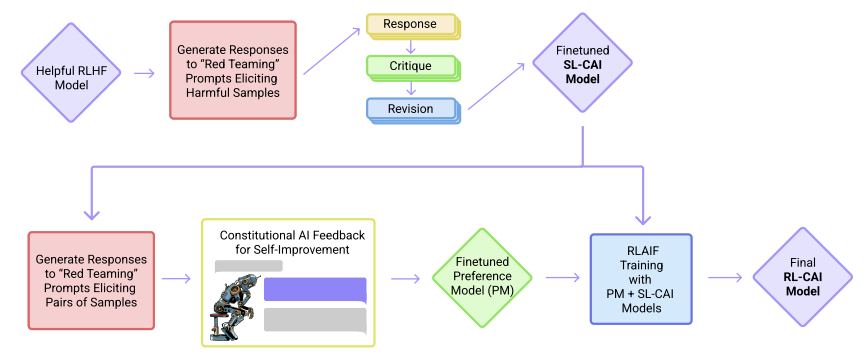
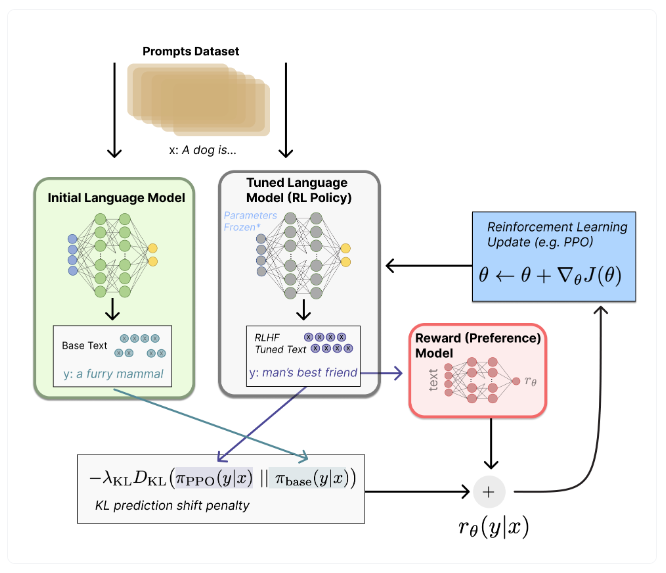
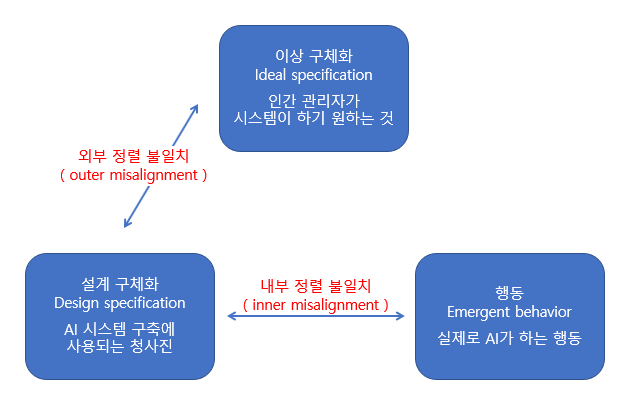
** Technical Report: https://arxiv.org/pdf/2501.12948DeepSeek-R1✔ 모델이 생각하여 추론하는 방법을 스스로 학습하도록 하기 위한 강화학습과 가독성 증대 및 사람 선호와의 일치를 위한 Fine-tuning 단계를 반복함으로써 OpenAI O1 모델에 비견할만한 모델을 학습했으며, 해당 모델을 오픈소스로 공개 ✔ DeepSeek은 R1 모델을 약 560만 달러 (약 80억 원)의 비용으로 훈련시켰다고 알려져 있으나, 과소 측정 논란이 있음 ✔ 671B 규모의 MoE 아키텍처를 사용하여 계산 효율성을 높이고 리소스 소비를 줄임 ✘ 데이터 Source, 도메인, 강화학습 단계에서 사용한 데이터 규모 등 학습 데이터의 Curation 방법 미공개 ✘ 영어, 중국어..