Knowledge Distillation 개요
지식 증류 (Knowledge Distillation, KD)는 파라미터 규모가 큰 LLM teacher model의 지식을 소규모 student model에게 전달하여 모델 효율성을 높이면서도 성능을 유지할 수 있도록 하는 Post training 기법이다.
KD는 전통적인 hard label보다 더 풍부한 teacher 모델의 출력 분포를 활용한다. 이를 통해 학생 모델은 단순히 클래스 예측뿐 아니라, 클래스 간의 관계나 teacher representation에 내재된 미묘한 패턴까지 복제할 수 있다. 이 과정은 일반적으로 지도 학습 목표함수와 증류 목표함수를 균형 있게 조정하는 복합 손실 함수를 최적화하는 방식으로 이루어진다. 이로써 계산 및 메모리 요구사항을 크게 줄이면서도 일반화 성능은 유지할 수 있다.
KD의 핵심 메커니즘은 전통적인 classification loss와 distillation loss를 결합한 하이브리드 loss를 최소화하는 것이다. 수식으로 표현하면, teacher 모델의 soft output 확률분포인 P_t, student 모델의 예측 P_s, 정답 라벨 y와 student의 아웃풋 y_s가 주어질 때 Knowledge distillation loss는 아래와 같이 작성할 수 있다:

여기서 L_CE는 정답 라벨과의 alignment를 위한 cross-entropy loss이고, L_KL은 teacher과 student 분포 간의 차이(divergence)를 측정할 수 있는 Kullback-Leibler divergence 항이다. Soft target p_는 온도에 대한 파라미터 T(즉, p_t = softmax(z_t/T), z_t는 teacher 모델의 logits)로 조절되며, teacher 모델의 확률적인 정보를 인코딩하여 student 모델이 단순히 정답을 맞추는 것을 넘어 teacher가 의사결정을 내리는 뉘앙스를 모방할 수 있게 해준다.
Black-box Knowledge Distillation
student 모델이 teacher 모델의 출력 로짓(output logits)만으로 학습하는 방식으로, teacher 모델의 내부의 representation이나 아키텍처 정보를 활용하지는 않는다. 이 방식은 Hinton이 처음 제안한 고전적인 KD 패러다임으로, 유연성이 높아 널리 사용된다.
Black-box KD에서는 teacher모델을 불투명한 함수로 간주하여, 제한 접근을 가진 proprietary 모델이나 pre-trained 모델에 대해서도 지식 증류가 가능하다. 실제로 ChatGPT, GPT-4 같은 대형 모델을 teacher LLM으로 고품질 출력을 생성하는 데 사용할 수 있다. GPT-2, T5, Flan-T5, CodeT5 같이 효율성에 최적화된 소형 언어 모델(SLM)은 student 모델로 활용된다.
🤖 Black-box KD 모델 예시: Selective Reflection-Tuning
1. teacher 모델(ChatGPT)이 기존 데이터를 reflection하여 개선된 instruction-response 쌍을 생성한다.
2. 학생 모델이 IFD 및 r-IFD 점수를 기반으로 자신에게 적합한 데이터를 선택한다.
3. 선택된 고품질 데이터로 학생 모델을 instruction-tuning하여 성능을 향상시킨다.
이 방식은 새로운 데이터를 수집하지 않고도 기존 데이터를 재활용하여 모델의 성능을 향상시킨 효과적인 방법이다.
White-box Knowledge Distillation
전통적인 Distillation 패러다임을 확장한 방식으로, teacher 모델의 내부 representation으로부터 추가적인 인사이트를 활용한다. 특히 teacher 모델의 아키텍처를 알고 접근할 수 있는 경우, 더 풍부한 형태의 supervised fine-tuning이 가능하다. Black-box KD가 교사 모델을 불투명한 함수로 다루는 것과 달리, White-box KD는 teacher 모델의 output logit뿐만 아니라 중간 활성값, 은닉층, 심지어 attention 가중치까지도 학습에 활용한다.

Torchtune - KD Recipe
Torchtune은 Post-training을 쉽게 구현할 수 있는 라이브러리로, SFT, KD, DPO, PPO, GRPO, quantization-aware training 등 다양한 학습 레서피를 제공한다. Knowledge Distillation의 경우, LoRA / QLoRA 방식의 학습을 지원한다.
| Type of Weight Update | 1 Device | >1 Device | >1 Node |
| Full | ❌ | ❌ | ❌ |
| LoRA/QLoRA | ✅ | ✅ | ✅ |
Torchtune으로 Llama3.1-8B를 Llama3.2-1B로 distillation하기
KD에서는 teacher 모델의 토큰 단위 확률분포를 student 모델이 모사할 수 있도록 손실함수를 설정한다.
이때 total loss는 여러 가지 방법으로 구성할 수 있다. Torchtune의 기본 KD 구성은 cross-entropy(CE) loss와 표준적인 KD 접근 방식에서 사용되는 forward Kullback-Leibler(KL) loss를 결합하여 사용한다. forward KL divergence는 student의 분포를 모든 teacher의 분포와 일치하도록 강제함으로써 차이를 최소화하는 것을 목표로 합니다. 그러나 student 분포를 전체 teacher 분포에 맞추는 것은 효과적이지 않을 수 있기 때문에, MiniLLM, DistiLLM, Generalized KD와 같은 여러 논문에서 이러한 한계를 해결하기 위해 새로운 KD 손실을 소개하고 있다.

▶ forward KL Loss의 구현
import torch
import torch.nn.functional as F
class ForwardKLLoss(torch.nn.Module):
def __init__(self, ignore_index: int = -100)
super().__init__()
self.ignore_index = ignore_index
def forward(self, student_logits, teacher_logits, labels) -> torch.Tensor:
# Implementation from https://github.com/jongwooko/distillm
# teacher logit의 softmax를 계산함
teacher_prob = F.softmax(teacher_logits, dim=-1, dtype=torch.float32)
# student logit의 softmax를 계산함
student_logprob = F.log_softmax(student_logits, dim=-1, dtype=torch.float32)
# KL divergence 계산
prod_probs = teacher_prob * student_logprob
# 토큰 단위로 divergence 합산
x = torch.sum(prod_probs, dim=-1).view(-1)
# ignore된 label에 대해서는 손실을 계산하지 않기 위해 mask 생성
mask = (labels != self.ignore_index).int()
# non-ignored targets에 대한 평균이 Loss로 활용됨
return -torch.sum(x * mask.view(-1), dim=0) / torch.sum(mask.view(-1), dim=0)
기본적으로 KD 구성은 메모리를 줄이기 위해 ForwardKLWithChunkedOutputLoss를 사용한다. 현재 구현은 동일한 출력 로짓 shape와 동일한 토큰라이저를 가진 teacher와 student 모델에 대해서만 지원된다.
✔ KD Training Recipe 예시
KD는 teacher model이 타겟 데이터에 대해 fine-tuning이 되어 있을 때 더 잘 작동한다.
따라서 teacher model인 Llama-3.1-8B 모델을 LoRA로 fine-tuning한 후, 해당 모델을 student인 Llama-3.2-1B에 distillation하였다.
✔ KD Ablation Study 결과
해당 블로그에서는 LoRA로 fine-tuning된 8B 교사 모델과 기본 1B 학생 모델을 사용했지만, 다양한 구성과 하이퍼파라미터를 사용하여 실험을 해볼 수 있다. 따라서 alpaca_cleaned_dataset에 대해 파인튜닝을 수행하고, EleutherAI의 LM evaluation harness 프레임워크를 활용해 truthualqa_mc2, hellaswag, 그리고 commonsense_qa alpaca에 대해 평가를 수행하여 아래와 같은 변형에 대한 효과를 알아본다:
1. fine-tuning된 teacher model의 사용
2. fine-tuning된 student model의 사용
3. KD loss ratio 및 learning rate 하이퍼파라미터 튜닝의 효과
🧪 기본 셋팅
- GPU: A100 80GB GPU 1개
- Teacher: Llama-3.1-8B-Instruct 모델을 다운스트림 태스크에 대해 LoRA fine-tuning한 모델
- Student: Llama-3.2-1B-Instruct
- learning rate: 3e-4
- KD loss ratio: 0.5
1) Fine-tuning된 teacher model 사용
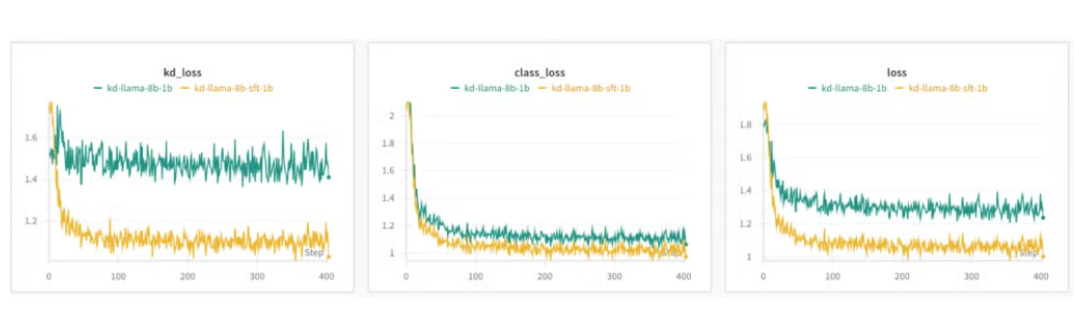
- Baseline llama-8B 모델을 사용한 KD의 loss가 fine-tuning된 llama-8B를 teacher model을 사용했을 때의 loss보다 큼
- KD loss의 경우, Baseline llama-8B를 사용했을 때 거의 상수로 유지됨
👉 Teacher model은 transfer하고자 하는 데이터셋과 같은 분포를 유지하는 것이 좋다는 것을 시사함

2) Fine-tuning된 student model 사용

- Student 모델이 fine-tuning되었든, fine-tuning되지 않았든 간에, teacher model이 fine-tuning된 경우의 loss가 더 낮음
- Fine-tuning된 student model을 사용할 경우, class loss는 오히려 증가하기 시작하는 것을 볼 수 있음
- 벤치마크 성능을 보면, fine-tuning된 student model을 사용할 때 truthfulqa의 정확도는 더 높아졌지만,
hellaswag와 commonsense 데이터에서는 정확도가 오히려 낮아짐
👉 Student model fine-tuning의 효과는 타겟 벤치마크에 따라 다름

3) Hyper-parameter tuning: learning rate

- 기본 learning rate는 3e-4로 설정되어 있음
- 1e-3 ~ 1e-5 사이의 learning rate를 변동하며 실험을 수행한 결과,
1e-5 learning rate를 설정했을 때 KD와 class loss가 더 높게 나타났지만 나머지 값에 대해서는 비슷했음 (batch size = 4)
4) Hyper-parameter tuning: KD ratio
- 전반적으로 KD ratio를 높일 때 성능이 조금 더 나아졌음

🧪 KD ratio 설정 관련 추가 Case Study
- Teacher 모델이 충분히 신뢰할만한 경우, KD loss 비중을 높이는 것이 좋은 결과로 이어질 수 있음
- KD를 제안한 Hinton의 원 논문에서도teacher의 soft label 학습에 90% 이상 비중을 두고,
lard label 학습 비중은 10% 이하로 두었을 때 성능이 높았다고 보고함 (논문)
- KD를 제안한 Hinton의 원 논문에서도teacher의 soft label 학습에 90% 이상 비중을 두고,
- KD ratio 뿐만 아니라 temperature scaling 파라미터도 조절이 가능함
- teacher 모델의 출력 확률분포는 한두개의 단어에 확률이 치우치고, 나머지는 거의 0에 가까운 경우가 있는데, 이 경우 student model이 얻을 수 있는 학습 신호가 제한적임
- 이를 완화하기 위해 teacher 모델의 softmax를 부드럽게 하는 방법을 적용할 수 있음
- torchtune에서는 해당 파라미터 설정을 찾아볼 수 없음..!
참고자료
- https://github.com/Tebmer/Awesome-Knowledge-Distillation-of-LLMs
- Distilling Llama3.1 8B into 1B in torchtune
- https://arxiv.org/pdf/2503.06072

'LLM > LLM Customization' 카테고리의 다른 글
| Model Compression Recipe - Generalized Knowledge Distillation (GKD) (1) | 2025.05.22 |
|---|---|
| Alignment Tuning Recipe - Direct Preference Optimization (DPO) (0) | 2025.04.30 |
| LLM 성능 향상을 위한 Post-training 방법론 개요 (0) | 2025.04.29 |
| ChatGPT Fine-tuning 예시 | 언제, 어떻게 해야 하는가 (25) | 2023.11.11 |