🙋♀️ tf.keras.applications 모듈에서 사전학습된 모델 불러와 fine-tuning하기
🙋♀️ Layer freezing / unfreezing 구현하기
TensorFlow에서 전이학습하기
From-scratch training vs Transfer Leraning
▶ From-scratch 학습
이전 글에서는 CNN 아키텍처를 만들어 TensorFlow에서 이미지 분류 모델을 학습하는 방법을 공부했다.
내가 디자인한 모델은 학습 데이터셋을 통해 weight를 조절하며 최종 태스크를 수행할 수 있는 representation을 학습하였다.
이렇게 모델의 파라미터를 랜덤하게 초기화하고, 데이터에 대해 모델을 학습시키는 것을 from-scratch 학습이라고 한다.
▶ Transfer Learning (전이학습)
하지만 사전학습된 모델에 대해 전이학습을 통해 최종적으로 수행하고자하는 모델의 성능을 높일 수 있다.
사전학습된 모델은 대량의 데이터셋에 대해 학습된 모델을 의미하는데, 일반적으로 비전 분야에서는 이미지넷 데이터를 학습한 모델을 의미한다. 대량의 일반적인 도메인의 데이터에 대해 충분히 학습된 모델은 시각적인 세계를 이해할 수 있는 일반적인 방법을 학습하고, 따라서 이렇게 미리 학습된 지식을 사용해 최종 모델의 성능을 높일 수 있다는 것이 아이디어이다.
이런 사전학습 모델을 사용하는 방법은 두 가지가 있다.
1. Feature Extraction
- 사전학습된 모델을 새로운 이미지 데이터에 대해 유의미한 feature을 뽑아내는 용도로 사용함
- 최종 태스크를 수행할 수 있는 classifier만을 더해 사적학습된 모델이 만든 feature map을 새로운 태스크 수행에 활용
- 이 방법은 전체 모델을 다시 학습할 필요가 없기 때문에 학습 비용 측면에서 유리하다.
2. Fine-tuning
- 사전학습된 모델의 윗부분 몇 개의 layer은 고정하지 않고, 새로 추가한 classifier과 더불어 학습함
- 모델의 밑단에서는 lower level representation을 학습하기 때문에 새로운 태스크에 대해서도 재학습할 필요가 없지만, 고차원의 representation을 배워야 하는 윗단 레이어는 최종 태스크에 대해 fine-tuning함으로써 높은 성능을 낼 수 있다는 아이디어
tf.keras.application
텐서플로우에서는 사전학습된 다양한 모델을 제공하고 있다:
https://www.tensorflow.org/api_docs/python/tf/keras/applications
Transfer Learning을 활용해 강아지와 고양이 분류 모델 만들기
* 이 내용은 TensorFlow에서 제공하는 transfer learning 실습 내용을 바탕으로 함
* 출처 | https://www.tensorflow.org/tutorials/images/transfer_learning
Step1. 데이터 다운로드 & 전처리
데이터셋을 다운로드한 후 train / validation 데이터 각각을 train_dataset / validation_dataset에 읽어온다.
import matplotlib.pyplot as plt
import numpy as np
import os
import tensorflow as tf
from tensorflow.keras.preprocessing import image_dataset_from_directory
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
train_dataset = image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
validation_dataset = image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)👉 학습 데이터는 강아지/ 고양이 사진 2,000장, 검증 데이터는 강아지/고양이 사진 1,000장을 포함

데이터셋에 테스트 데이터가 따로 없기 때문에, 검증 데이터셋 중 20%를 테스트 데이터로 떼어 놓고 실험한다.
val_batches = tf.data.experimental.cardinality(validation_dataset)
test_dataset = validation_dataset.take(val_batches // 5)
validation_dataset = validation_dataset.skip(val_batches // 5)
이제 buffered prefecthing을 사용해 I/O에 막힘 없이 이미지를 디스크에서 읽어올 수 있도록 한다.
AUTOTUNE = tf.data.AUTOTUNE
train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE)
validation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE)
test_dataset = test_dataset.prefetch(buffer_size=AUTOTUNE)
마지막으로 data augmentation을 통해 overfitting을 방지하고, 성능을 향상할 수 있도록 한다.
Data Augmentation은 레이어로 구성하여 model.fit을 통해 호출할 때 적용되도록 할 수 있다.
model.evaluate 혹은 model.predict 등 추론을 할 때에는 이런 augmentation layer은 활성화되지 않는다.
data_augmentation = tf.keras.Sequential([
tf.keras.layers.experimental.preprocessing.RandomFlip('horizontal'),
tf.keras.layers.experimental.preprocessing.RandomRotation(0.2),
])
Step 2. Transfer Learning 준비하기
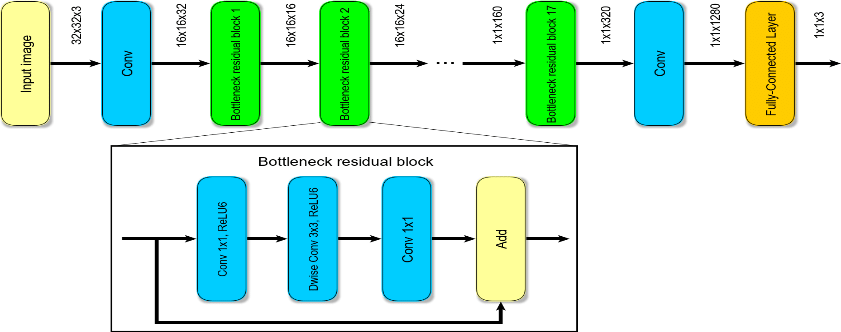
이 실습에서는 이미지넷 데이터에 대해 사전학습된 MobileNetV2를 활용한다.
ImageNet 데이터는 1000개의 카테고리에 대해 140만장의 이미지를 포함하는 라지 스케일 데이터셋으로, 이 데이터에 대해 사전학습된 모델은 다운스트림 태스크 수행에 있어 유용한 지식을 가지고 있을 것으로 기대한다.
모바일넷 v2는 픽셀 값이 [-1 , 1] 사이에 있는 인풋을 받는다. 하지만 현재 데이터셋은 [0,255]의 값을 가지고 있다. 따라서 현재 모델에 preprocessing을 추가해야 한다. 이러한 전처리를 위해서는 mobilenet_v2 모듈에서 제공하는 preprocess_input 매서드를 사용하거나, Rescaling 레이어를 사용해서 [0,255] 값을 [-1,1] 사이로 변환하는 레이어를 직접 만들어야 한다.
> mobilenet_v2 모듈 활용하기
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
> Rescaling 레이어 사용하기
rescale = tf.keras.layers.experimental.preprocessing.Rescaling(1./127.5, offset= -1)
다른 tf.keras.application에 있는 모델을 사용하더라도, API 문서를 참고해서 해당 모델이 어떤 스케일의 인풋을 받는지 확인해야 한다. 어떤 모델은 인풋 값을 [0,1]으로 정규화하기도 한다. 혹은 간단하게 preprocess_input 함수를 포함하는 것도 방법이다.
Step 3. 사전학습된 모델으로부터 베이스 모델 만들기
먼저, MobileNet V2의 레이어를 가지고 오되, 마지막 레이어를 제외하고 베이스 모델을 가지고 온다.
마지막 레이어는 ImageNet 데이터의 1000개 클래스 분류에 사용하는 레이어기 때문에, 현재의 다운스트림 태스크 수행에 불필요하다. 따라서 마지막 레이어를 제외한 모든 레이어를 가지고 온다. 이 작업은 tf.keras.applications에 있는 함수에서 include_top = False 를 통해 수행할 수 있다.
# Create the base model from the pre-trained model MobileNet V2
IMG_SHAPE = (160 , 160 , 3)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
이제 이 베이스 모델은 (160x160x3) 이미지를 인풋으로 받아 (5x5x1280) 블록 아웃풋을 만들어낸다.
image_batch, label_batch = next(iter(train_dataset))
feature_batch = base_model(image_batch)
print(feature_batch.shape)👉 (배치사이즈, 5, 5, 1280) = (32, 5, 5, 1280)
Step 4. 모델 학습하기
A) Feature Extraction : feature extractor 부분은 고정하고, 마지막 classifier만 학습
위에서 불러온 베이스 모델의 weight를 고정하려면 layer.trainable = False 옵션을 사용하면 된다.
base_model.trainable = False
* 주의 *
다수의 CNN 기반 모델은 BatchNormalization 레이어를 포함한다. 이 레이어에 대해 trainable = False를 설정하면, 이 레이어는 추론 모드에서 작동하고, 평균과 분산 통계량을 업데이트하지 않는다. 따라서 BatchNorm 레이어를 포함한 모델을 fine-tuning할 때에는, 이 BatchNormalization layer을 계속해서 추론 모드로 유지해야 한다 (base model을 호출할 때, training=False 옵션 사용) 이렇게 하지 않으면, 학습할 수 없는 weight에 업데이트가 가해져 모델이 학습한 것을 잊어버리는 결과가 생긴다.
참고 : https://www.tensorflow.org/guide/keras/transfer_learning
이제 base model이 아웃풋으로 내뱉은 블록에 대해 GlobalAveragePooling을 적용해 공간적인 정보를 풀링한 feature vector을 만드는 레이어를 적용할 것이다. tf.keras.layers의 GlobalAveragePooling2D 레이어를 선언한다.
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
feature_batch_average = global_average_layer(feature_batch)
print(feature_batch_average.shape)👉 (32 , 1280)
다음으로 위의 레이어에서 나온 1280차원 벡터를 다운스트림 태스크 분류 문제로 매핑하는 Dense Layer을 쌓는다.
강아지이면 1, 고양이이면 0을 예측하도록 하는 1차원 아웃풋을 예측하도록 하고, 아웃풋은 logit으로 취급한다.
prediction_layer = tf.keras.layers.Dense(1)
prediction_batch = prediction_layer(feature_batch_average)
print(prediction_batch.shape)👉 (32 , 1)
이제 지금까지 만든 Data Augmentation , Rescaling , base_model, Classification 레이어를 연결하여
Functional API를 사용하여 하나의 모델을 만든다.
inputs = tf.keras.Input(shape=(160, 160, 3))
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = global_average_layer(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = prediction_layer(x)
model = tf.keras.Model(inputs, outputs)
Loss 함수로는 BinaryCrossEntropy를 사용하고, Adam 옵티마이저를 사용해 모델을 컴파일한다.
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.Adam(lr=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])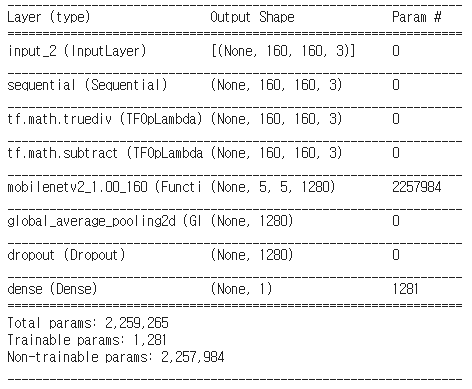
👉 만든 모델의 summary를 보면, 사전학습된 MobileNetV2의 feature extractor 부분은 학습되지 않고, 마지막 Dense Layer에 있는 파라미터만이 학습 대상인 것을 확인할 수 있다.
이제 model.fit 매서드를 사용해 10 에폭동안 모델을 학습해 보았다.
history = model.fit(train_dataset,
epochs=initial_epochs,
validation_data=validation_dataset)

👉 Validation 데이터에서 정확도가 94%정도까지 올라가도록 모델이 수렴했다.
👉 이때 학습 데이터에 대한 Loss나 정확도보다 검증 데이터에서 Loss가 더 낮고 정확도가 높은 것을 볼 수 있다. 이는 BatchNormalization이나 Dropout 레이어와 같이, 학습과 추론 중에 다르게 작동하는 레이어가 학습 중 정확도에 영향을 미치기 때문일 수 있다. 이 레이어들은 validation loss를 계산할 때에는 작동하지 않기 때문에 검증 metric에는 영향을 주지 않는다. 또한, 학습 중 metric은 에폭 중 평균으로 계산되지만 validation metric은 에폭 마지막에 계산되기 때문에, 좀 더 오래 학습한 모델의 결과만을 보여주기 때문에 이런 현상이 나타날 수 있다.
B) Fine-tuning
이번엔 고정했던 MobileNet 모델의 파라미터 중 위에 있는 레이어들을 unfreeze하고 학습한다.
사전학습된 모델 전체 파라미터를 고정하고 feature extractor로만 사용하는 것 보다는, 이렇게 상단 레이어를 함께 fine-tuning하면 모델 퍼포먼스를 향상시킬 수 있다.
base_model의 파라미터들을 학습 가능하도록 하고, 밑에서부터 N(=100)개의 레이어만 고정하도록 한다.
# Let's take a look to see how many layers are in the base model
print("Number of layers in the base model: ", len(base_model.layers))
# Fine-tune from this layer onwards
fine_tune_at = 100
# Freeze all the layers before the `fine_tune_at` layer
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = Falseimport pandas as pd
display_layers = [(layer, layer.name, layer.trainable) for layer in base_model.layers]
pd.DataFrame(display_layers, columns=['Layer Type', 'Layer Name', 'Layer Trainable'])
마찬가지로 정의된 모델을 컴파일하고, 모델을 학습해 보았다. 이때 A)에서 학습된 weight에 이어서 학습을 진행한다.
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer = tf.keras.optimizers.RMSprop(lr=base_learning_rate/10),
metrics=['accuracy'])
# 10 epoch동안 추가로 fine-tuning 진행
fine_tune_epochs = 10
total_epochs = initial_epochs + fine_tune_epochs
history_fine = model.fit(train_dataset,
epochs=total_epochs,
initial_epoch=history.epoch[-1],
validation_data=validation_dataset)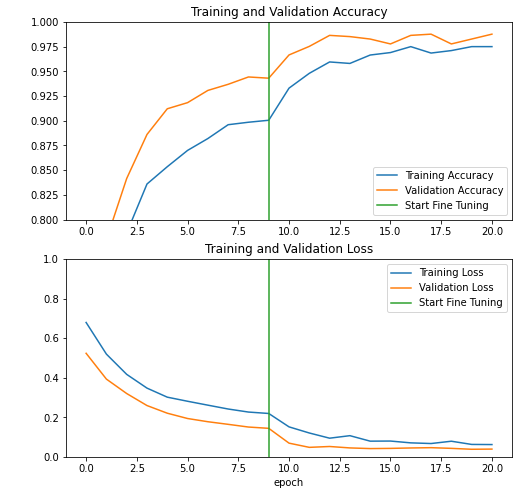
Step 5. 모델 평가 및 추론하기
테스트 데이터로 떼어놓은 데이터에 대해 모델 성능을 평가한다.
loss, accuracy = model.evaluate(test_dataset)
print('Test accuracy :', accuracy)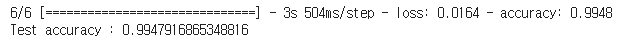
(참고) TensorFlow Functional API는 레이어의 흐름에 대해 자유롭게 그래프를 구성할 수 있음
IMG_SHAPE = (160,160,3)
base_model2 = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
output = base_model2.layers[-1].output
output = tf.keras.layers.Flatten()(output)
model2 = tf.keras.Model(base_model2.input, output)

'AI > DL Frameworks' 카테고리의 다른 글
| LangChain이란? | 파이썬으로 LangChain 시작하기 (3) | 2023.08.16 |
|---|---|
| [TensorFlow] Callback 사용하기 - 커스텀 콜백 / 모델 학습 / 평가 (0) | 2021.06.28 |
| [TensorFlow] Vision Modeling(1) MNIST 태스크 모델링하기 (2) | 2021.06.06 |
| [TensorFlow] 텐서플로우 2.0 기본 - Sequential & Functional API (0) | 2021.06.06 |
| 토치서브(TorchServe) - 파이토치 배포를 위한 모델 서비스 프레임워크 공개 (0) | 2020.04.28 |