 따라 학생 레이어의 m번째 레이어를 선생님의 n번째 레이어로 연결할 수 있다.
0번째 레이어를 임베딩 레이어, M + 1번째 레이어를 prediction 레이어로 둘 때,
먼저 0 = g(0) N+1 = g(M+1)을 얻을 수 있다.
이외의 Transformer layer은 어떻게 연결하는 것이 효과적인지에 대해서는 이후 실험 섹션에서 다룬다.
이제 KD는 다음의 손실함수를 최소화하는 방식으로 학생 네트워크가 선생님 네트워크의 지식을 학습한다:
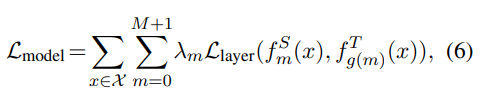
여기서
- L_layer은 해당 모델 레이어에 대한 loss (예. Transformer레이어 / 임베딩 레이어)
- f_m(x)는 m번째 레이어의 행동함수
- lambda_m은 m번째 레이어 distillation의 중요도를 나타내는 가중치이다.
[Transformer Layer Distillation]
Transformer layer에서는 attention과 hidden state 각각에 대해 지식을 distillation한다:
1) 학생 네트워크는 Multi-Head Attention의 결과 나오는 어텐셜 행렬을 모방하도록 한다
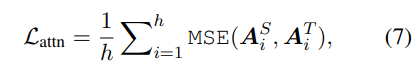
- h는 attention head의 개수
- A_i (l x l 차원)는 선생님/ 학생 모델의 i번째 head가 생성한 어텐션 행렬
- l은 인풋 텍스트의 길이를 의이
여기서는 Softmax를 취하지 않은, 즉 normalize되지 않은 어텐션 행렬 A_i를 사용하는데,
실험을 해 보았을 때 normalize되지 않은 어텐션 행렬을 목표로 할 때 더 빠르게 수렴하고 성능이 나았기 때문
2) Transformer layer의 아웃풋을 모방하도록 한다
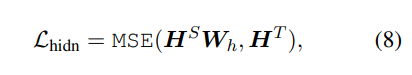
- H^S는 l x d' 차원으로, 학생 네트워크의 히든 벡터 의미
- H^T는 l x d 차원으로, 선생님 네트워크의 히든 벡터 의미
- 학생 네트워크의 히든 벡터 d'는 선생님 네트워크보다 작게 설정할 수 있기 때문에, 차원을 맞추기 위한 W_h도입
[Embedding-layer Distillation]
hidden state distillation과 유사하게 임베딩 레이어에 대해 distillation 진행
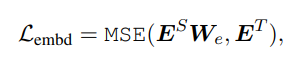
- E^S는 학생 네트워크의 임베딩 결과
- E^T는 선생님 네트워크의 임베딩 결과
- 둘의 차원을 다르게 설정할 수 있기 때문에 학습 가능한 파라미터 W_e를 도입함
[Prediction-layer Distillation]
최종 레이어의 지식을 학생 모델에 distillation함.
이때 Hinton 논문에서 제시한 것과 같이 학생/선생님 모델의 로짓에 대해 soft cross-entropy loss를 사용 :
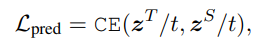
- z^S와 z^T는 각각 학생 / 선생님 모델의 아웃풋 로직 벡터를 표기
- 이때 t는 temperature value로, 경험상 t = 1로 둘 때 잘 작동하였다
지금까지 나온 distillation 목적 함수를 종합하여 다음과 같이 최종 loss를 정의할 수 있다:
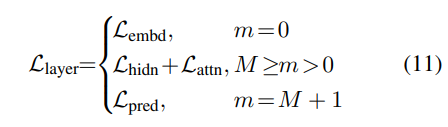
TinyBERT 학습 상세
[General Distillation]
사전학습된 BERT 모델을 선생님 네트워크로 사용함
일반적인 도메인의 텍스트 코퍼스에 대해 Transformer Distillation을 수행
이 때 general distillation에서는 prediction-layer distillation은 수행하지 않음
General Distillation 단계의 목적은 TinyBERT가 BERT의 중간 구조물을 미리 학습하도록 하는 데에 있다. 특히, 실험을 해 보았을 때 사전학습 과정에서 prediction-layer distillation을 수행하는 것은 다운스트림 태스크 수행에 있어 별다른 성능 향상을 가지고 오지 않았다. Transformer-layer와 Embedding layer의 지식을 distillation하는 것으로 충분하였다.
[Task-specific Distillation]
기존 연구에 따르면 fine-tuning된 BERT 모델은 도메인 특화적인 태스크에서 over-parameterization 문제가 있었다.
즉, 작은 모델로도 BERT와 비견할만한 성능을 얻는 것이 가능하다.
Step 1. Data Augmentation
사전학습된 BERT 모델과 GloVe 워드 임베딩을 사용하여 토큰 단위의 대체를 통해 데이터 증축을 실행한다.
언어모델을 사용하여 하나의 토큰에 대해 replace될 수 있는 단어를 맞추게 하고,
word embedding을 사용해 그 중 가장 비슷한 단어를 받어오는 방식이다. 구체적인 알고리즘은 아래와 같다.

Step 2. Task Specific distillation
general distillation을 통해 얻은 TinyBERT_general을 시작점으로, task-specific한 distillation을 진행한다.
일반적인 지식을 어느정도 얻은 Tiny 모델이 fine-tuning을 통해 작은 사이즈로도 기존에 비견할만한 성능을 내게 된다.
실험 결과
모델 크기 비교
| BERT_base | Tiny BERT_4 | BERT_tiny | BERT_small | BERT4-PKD | DistilBERT4 | |
| 레이어 개수 M | 12 | 4 | 4 | 4 | 4 | 4 |
| Transformer hidden | 786 | 312 | 312 | 512 | 768 | 768 |
| FFN_intermediate | 3072 | 1200 | 1200 | 2048 | 3072 | 3072 |
| attention head | 12 | 12 | ||||
| 총 파라미터 개수 | 109M | 14.5M | 14.5M | 29.2M | 52.2M | 52.2M |
| # FLOPS | 22.5B | 1.2B | 1.2B | 3.4B | 7.6B | 7.6B |
GLUE 태스크 성능
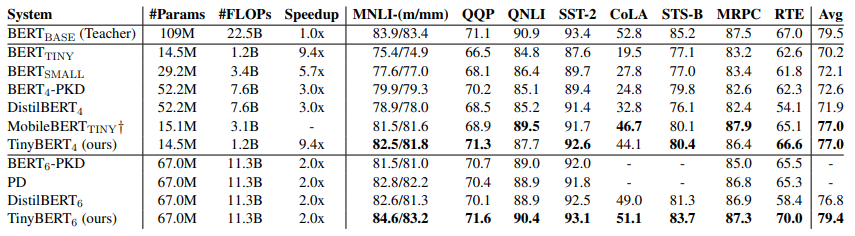
- TinyBERT 4의 경우, 4 레이어를 사용한 다른 경량화 모델 대비 속도가 빠르면서 성능이 가장 유지된다.
- 6개 레이어를 사용한 TinyBERT 6의 경우, 파라미터가 40%감소 & 속도가 2배 빨라지면서도 BERT_base 성능을 유지한다.
2020/11/08 - [AI] - 모델 경량화 - BERT 경량화 / 추론 속도 향상 기법 정리
모델 경량화 - BERT 경량화 / 추론 속도 향상 기법 정리
BERT는 뛰어난 성능과 간단한 fine-tuning 기법에도 불구하고 - 거대한 모델 사이즈 (파라미터 기수) - 느린 추론 속도 - 복잡하고 비용이 많이 드는 사전학습 과정 으로 인해 그 사용성에 대해 제한이
littlefoxdiary.tistory.com

'AI > Algorithm&Models' 카테고리의 다른 글
| [논문리뷰] Are Sixteen Heads Really Better than One? (0) | 2020.12.29 |
|---|---|
| [논문리뷰] MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices (0) | 2020.12.18 |
| 모델 경량화 - BERT 경량화 / 추론 속도 향상 기법 정리 (0) | 2020.11.08 |
| [논문리뷰] Small Language Models Are Also Few-Shot Learners (2) | 2020.10.09 |
| AI는 딥러닝을 넘어 "깊은 이해"의 단계로 넘어가야 한다 (0) | 2020.09.12 |