원문 허깅페이스 - https://huggingface.co/docs/transformers/en/perf_train_gpu_one
모델 수렴과 GPU메모리를 고려하여 단일 GPU에서 메모리를 최적화하는 방법에 대해 HF에서 정리한 문서이다!
대규모 모델을 학습할 때에는 다음의 두 가지 측면을 고려해야 한다:
(1) 데이터 throughput 혹은 학습 시간
(2) 모델 성능
초당 학습 샘플 개수로 측정되는 throughput을 극대화하는 것은 학습 비용을 낮추는 것으로 연결된다.
일반적으로 GPU를 최대한 많이 사용하고, GPU 메모리를 그 한계까지 사용함으로써 이를 달성할 수 있다.
만약 배치사이즈가 GPU 메모리를 초과하면, gradient accumulation과 같은 메모리 최적화 방법을 사용할 수도 있다.
그러나 사용하고자 하는 배치 사이즈를 메모리에 올릴 수 있다면, 메모리 최적화 기법은 오히려 학습 속도를 늦추기 때문에 사용할 필요가 없다. 큰 배치 사이즈를 사용할 수 있다고 해서 꼭 큰 배치를 써야 하는 것은 아니기 때문이다. 하이퍼파라미터 튜닝의 일부로서 어떤 배치 사이즈가 최적의 결과를 낼 수 있는지를 결정해야 한다.
본 가이드에서 다루는 방법론과 도구는 학습 프로세스에 미치는 영향에 따라 아래와 같이 분류할 수 있다:
| 방법/도구 | 학습 속도 증대 | 메모리 사용 최적화 |
| 배치 사이즈 선택 | ✅ | ✅ |
| gradient accumilation | ❌ | ✅ |
| gradient checkpointing | ❌ | ✅ |
| mixed precision 학습 | ✅ | ❔ |
| 옵티마이저 선택 | ✅ | ✅ |
| 데이터 선 로딩 | ✅ | ❌ |
| DeepSpeed Zero | ❌ | ✅ |
| torch.compile | ✅ | ❌ |
| Parameter-Efficient Fine Tuning | ❌ | ✅ |
위의 방법론 중 여러개를 조합하여 사용하는 것도 물론 가능하다.
이 방법론들은 Huggingface Trainer을 사용하여 모델을 학습하거나 PyTorch 루프를 직접 작성하여 적용할 수 있고, 이 경우, Huggingface의 Accelerate를 활용하여 구현이 가능하다.
만약 언급된 방법으로도 충분히 속도 증대가 이루어지지 않는다면, 다음과 같은 방법을 생각해 볼 수 있다.
(1) 효율적인 software을 사전 구축해둔 커스텀 Docker 컨테이너 구축하기
(2) Mixture of Experts(MoE)를 사용하는 모델 고려하기
(3) 모델을 Better Transformer로 변환하여 PyTorch 본연의 attention을 사용하도록 하기
이 방법으로도 효과가 없을 경우, A100과 같이 더 좋은 사양의 GPU를 사용하거나 multi-GPU 환경을 사용할 것을 고려해야 한다. 여러 개의 GPU를 사용하는 상황에도 물론, 위 사항들은 유효하다.
배치사이즈 선택
모델 학습 속도와 메모리 활용의 효율성을 증대하기 위한 최적화 기법을 이해하기 위해,
최적의 성능을 얻기 위해 먼저 적절한 배치 크기를 식별해야 한다. 배치 크기와 입력/출력 뉴런 수는 크기가 2의 승수에 해당하는 것이 좋다. 8의 배수를 일반적으로 사용할 수 있지만, 사용 중인 하드웨어와 모델의 dtype에 따라 더 높은 숫자를 선택하는 것이 가능하다.
General Matrix Multiplication(GEMM)에 포함되어 있는 fully connected layer에 대한 입력/출력 뉴런 수 및 배치 사이즈에 대한 해서는 NVIDIA의 권장 사항을 확인해보면 좋다.
Tensor Core Requirements는 dtype과 하드웨어를 기반으로 승수를 정의한다. 예를 들어 fp16 데이터의 경우 A100 GPU의 경우 64의 배수, 이외 GPU에서는 8의 배수를 권장한다.
작은 파라미터의 경우 Dimension Qualtization Effects를 고려할 수도 있다. 이는 타일링이 발생하는 지점이며, 올바른 승수를 사용하는 것이 상당한 속도 향상에 기여할 수 있다.
Gradient Accumulation
그래디언트 누적 방법은 전체 배치에 대해 그래디언트를 한 번에 계산하는 대신 더 작은 단위로 계산하는 것을 목표로 한다. 이 방식은 forward 및 backward pass를 수행하고 프로세스 중에 그래디언트를 누적하여 더 작은 배치에서 반복적으로 그래디언트를 계산하는 것을 포함한다. 충분한 그래디언트가 누적되면 모델의 optimization 단계를 수행한다. 그래디언트 누적을 사용하면 GPU의 메모리 용량에 의해 부과되는 한계를 넘어 유효 배치 크기를 늘릴 수 있디. 그러나 그래디언트 누적에 의해 추가로 도입된 순방향 및 역방향 패스는 학습 프로세스를 느리게 만들 수 있다는 점에 유의해야 한다.
Gradient_accumulation_steps 인수를 TrainingArguments에 추가하여 그라디언트 누적을 활성화할 수 있다:
training_args = TrainingArguments(per_device_train_batch_size=1,
gradient_accumulation_steps=4,
**default_args)
위 코드에서 유효 배치 사이즈는 4가 된다.
혹은 HF Accelerate를 사용하여 학습 루프 전체에 대한 제어가 가능한데, 이는 가이드 뒷부분에서 설명한다.
Gradient Checkpointing
배치 크기를 1로 설정하고 그래디언트 누적을 사용하더라도 일부 대규모 모델에서는 메모리 문제가 생길 수 있다.
메모리 저장이 필요한 다른 구성 요소도 있기 때문이다.
Backward pass 동안 그래디언트를 계산하기 위해 모든 activation을 forward pass에서 저장하면 메모리 오버헤드가 크게 발생할 수 있다. 하지만 대안으로 backward pass를 진행하는 동안 activation 값을 버린 다음 다시 필요할 때 수행하게 되면, 상당한 계산 부하가 걸리고 학습 프로세스의 속도를 늦출 것이다.
그래디언트 체크포인팅은 이 두 가지 접근 방식 사이의 절충점을 제공하고 계산 그래프 전반에 걸쳐 전략적으로 선택된 활성화를 저장하므로 activation의 일부만 그래디언트에 대해 다시 계산하면 된다.
그라디언트 체크포인팅을 사용하기 위해서는 해당 플래그를 TraningArguments에 전달하면 된다:
training_args = TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
**default_args
)
Gradient checkpointing은 메모리 효율성을 증가시킬 수 있으나, 학습 속도를 약 20%가량 저하시킨다.
Mixed precision training
혼합 정밀 학습은 특정 변수에 대해 더 낮은 정밀도의 수치 형식을 사용하여 모델의 계산 효율을 최적화하는 기법이다. 전통적으로 대부분의 모델은 변수를 표현하고 처리하기 위해 32비트 부동 소수점 정밀도(fp32 또는 float32)를 사용한다. 그러나 모든 변수가 정확한 결과를 얻기 위해 이 높은 정밀도 수준을 필요로 하는 것은 아니다. 특정 변수의 정밀도를 줄여 16비트 부동 소수점(fp16 또는 float16)과 같은 더 낮은 수치 형식으로 계산하면 계산 속도를 높일 수 있다. 이 접근 방식에서는 일부 계산이 반 정밀도로 수행되는 반면 일부 계산은 여전히 완전 정밀도를 사용하기 때문에 혼합 정밀 훈련이라고 부른다.
대부분의 혼합 정밀도 훈련은 fp16(float16) 데이터 유형을 사용하여 이루어지지만, 일부 GPU 아키텍처(Ampere 아키텍처 등)는 bf16 및 tf32(CUDA 내부 데이터 유형) 데이터 유형을 제공한다. 이러한 데이터 유형 간의 차이점에 대한 자세한 내용은 NVIDIA Blog를 통해 확인할 수 있다.
BF16
Ampere 이상의 하드웨어에서는 bf16을 사용해 혼합 정밀도 학습 및 평가를 할 수 있다. bf16은 fp16보다 정밀도가 떨어지지만 동적 범위는 훨씬 크다. fp16에서 가질 수 있는 가장 큰 수는 65535이며 그 이상의 수는 오버플로우를 일으킨다. bf16 수는 fp32와 거의 동일한 3.39e+38(!)만큼 가질 수 있는데, 둘 다 수치 범위에 사용되는 8비트를 가지고 있기 때문이다.
BF16은 HF Trainer에서 활성화할 수 있다:
training_args = TrainingArguments(bf16=True, **default_args)
TF32
Ampere 하드웨어는 tf32라는 데이터 형식을 사용한다. fp32(8비트)와 같은 숫자 범위를 갖지만 23비트 정밀도 대신 10비트(fp16과 동일)만 사용하며, 총합 19비트 만을 사용한다. 일반 fp32 훈련 및/또는 추론 코드를 사용할 수 있고 tf32 지원을 활성화하면 최대 3배의 처리량 향상을 얻을 수 있다는 점에서 "magical"하다. 코드에 다음을 추가하기만 하면 된다:
import torch
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
CUDA는 사용된 Ampere 시리즈 GPU를 사용할 경우, 자동으로 fp32 대신 tf32를 사용한다.
엔비디아의 연구에 따르면, 머신 러닝 트레이닝 워크로드의 대부분은 fp32와 마찬가지로 tf32 트레이닝과 동일한 복잡도와 수렴성을 보인다. 이미 fp16 또는 bf16 혼합 정밀도를 사용하고 있다면 throughput에 도움이 될 수 있다.
TF32는 HF Trainer에서 활성화할 수 있다:
TrainingArguments(tf32=True, **default_args)
tf32는 내부 CUDA 데이터 유형이기 때문에 tensor.to (dtype=torch.tf32)을 통해 직접 액세스할 수 없다.
tf32 데이터 유형을 사용하려면 torch>=1.7이 필요하다.
Flash Attention2
트랜스포머에서 Flash Attention2를 사용하면 학습 throughput을 높일 수 있다. Flash Attention 2 모듈로 모델을 로드하는 방법에 대해 자세히 알아보려면 단일 GPU 섹션의 해당 섹션을 확인하십시오.
Optimizer 선택
트랜스포머 모델을 훈련하는 데 사용되는 가장 일반적인 옵티마이저는 Adam 또는 AdamW(Adam with weight decay)이다. Adam은 이전 그래디언트의 롤링 평균을 저장하여 수렴성이 좋지만, 모델 매개변수 수만큼 메모리 사용량을 추가한다. 이를 해결하기 위해 다른 옵티마이저를 사용할 수 있다 - 예를 들어, NVIDIA GPU용 NVIDIA/apex 또는 AMD GPU용 ROCm SoftwarePlatform/apex가 설치되어 있다면 adamw_apex_fused는 지원되는 모든 AdamW 옵티마이저 중 가장 빠른 학습을 제공한다.
허깅페이스 Trainer은 즉시 사용할 수 있는 다양한 옵티마이저를 제공한다.
(adamw_hf, adamw_torch, adamw_torch_fused, adamw_apex_fused, adamw_anyprecision, adafactor, adamw_bnb_8bit)
옵티마이저 중 adafactor와 adamw_bnb_8bit에 대해 조금 더 상세히 알아보자. google-t5/t5-3b와 같은 3-B 파라미터 모델에서
- 일반적인 AdamW 옵티마이저는 파라미터 당 4byte 메모리를 필요로 하기 때문에 24GB GPU 메모리가 필요하다
- Adafactor은 12GB보다는 많은 메모르가 필요하다. 파라미터 당 4byte보다 조금 더 많은 메모리가 필요하기 때문이다.
- Adafactor은 weight matrix에 있는 각 요소에 대한 롤링 평균을 저장하지 않는 대신, 집계된 정보(rolling average의 행과 열의 합)만 유지하기 때문에 footprint가 상당량 감소한다. 단, AdamW 옵티마이저에 비해 수렴 속도가 느린 경우가 있다.
- adamw_bnb_8bit의 퀀타이즈된 옵티마이저는 모든 옵티마이저 state가 양자화될 경우, 6GB의 메모리만 필요로 한다.
- 8-bit Adam은 Adafactor와 같이 옵티마이저 상태를 집계하는 대신, 전체 상태를 양자화하여 저장한다. 양자화는 state를 더 낮은 정밀도로 저장하고, optimization을 위해서만 역양자화를 진행한다.
Data preloading
학습 속도를 최적화하기 위해서는 GPU가 처리할 수 있는 최대 속도를 공급하는 능력이다. 기본적으로 모든 것이 main process에서 발생하며, 디스크에서 데이터를 충분히 빨리 읽지 못하면 병목 현상이 발생하여 GPU 활용도가 떨어진다. 이러한 병목을 줄이기 위해서는 다음과 같은 인수를 구성하는 것이 좋다:
- DataLoader(pin_memory=True, ...) - 데이터가 CPU의 고정 메모리에 미리 로드되고 일반적으로 CPU에서 GPU 메모리로 훨씬 더 빠르게 전송된다.
- DataLoader(num_workers=4, ...) - 여러 worker에 데이터를 할당하여 더 빠르게 데이터를 사전 로드한다. 학습 중에 GPU 사용률 통계를 보고 100%와 거리가 멀면 작업자 수를 늘리는 것을 고려해 볼 만하다. (물론 문제가 다른 곳에 있을 수 있기 때문에 더 많은 worker가 더 좋은 성능으로 이어지지는 않을 수 있다)
Trainer을 사용할 경우, TrainingArguments에서 dataloader_pin_memory는 default로 True이고, dataloader_num_workers는 default로 0을 가진다.
DeepSpeed ZeRO
DeepSpeed는 HF Transformers 및 HF Accelerate와 통합된 오픈 소스 딥러닝 최적화 라이브러리로, 대규모 딥러닝 학습의 효율성과 확장성을 향상시키기 위해 설계된 광범위한 기능과 최적화를 제공한다.
모델을 단일 GPU에 올릴 수 있고 작은 배치 크기에 맞는 충분한 공간이 있다면 DeepSpeed를 사용할 필요가 없다. 그러나 모델이 단일 GPU에 적합하지 않거나 작은 배치조차 학습할 수 없다면 DeepSpeed ZeRO + CPU Offload 또는 NVMe Offload를 사용하여 훨씬 더 큰 모델을 사용할 수 있다. 이 경우 라이브러리를 별도로 설치한 다음 가이드 중 하나를 따라 구성 파일을 만들고 DeepSpeed를 실행해야 한다:
- Trainer와 DeepSpeed 통합하기 - 가이드 참고
- Accelerate DeepSpeed 가이드를 참고하여 구현
torch.compile 사용하기
PyTorch 2.0은 기존 PyTorch 코드를 수정할 필요가 없지만 한 줄의 코드(model = torch.compile(model))를 추가하여 코드를 최적화할 수 있는 새로운 컴파일 기능을 도입하였다.
training_args = TrainingArguments(torch_compile=True, **default_args)
Torch.compile은 파이썬의 frame evaluation API를 사용하여 기존 PyTorch 프로그램에서 자동으로 그래프를 만든다. 그래프를 캡처한 후 다양한 백엔드를 배포하여 최적화된 엔진으로 그래프를 낮출 수 있다.
torch.compile에는 백엔드 리스트가 증가하고 있으며, 이 목록은 torchdynamo.list_backends (),를 호출하여 찾을 수 있다.
(각 백엔드에는 옵션별 종속성이 있다.)
HF PEFT 사용하기
PEFT(Parameter-Efficient Fine Tuning) 방법은 fine-tuning 중에 사전 훈련된 모델 파라미터를 동결하고 그 위에 소수의 훈련 가능한 파라미터(어댑터)를 추가한다. 결과적으로 옵티마이저 상태 및 그래디언트와 관련된 메모리가 크게 감소한다.
예를 들어 바닐라 AdamW의 경우 옵티마이저 상태에 대한 메모리 요구 사항은 다음과 같다:
- 파라미터들에 대한 fp32 copy: 파라미터당 4byte
- 모멘텀: 파라미터 당 4byte
- Variance: 파라미터당 4 byte
Low Rank Adapters를 사용하여 7B 파라미터 모델에 대해 2000만 개의 LoRA를 주입하여 모델을 학습하는 상황을 생각해 보자.
일반 모델의 옵티마이저 상태에 대한 메모리 요구 사항은 7B 파라미터 모델에 대해 12 * 7 = 84 GB다.
Lora를 추가하면 모델 가중치와 관련된 메모리가 약간 증가하고 옵티마이저 상태에 대한 메모리 요구량이 12 * 0.2 = 2.4GB로 크게 줄어든다.
HF Accelerate 사용하기
Accelerate를 사용하면 학습 루프를 완전히 제어하면서 위에서 언급한 방법들을 사용할 수 있으며, 약간의 수정을 통해 순수 PyTorch로 루프를 작성할 수 있다.
Training Arguments에서 다음과 같이 gradient_accumulation, gradient_chechpointing, FP16 학습을 세팅했다고 생각해 보자:
training_args = TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
fp16=True,
**default_args,
)
Accelarate에서는 다음과 같이 코드를 작성한다:
from accelerate import Accelerator
from torch.utils.data.dataloader import DataLoader
dataloader = DataLoader(ds, batch_size=training_args.per_device_train_batch_size)
if training_args.gradient_checkpointing:
model.gradient_checkpointing_enable()
accelerator = Accelerator(fp16=training_args.fp16)
model, optimizer, dataloader = accelerator.prepare(model, adam_bnb_optim, dataloader)
model.train()
for step, batch in enumerate(dataloader, start=1):
loss = model(**batch).loss
loss = loss / training_args.gradient_accumulation_steps
accelerator.backward(loss)
if step % training_args.gradient_accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
Mixture of Experts
Mixture of Expert를 트랜스포머 모델에 사용하면 학습 속도와 추론 속도를 4-5배 높일 수 있다고 발표된 바가 있다.
더 많은 파라미터를 사용하는 것이 더 좋은 성능으로 이어질 수 있기 때문에, 이 기법을 사용하면 학습 비용을 늘리지 않고도 파라미터를 몇 배 늘릴 수 있다.
MoE에서는 모든 FFN을 MoE 레이어로 대체하는데, MoE는 여러 전문가들로 구성되어 각 전문가는 일련의 입력 토큰 위치에 따라 균형 잡힌 방식으로 학습하는 게이트 기능을 가지고 있다.
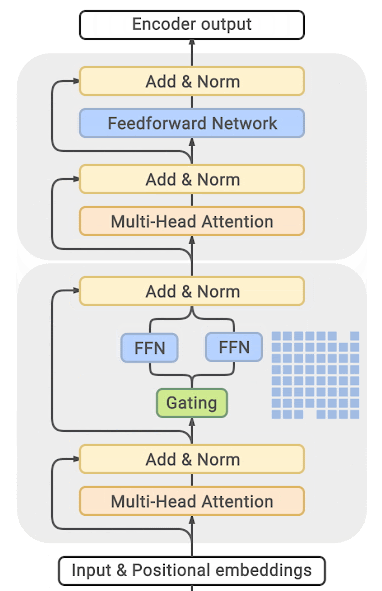
MoE 방식의 가장 큰 단점은 dense를 사용한 동일한 모델 대비 거의 10배 큰 엄청난 양의 GPU 메모리가 필요하다는 것이다. 이에 훨씬 더 높은 메모리 요구 사항을 극복하기 위해 대한 다양한 distillation 등 접근방식이 제안되었다.
이러한 trade-off가 있지만, 수십 혹은 수백의 전문가가 5배 작은 모델로 이어지는 대신 2-3배 작은 기본 모델을 가진 소수의 전문가만 사용할 수 있으므로 교육 속도를 적당히 높이면서 메모리 요구 사항도 적당히 늘릴 수 있다.
대부분의 관련 논문 및 구현은 Tensorflow/TPU를 중심으로 구축되어 있으나, PyTorch에서도 DeepSpeed-MoE가 구현되어 있다.
Pytorch native attention과 Flash attention 사용하기
PyTorch 2.0은 메모리 효율적인 attention과 flash attention과 같이 융합 GPU 커널을 사용할 수 있는 네이티브 torch.nn.functional.scaled_dot_product_attention(SDPA)를 출시했다.
optimum 패키지를 설치한 후에는 PyTorch의 native attention을 사용할 수 있도록 관련 내부 모듈을 교체할 수 있다:
model = model.to_bettertransformer()
한번 변환을 완료하면 일반적인 방법과 마찬가지로 모델을 사용할 수 있다.
PyTorch-native scale_dot_product_attention 연산자는 attention_mask가 제공되지 않은 경우에만 Flash Attention으로 디스패치할 수 있습니다.
기본적으로 학습 모드에서 BetterTransformer로 통합하는 경우, mask 사용을 드롭하며, 배치 학습에 패딩 마스크가 필요하지 않은 학습에만 사용할 수 있다. masked language model이나 causal language modeling이 이런 경우에 해당한다. BetterTransformer는 패딩 마스크가 필요한 작업의 모델을 fine-tuning 하는 데 적합하지 않다.

'AI' 카테고리의 다른 글
| Llama3 한국어 성능 테스트 | Colab에서 Meta-Llama-3 모델 사용해보기🦙 (0) | 2024.07.10 |
|---|---|
| [논문리뷰] SOLAR 10.7B: Scaling Large Language Models with Simple yet EffectiveDepth Up-Scaling (0) | 2024.03.17 |
| [Huggingface] 모델 학습 시 GPU 메모리 사용 알아보기 (2) | 2024.03.08 |
| Open-Ko-LLM | 한국어 대규모 언어모델 리더보드 (0) | 2024.02.16 |
| [논문리뷰] G-Eval: LLM을 사용해 인간의 견해와 보다 일치하는 NLG 평가 시스템 구축하기 (1) | 2024.02.11 |



