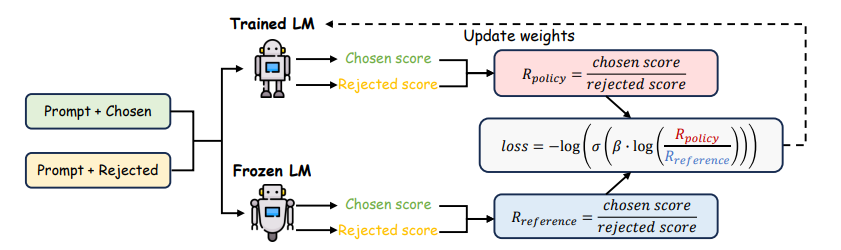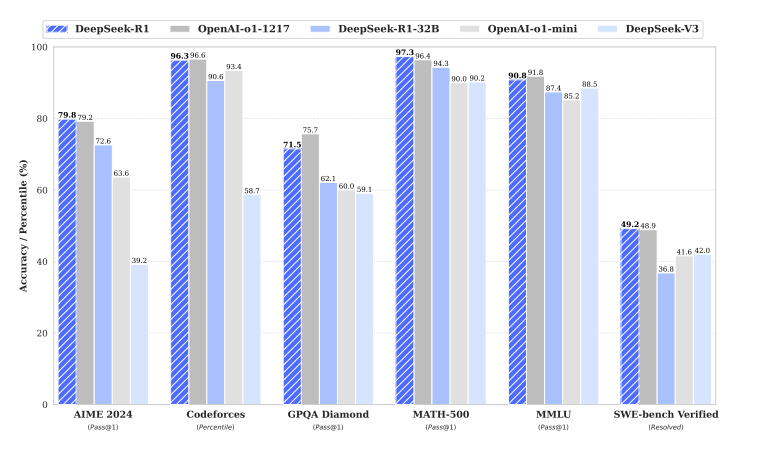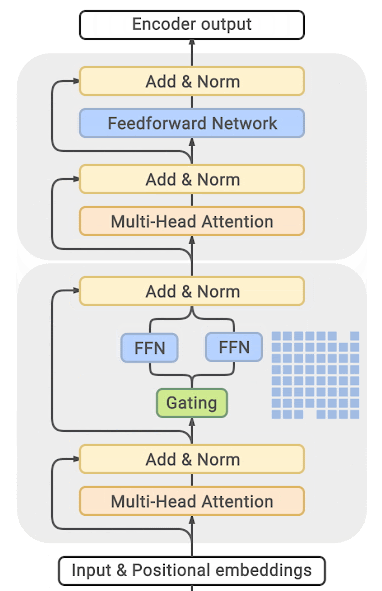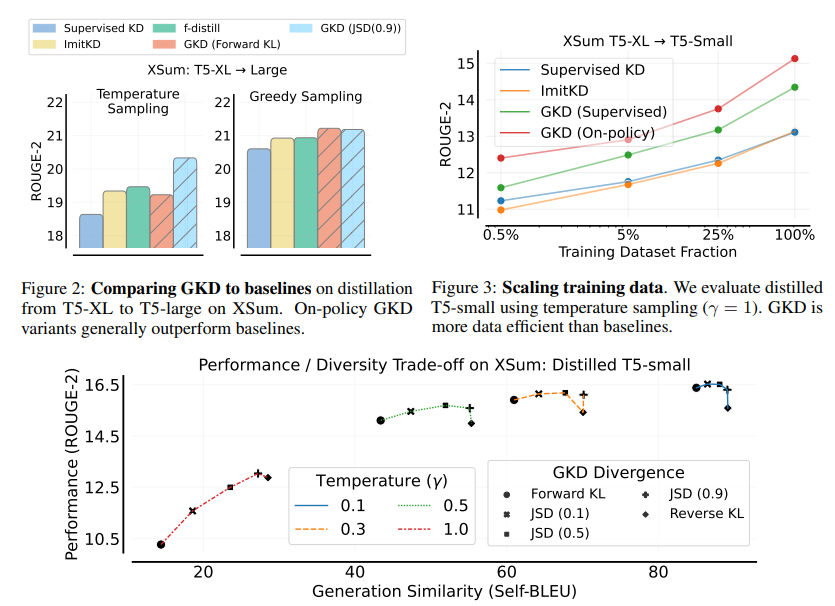

Generalized Knowledge Distillation 개요LLM은 대규모 파라미터를 활용하여 다양한 태스크에서의 가능성을 입증해왔으나, 이러한 규모로 인해 추론 비용 등 모델의 배포 관점에서 장벽이 있다. Knowledge Distillation(KD, 지식 증류)는 비교적 작은 학생(student) 모델을 학습하여 추론 비용과 메모리 사용량을 줄이기 위해 교사 모델을 압축하는 기법이다. Auto-regressive 모델에 대한 지식 증류는 ▲ teacher 모델이 생성한 고정된 아웃풋 시퀀스를 활용하거나 (Kim & Rush, 2016) ▲토큰 단위의 확률 분포를 지정함으로써 teacher 모델이 라벨을 지정할 수 있는 방법(Sanh et al., 2019)을 활용하여 이루어졌다. 그러나 이러..