Gemini is built from the ground up for multimodality —
reasoning seamlessly across text, images, video, audio, and code.
Gemini는 텍스트, 이미지, 비디오, 오디오 및 코드를 자연스럽게 이해하는
multi-modality를 위해 만들어졌습니다

2023년 12월 6일, Google은 멀티모달 모델인 제미나이(Gemini)를 발표하며 범용 모델의 시대에 대한 포부를 밝혔다.
구글 딥마인드는 <인간이 세계를 이해하고 상호 작용하는 방식에서 영감을 받은> 새로운 세대의 AI 모델에 대한 비전이 있었다.
소프트웨어처럼 똑똑한 것이 아니라 유용하고 직관적인 것처럼 느껴지는 AI, 전문가적인 도우미나 어시스턴트 같은 AI말이다.
Gemini는 텍스트, 코드, 오디오, 이미지 및 비디오와 같은 다양한 유형의 정보를 이해하는 멀티모달 모델로 구축되었다.
뿐만 아니라 데이터센터부터 모바일장치까지 다양한 하드웨어에서 추론할 수 있는 유연성을 가지고 있다.
Gemini 1.0은 세 가지 사이즈로 발표되었다.
- Gemini Ultra - 가장 크고 가능성이 많은 모델로, 매우 복잡한 작업을 위한 모델
- Gemini Pro - 광범위한 태스크들에 대해 확장성 있는 best model
- Gemini Nano - On-device 작업에 적합한 효율적인 모델
언어 및 멀티모달 SOTA 성능
언어 태스크에 대한 State-Of-The-Art 성능 달성
● LLM 연구개발 벤치마크 32개 중 30개 태스크에 대해 SOTA 성능 달성
● MMLU(Massive Multitask Language Ultra) - 수학, 물리, 역사, 법률, 의학, 윤리 등 57과목에 대한 일반상식과 문제 해결 능력 테스트에서 90.0%의 달성을 달성, 인간 전문가를 능가한 첫 번째 모델

⚠ 성능 측정에 대한 논란
언뜻 다양한 도메인에 대한 멀티태스크 벤치마크인 MMLU에서 Gemini가 눈에 띄는 성능 향상을 이룬 것으로 보이나, Gemini의 성능인 90.04는 Chain of Thought라는 프롬프팅 기법을 사용한 '극대화된' 성능인 반면, GPT-4의 86.4% 정확도는 5-shot 추론 결과인 점이 논란이 되고 있다.
Chain of Thought는 문제를 풀 때 여러 단계의 추론 스텝을 거치며 정답을 추론하는 기법을 말한다. 리포트된 성적은 Gemini Ultra 모델로 32차례 Chain-of-thought을 통해 얻은 결과이다. 물론 GPT-4를 동일한 기법으로 추론한 결과인 87.29% 정확도보다도 Gemini의 점수가 더 높았던 것은 사실이나, 블로그에서 공개한 표는 동등 조건 비교가 아니다.

멀티모달 태스크
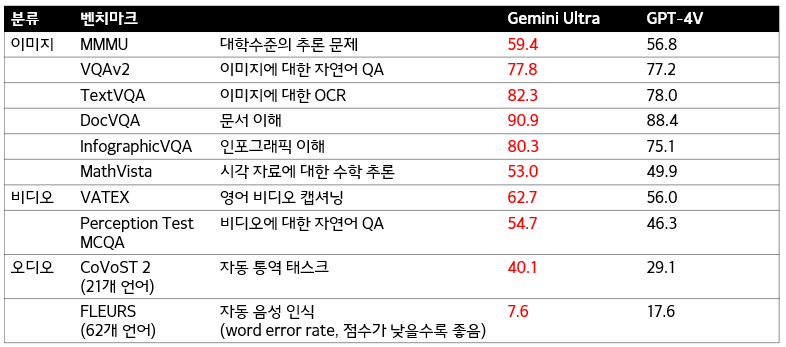
● 이미지, 비디오, 오디오 등 멀티모달 태스크에서는 기존 SOTA인 GPT-4V 능가
● 특히 추론이 필요한 다양한 도메인에 대한 멀티모달 태스크인 MMMU 벤치마크에서 SOTA 달성
● OCR 기술 없이 기존의 모델을 능가한 복합 추론 능력을 확인
차세대 기능
멀티모달 모델을 만드는 일반적인 방식은 각각의 modality에 대해 개별적인 컴포넌트를 학습한 후, 몇몇의 기능을 모방하는 방식으로 해당 컴포넌트를 엮는 것이다. 이러한 모델은 이미지를 설명하는 것과 같은 특정 태스크에는 잘 작동할 수 있지만, 더 개념적이고 복잡한 추론에는 어려움을 겪을 수 있다.
Gemini는 처음부터 멀티모달 능력을 습득할 수 있도록 다양한 modality에 대해 사전학습을 수행하였다. 이후 추가적인 멀티모달 데이터에 대해 fine-tuning 하여 그 효율성을 정제한 것이다. 이 과정으로 인해 Gemini는 자연스럽게 다양한 인풋을 이해하고 추론할 수 있게 되었고, 그 결과 모든 도메인에서 SOTA를 달성한 것이다.
● 정교한 추론 능력
Gemini1.0의 정교한 멀티모달 추론 능력은 방대한 데이터 속에서 식별하기 어려운 지식을 찾아냄에 있어 특별한 능력을 발휘하며, 읽기 - 필터링 - 추론 능력을 통해 수십만 개의 문서에서 인사이트를 추출하는 능력은 과학과 금융 등 다양한 분야에서 새로운 돌파구를 제공할 것으로 기대한다.
● 텍스트, 이미지, 오디오, 그리고 그 이상을 이해하는 능력
Gemini1.0의 정교한 멀티모달 추론 능력은 방대한 데이터 속에서 식별하기 어려운 지식을 찾아냄에 있어 특별한 능력을 발휘하며, 읽기 - 필터링 - 추론 능력을 통해 수십만 개의 문서에서 인사이트를 추출하는 능력은 과학과 금융 등 다양한 분야에서 새로운 돌파구를 제공할 것으로 기대한다.
● 개선된 코딩 능력
파이썬, 자바, C++, 바둑(?) 등의 프로그래밍을 언어로 이해하고, 설명하고, 고품질 코드를 생성할 수 있다.
제미나이 사용하기
● 구글 제품에 Gemini Pro 탑재
구글 Bard에는 Gemini Pro의 fine-tuning된 버전이 탑재되었다. 이 업그레이드는 바드 출시 이후 가장 큰 업데이트이며, 현재는 영어 버전으로만 170개 이상의 국가에서 제공 중이다.
또한 구글 픽셀폰에 Gemini를 탑재할 예정이다. 픽셀 8 프로에는 Gemini Nano를 실행할 수 있도록 설계된 최초의 스마트폰이다. 이를 활용하여 녹음 앱에서 요약과 같은 기능을 사용할 수 있도록 하고, 왓츠앱, 라인, 카카오톡을 시작으로 Gboard를 통해 스마트 답변 기능을 하도록 예정되어 있다.
앞으로 몇 달 안에 검색, 광고, 크롬 및 듀엣 AI와 같은 더 많은 제품 및 서비스에 제미나이를 적용할 예정인데, 이미 Gemini in Search를 통해 실험을 시작하고 있습니다. SGE(Search Generative Experience)를 통해 사용자가 보다 빠르게 사용할 수 있도록 하고 있으며, 미국에서는 영어 지연 시간이 40% 감소하고 품질이 향상되었다고 한다.
● Gemini 사용하기
개발자 및 기업 고객은 현재 Google AI Studio 혹은 구글 클라우드 Vertex AI에서 Gemini Pro API를 활용할 수 있다.
또한 안드로이드 개발자들은 픽셀 8 프로 기기부터 안드로이드 14에서 사용할 수 있는 새로운 시스템 기능인 AI코어를 통해 온디바이스 작업 모델인 Gemini Nano를 통해 구축이 가능하다. 이는 AICore Preview에 가입해서 활용해볼 수 있다.
● Gemini Ultra 공개 예정
Gemini Ultra 개발을 위해 현재 Red Teaming을 통해 신뢰성 및 안정성 검사를 하고 있으며, RLHF를 통한 강화학습을 통해 모델을 좀 더 개선하여 공개할 예정이라고 한다. 2024년 초에 공개 예정이라고 한다.
구글 블로그 포스트 >> https://blog.google/technology/ai/google-gemini-ai/
글쓴이 생각 👉
Gemini는 기저에서부터 멀티모달 능력을 가지고 있다는 점에서 GPT-4 vision 등 다른 서비스와 차별점이 있다. GPT-4V의 모델 구조나 파라미터 등이 밝혀지지는 않았지만, 사전학습된 비전 트랜스포머 계열 모델과 이미 잘 학습된 GPT-4 모델을 결합하여 만들어진 것으로 추측된다.
하지만 제미나이는 < 처음부터 > 언어, 이미지(비디오), 오디오 인풋을 받아들여 생각하도록 학습하였다는 표현을 사용하였다. 물론 기존에 구글이 가지고 있던 비전, 오디오, 언어 모델의 파라미터를 재활용했을 수도 있지만, 마치 우리가 시각, 청각 등 다양한 감각 기관으로부터 들어온 정보를 '태초에 동시에' 인식했던 것과 같이 작동하도록 같은 인풋-아웃풋 파라미터를 사용하는 것일까 하는 궁금증과 기대가 생긴다.
제미나이는 다양한 언어, 멀티모달 벤치마크에서 놀라운 성능을 보여주었고, 실제로 영상을 보며 사용자와 음성으로 소통하는 데모 영상에서는 놀라운 추론 능력과 더불어 답변에 어울리는 UI까지 디자인하는 듯한 놀라운 모습을 보였다.
그러나 벤치마크 성능 테스트 과정이 불공정하게 이루어진 부분이 있고, 해당 데모는 실제로 비디오 인풋을 넣은 것이 아니라 정지 영상의 시퀀스를 입력받은 것이며, 속도 역시 조절한 것이어서 그 성능이 과장되었다는 논란이 있다. OpenAI에서 계속적으로 뛰어난 모델을 발표함에 있어 구글이 자칫 조급한 횡보를 하고 있는 것이 아닌가 우려되는 부분이다. Gemini 공개 이후 시간이 꽤 많이 지났지만, 초반의 과대광고 논란 이후 특별한 피드백이 더 이상 보이지 않는 것도 아쉽게 느껴진다.
제미나이의 발표는 성급했을 수 있고, 베타 서비스에서도 아마 수많은 fail-case를 보일 것이다. 그럼에도 불구하고 from-scratch 멀티모달 모델이 '탄생'하여 모달리티간의 시너지를 보여주며 계속적인 발전이 가능한 시드를 확보했다는 점, 엣지 추론이 가능한 모델을 개발하여 픽셀폰 사용자들과의 상호작용을 통해 더 많은 피드백을 받을 수 있다는 점에서 제미나이는 성장의 잠재력을 가지고 있다고 기대한다. 인간에게도, 그리고 끊임없이 학습하는 인공지능에게도 '실패'는 새로운 성공의 가장 좋은 어머니이기 때문이다.

'LLM > Proprietary LLM & Services' 카테고리의 다른 글
| OpenAI GPT store 공개 - 내가 가진 아이디어로 노코딩 챗봇 개발 & 수익화하기 (34) | 2024.01.12 |
|---|---|
| GPT-4 : OpenAI의 '가장 진보된 AI 시스템' 공개 (0) | 2023.03.18 |
| ChatGPT: 진실되고 보다 이로운 답변을 생성하는, OpenAI의 GPT 시리즈 (2) | 2022.12.21 |
| AIaaS: 클라우드 AI 서비스 - 아마존, 마이크로소프트, 구글 개발자용 클라우드 AI 플랫폼 현황 (0) | 2020.03.27 |