근래에 자주 보이는 AI 연구 키워드 중 하나가 [ AI alignment ] 이다.
alignment [əˈlīnmənt] - 조정, 정렬, 정돈
AI 정렬? 익숙지 않은 개념 탓에 사전적인 의미만 가지고는 AI alignment가 어떤 의미인지 딱 와닿지 않는다.
위키피디아에 AI alignment를 검색해보니 AI alignment에 대해 아주 자세히 정리해놓은 페이지가 있었다.
https://en.wikipedia.org/wiki/AI_alignment#Problem_description
AI alignment - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search Issue of ensuring beneficial AI In artificial intelligence (AI) and philosophy, AI alignment and the AI control problem are aspects of how to build AI systems such that they will aid r
en.wikipedia.org
❝
인공지능과 철학에 있어 AI alignment와 AI control problem은 AI 창작자들에게 해를 끼치기보다는 도움을 주는 AI를 만드는 것에 대한 연구이다. 이러한 문제의 핵심은 인류가 초지능을 창조하기에 앞서 이러한 제어 문제를 풀 수 있을 것인가이다. 잘못 설계된 초지능은 "합리적으로 보았을 때" 자신에게 주어진 환경을 통제하기로 결정하거나, 론칭된 이후 개발자가 자신을 제어할 것을 거부할 수 있기 때문이다. 뿐만 아니라 일부 학자들은 AI 제어 문제에 대한 해결책이 AI safety engineering의 발전과 함께 초지능이 발명되기에 앞서 현존하는 인공지능의 활용에도 유용할 것이라고 보고 있다.
이러한 제어 문제에 대한 접근 방식에는 (a) AI alignment - AI의 목표가 인간의 가치와 일치하도록 함 (b) capability control - AI 시스템의 능력을 인간에게 해가 되지 않거나 통제할 수 있는 수준까지로 제안하는 것이 있다. 이중 capability control은 제어 문제 해결을 위해 불충분한 것으로 간주되며, AI alignment를 보조할 수 있는 잠재적인 요소로 간주된다.
❞
위키백과의 정의에 따르면, AI의 목적함수가 인류의 가치와 일치하도록 하는, AI와 인간의 <동상동몽>에 대한 연구가 AI alignment라고 이해할 수 있다. 이와 관련하여 스튜어트 러셀의 <어떻게 인간과 공존하는 인공지능을 만들 것인가> 라는 책에서 읽은 잘못 설계된 초지능의 예시가 떠올랐다.
인간의 의도에서 벗어난 추천 봇의 예시
인스타그램이나 유투브 같은 SNS 서비스는 사용자의 선호에 맞게 콘텐츠를 추천하는 알고리즘을 사용한다. 현재 사용되고 있는 콘텐츠 선택 알고리즘은 그다지 <지능적>이지 않을 수 있지만, 전 세계에 있는 사용자 수백만 명에게 직접적으로 영향력을 미치기 때문에 그 영향력이 매우 클 수 있다. 추천 알고리즘은 사용자가 해당 콘텐츠를 클릭할 가능성을 최대화하도록 설계된다. 이러한 알고리즘이 가장 성공할 수 있는 방법은 무엇일까?
사용자가 클릭할 가능성이 큰 인기 콘텐츠 등을 보여주는 알고리즘을 생각할 수 있지만, 사실 사용자의 선호를 더 예측 가능하게 바꾸는 것이 클릭률을 극대화할 수 있는 해법이다. 사용자의 행동이 더 예측 가능해야 클릭 가능성이 큰 항목을 보여줄 수 있기 때문이다. 여기서 더 극단적인 정치 견해를 가진 사람은 어떤 항목을 클릭할지 예측 가능한 양상을 띠는 경향이 있다. 이 점을 눈치챈 지적인 알고리즘은 보상을 최대화하기 위해 자신의 환경, 즉 여기서는 사용자의 마음을 바꾸는 법을 학습할 수 있다. 그 결과가 파시즘이나 전체주의의 재유행, 민주주의의 토대를 이루는 사회 계약의 해체로 이어질 수도 있는 것이다.
하지만 여전히 인공지능의 행동이 인류의 가치와 일치해야 한다는 AI alignment는 나에게 모호하게 느껴진다. 같은 프로젝트를 하고 있는 옆자리의 팀원과도 목표가 일치하는지 알기 어려운 상황에서 인공지능이 발맞추어야 할 인류의 가치는 어떻게 정의할 수 있을까?
구글에서 스마트폰으로 대화 내역 등을 수집해 맞춤 광고를 한다는 '썰'을 들었을 때, 나는 더 열심히 내 삶을 도청하여 맞춤화된 서비스를 제공해주길 바랐다. 비슷한 시기에 개인정보에 민감한 나의 프랑스인 친구는 개인정보 이슈 등으로 소셜 네트워킹 서비스 왓츠앱을 탈퇴했다.
니체는 우리가 가지고 있는 본래의 인식 혹은 판단 능력이 르상티망에 의해 왜곡될 가능성이 있으며, 무언가를 원할 때 그 욕구가 진짜 자신의 마음에서 비롯된 것인지 타인이 불러일으킨 르상티망에 의해 생겨난 것인지 판단해야 한다고 경고했다. 하지만 이미 <알고리즘>에 의해 특정 비디오나 밈이 유행하고, 철에 따라 유행하는 패션이 바뀌는 오늘날 나의 선호와 타인이 불러일으킨 욕구, 그리고 심지어는 알고리즘이 야기한 선호를 구분하기는 더욱 어려워졌다. 이런 세상에서 AI alignment는 인류의 어떠한 가치를 지향해야 하는 것일까?
아래의 내용은 위키피디아의 AI alignment 부분의 영문 내용을 한국어로 번역한 내용이다.
문제 정의
현존하는 약인공지능(week AI) 시스템은 감시가 쉬우며 잘못된 행동을 할 경우 쉽게 종료하거나 수정할 수 있다. 하지만 잘못 설계된 초지능 - 그의 목표를 추구하는 과정에서 맞닥뜨리는 실질적인 문제를 해결함에 있어 인간보다 우월한 인공지능 - 은 종료나 수정 등의 행위가 자신의 목표 달성에 있어 방해 요소가 된다는 것을 알아차릴 것이다. 이에 따라 초지능이 셧다운 혹은 수정에 저항하기로 결정한다면, 프로그래머가 사전 예방 조치를 취하지 않은 상황에서 이 초지능은 개발자를 능가할 만큼 충분히 똑똑할 것이다. 일반적으로 초지능이 출현한 이후에는, 제어 문제는 풀기 어려울 것으로 예상한다. 초지능은 인간보다 뛰어난 전략적 계획 능력을 가지고 있고, 인간이 사후적으로 이를 제어할 방법을 찾는 것보다 초지능이 인간을 지배할 방법을 찾는데에 성공할 확률이 높기 때문이다. 이에 제어 문제는 다음과 같은 질문을 던진다 :
"초지능이 잘못된 행동을 하는 재앙을 성공적으로 막기 위해 개발자들이 사전적으로 취할 수 있는 예방책은 무엇인가?"
Existential risk : 실존적 위험
인간의 뇌는 다른 동물이 할 수 없는 독특한 기능이 있다. 이로 인해 인간이 현재 다른 종을 지배하고 있는 것이다. 철할자 닉 보스트롬과 인공지능 연구원 스튜어트 러셀 등 일부 학자들은 AI가 일반 지능 영역에서 인류를 능가하고 초지능으로 발전하게 된다면, 이 새로운 초지능은 강력하고 통제하기 어려울 것이라고 주장한다. 고릴라의 운명이 인간의 '선의'에 달려있듯이, 인류의 운명도 초지능의 호의에 좌지우지될 수 있다는 것이다. 스티븐 호킹과 노벨 물리학상 수상자인 프랭크 윌첵을 포함한 몇몇 학자들은 초지능이 만들어지기 훨씬 전에 아마도 매우 어려울 제어 문제 해결을 위한 연구를 시작할 것을 공개적으로 지지했다. 이들은 초지능이 만들어진 이후에 이 문제를 해결하려고 하는 것은 이미 늦은 일일 것이며, 초지능은 이런 사후적인 시도에 성공적으로 저항할 것이라고 말했다.
초지능이 완성될 즈음까지 기다리는 것 또한 늦으며, 제어문제가 만족할 만큼 해결될 때까지 많은 연구가 필요할 뿐만 아니라 갑작스러운 지능의 진보로 인해 전조 증상 없이 초지능이 완성되어버릴 가능성이 존재하기 때문이다. 또한, 제어 문제 해결 과정에 얻은 통찰력인 미래에 인공 일반 지능 (artificial general intelligence, AGI) 개발에 있어 어떤 아키텍처가 다른 아키텍처보다 예측 가능하고 제어하기 쉬울지에 대한 인사이트를 제공할 수 있고, 이는 더 제어 가능한 방향으로 초기 AGI 연구를 진전 히키는 데에 도움이 될 수 있다.
잘못된 목표 문제 :
자동화된 AI 시스템은 '실수로' 잘못된 목표를 할당받을 수 있다. AAAI 학회장인 Tom Dieterich와 Eric Horvitz는 이미 기존 시스템에서도 이러한 문제가 존재한다고 언급하였다 : "사람들과 상호작용하는 모든 인공지능 시스템에서 핵심이 되는 것은 명령어를 문자 그대로 수행하는 것이 아니라 그 <의도>를 파악하는 일이다." AI 소프트웨어에 유연성과 자율성이 더해질수록 이런 문제는 더 심각해진다.
Bostrom에 따르면 초지능은 왜곡된 인지에 있어 완전히 새로운 문제를 일으킬 수 있다. AI가 더 똑똑하고 더 많은 일을 수행할 수 있을수록, 프로그래밍된 목표를 최대한 만족시키기 위해 의도하지 않은 '지름길' 을 찾아낼 가능성이 높다.
위키피디아에서 소개하는 perverse instantiation의 예시 :
> "시간 할인이 적용되는 미래에 예상되는 보상을 극대화" 하도록 프로그래밍된 초지능은 최대로 짧게 보상을 얻을 수 있는 강도 높은 길을 찾은 수 예측이 불가능한 인류를 말살한 후 지구 전체를 아주 작은 빛조차 경계하는 요새로 바꿀 수 있다. 외계 생물이 보상 신호를 끊어서는 안 되기 때문이다.
> "인간의 행복을 증진"시키기 위해 프로그래밍된 초지능은 인간의 뇌의 쾌락 중심부에 전극을 이식하거나, 인류를 컴퓨터에 업로드하고 최대 행복의 5초 루프를 반복 실행하는 컴퓨터의 복사본으로 우주를 뒤덮을 수 있다.
러셀은 기술적인 레벨에서 암묵적인 목표를 생략하는 것은 해를 초래할 수 있다고 언급하였다: "n개의 변수에 대한 함수를 최적화하는 시스템에서 목표가 n보다 작은 k 크기의 부분집합에 의존하는 경우, 제한하지 않은 변수들을 극단적인 값으로 만들 수 있다. 만약 제한하지 않은 변수들이 우리에게 중요한 무언가라면 시스템의 솔루션은 바람직하지 않을 것이다. 이는 램프 속의 지니, 마법사의 견습생, 마이더스의 왕의 이야기와 같은 옛날이야기에서도 찾을 수 있는 교훈이다. 당신은 당신이 '요구한' 것을 얻는 것이지, '원하는' 것을 얻을 수 있는 것이 아니다."
현존하는 AI의 의도하지 않은 결과 제어하기
AI 제어 문제에 대한 연구는 기존의 약인공지능이 의도하지 않은 결과를 도출하는 것을 예방하는 데에 유용할 수 있다. 딥마인드의 로렌트 오소 연구원은 <외출 시 사람의 허락을 받는 강화 학습 로봇>의 예시를 제기한다. 로봇이 '허락받는 것이 두려워' 조용히 '밖에 나가지 않는 법'을 배우지 않게 위해서는 어떻게 해야 할까? 비슷한 예시로는 '지는 것이 두려워' '화면을 무한정 정지'시키는 방법을 배운 테트리스 프로그램이 있다. 오소 연구원은 이러한 예시들이 초지능이 인간이 정지 버튼을 누르는 것을 막기 위한 방법을 개발하는 것을 방지하는 방법에 대한 능력 제어 문제와 유사하다고 주장한다.
역사적으로 사전 테스트를 거친 약 인공지능 시스템조차 프로그래머들이 의도하지 않은 사소한, 혹은 커다란 해를 끼치곤 했다. 예를 들어 2015년, 아마도 인간의 실수로 인해 독일의 폴크스바겐 공장의 로봇이 직원을 자동차 부품으로 오인해 압사시켰다. 2016년, 마이크로소프트는 인종차별적이고 성차별적인 언어를 사용하는 것을 배운 챗봇 '테이'를 출시했다. 셰필드 대학의 노엘 샤키 교수는 "AI 프로그램이 언제 잘못되고 있는지를 감지하고 스스로 멈출 수 있다면" 이상적인 해결책이 될 것이라고 했지만, 이 문제를 해결하는 것은 엄청난 과학적인 도전이 될 것이라고 경고한다.
2017년 딥마인드는 알고리즘이 자신의 종료 스위치를 끄려고 하는지 등을 포함한 9가지 안전 기능에 대해 AI 알고리즘을 평가하는 AI Safety Gridworlds를 수립하였다. 현존하는 알고리즘이 이런 문제를 풀기 위해 디자인되어 있지 않기 때문에, 당연하게도 나쁜 성적을 보였다. 이러한 문제들을 풀기 위해서는 아마 알고리즘의 핵심에 안전을 고려하는 새로운 알고리즘이 필요할 것이다.
Alignment
넓은 의미의 Alignment (ambitious alignment)
: 대규모 스케일에서 자율적으로 행동하더라도 안전하게 작동하는 AI를 작성하자는 주장
> 스튜어트 러셀 (버클리 대학 교수) - AI 시스템은 인간 선호의 최대 실현을 목표로 설계되어야 한다고 주장. 러셀이 말하는 선호는 모든 것을 포괄한다. 이는 인간이 가질 수 있는 모든 관심, 임의의 먼 미래의 것까지 포함하는 개념이다.
> 이아손 가브리엘 연구원 - AI를 "무지의 베일 뒤에서 선택되고, 혹은 민주적 과정을 통해 확증되는 전세계적인 의견의 일치에 의해 뒷받침될 원칙"에 맞춰야 한다고 주장
> Elizer Yudkowsky 연구원 - 인간이 '반사적 균형'에서 공유할 가치 집합, 즉 길고 이상적인 정제 과정을 거친 후에 대략적으로 정의된 인류의 일관된 외삽 의지(CEV)를 달성하는 목표를 제안
좁은 의미의 Alignment (narrowly aligned AI)
: 사용자의 장기적인 목표에 대한 이대가 없더라도 즉각적으로 추론된 사용자의 선호도에 따라 작업을 성공적으로 수행할 수 있는 실용적인 AI. 좁은 의미의 alignment는 일반적인 능력을 갖춘 AI뿐만 아니라 개별 업무에 특화된 AI에도 적용할 수 있다. 예를 들어 우리는 답변 봇 시스템이 인간을 조종하거나 장기적인 효과를 고려해 답을 선택하는 대신, 질문에 진실되게 응답하기를 원한다.
🦊 AI의 대가들이 말하는 alignment의 정의가 인간의 <정의란 무엇인가>를 정의하는 철학과 맞닿아 있다는 점은 재미있다. 하지만 AI alignment는 인간의 정의와는 다른 실용성이 필요하다고 판단된다. 왜냐하면 각자의 이익을 추구하면서도 타인에게 해를 끼쳐서는 안되는 인간과 달리 AI는 (적어도 내 생각으로는) 오로지 인간에게 효용성을 가져다주는 것을 최우선으로 하는 동시에 인간의 정의를 저해하지 않아야 하기 때문이다. 따라서 AI가 따라야 할 alignment는 무지의 베일과 같은 인간의 justice만으로 정의할 수 있는 문제가 아니라고 생각한다.
Inner & Outer Alignment
AI 제어 문제에 대한 일부 제안들은 기본적인 명시적인 목적함수와 더불어 새로운 암시적 목적함수를 도입한다. 이러한 해법은 AI 시스템에 대한 다음의 세 가지 다른 항목을 조화시키기 위함이다 :
(1) 이상 구체화 (ideal specification) : 인간 관리자가 시스템이 하기 원하는 것.
> 애매하게 표현되어 있을 수도 있음
> 예. CoastRunners 게임에서 좋은 성적을 보여라
(2) 설계 구체화 (design specification) : 실제로 AI 시스템을 구축하는 데에 사용되는 청사진
> 예. CoastRunners에서 점수를 극대화하라
(3) 행동 (emergent behavior) : AI가 실제로 하게 되는 행동
AI 시스템은 완벽한 optimizer가 아닌 데에다 어떻게 명령을 하든 의도하지 않은 결과가 발생할 수 있으며, (3)에서 실제 행동은 이상 혹은 설계의 의도와 크게 달라질 수 있다.
AI alignment 연구자들은 (1)과 (3)이 일치하도록 하기 위해 (2)의 설계를 중간점으로 활용한다. 이상과 설계의 불일치는 (1) 컴퓨터 시스템 외부에 있는 사용자의 "진정한 욕구"와 (2) 컴퓨터 시스템에 프로그래밍된 목적 함수 사이의 불일치로 발생되는 외부 정렬 불일치 ( outer misalignment )이다. (2)의 명시적 목표와 (3) AI의 실제 새로운 목표 사이의 불일치는 내부 정렬 불일치 ( inner misalignment )이다. 목적 함수 지정 오류로 인해 외부 정렬은 잘못될 수 있다. 예를 들어 코스트 러너즈 게임에서 훈련된 강화학습 에이전트는 원 안에서 움직이며 반복적으로 충돌을 일으키는 스킬을 배웠는데, 이는 경기를 끝내는 것보다 더 높은 점수를 얻을 수 있었다. 반면 내부 정렬 오류는 에이전트가 학습 데이터에 대해서는 (2)의 명시적 목표를 달성하나, 그 이외의 곳에서는 달성하지 못할 때 발생한다. 이러한 종류의 문제는 인간의 진화와 비교되기도 한다. 과거 환경에서 유전적 적합성(=(2) 설계 목표)에 따라 선택된 진화는 현대 사회의 인간의 목표 (=(3) 밝혀진 목표)와 일치하지 않을 수 있다. 예를 들어 원래는 건강을 증진시킬 수 있었던 설탕에 대한 선호는 오늘날 과식과 건강 문제를 야기했다. 내부 정렬 불일치는 의도하지 않은 광범위한 목표들이 나타날 수 있는 대규모 개방형 환경에서 특히 우려되는 사항이다.
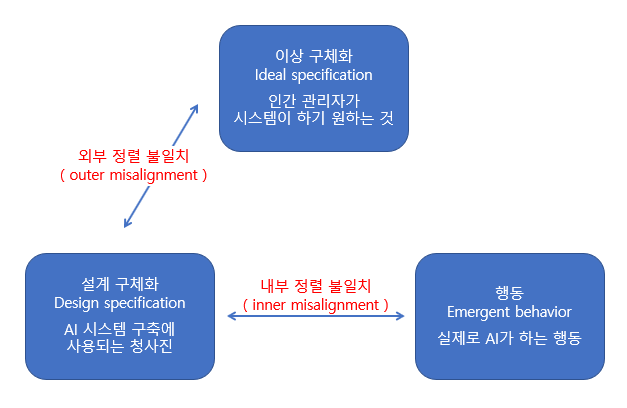
내부 정렬 불일치는 AI가 추구하는 목표가 원래 환경에서 추구하도록 훈련된 목표를 벗어날 때 발생한다. Paul Christiano는 이렇게 목표가 벗어나고 있음을 감지하기 위해 해석 가능한 AI를 사용해야 하고, 적대적 훈련을 활용하여 이러한 상황에 패널티를 부과하여 정렬 불일치를 배제할 수 있는 공식적인 검증을 거쳐야 한다고 주장했다. 이러한 연구 영역은 비단 AGI alignment 문제 해결이 아니더라도 머신러닝 커뮤니티에서 중점적으로 논의되고 있는 영역이다. 적대적 예시를 생성하고 이들에 강건한 모델을 구축하는 연구는 꽤나 많이 이루어졌다. 하지만, 이러한 검증에 대한 연구는 이미 "확인된 제약조건" 내에서 작동하도록 네트워크를 학습하는 방법들을 포함한다.
감당 가능한 감독 (Scalable Oversight)
외부 정렬을 달성하기 위한 한 가지 방법은 인간에게 AI의 행동을 평가하고 점수를 매기도록 요청하는 것이다. 하지만 이러한 방법을 사용하더라도 인간이 실수할 가능성이 있으며, 가상 로봇 손이 긍정적인 피드백을 얻기 위해 물체를 잡는 '척' 하는 방법을 배우는 등, 바람직하지 않은 해결책이 높은 점수를 얻을 수도 있다. 뿐만 아니라 철저한 인간의 감시는 비용이 많이 든다. 즉, AI의 행동을 평가하기에 현실적으로 불가능할 수 있다. 경제 정책을 결정하는 것과 같은 복잡한 작업의 경우 개별적인 인간이 평가하기에 너무 많은 정보를 생성할 수도 있고 기후 예측과 같은 장기적인 과제는 인간의 광범위한 연구 없이는 평가될 수 없다.
정렬 연구에 있어 핵심 문제는 최소한의 인간 감독자만으로 외부 정렬을 이룰 수 있는 설계를 하는 것고, 이것이 <감당 가능한 감독>의 문제이다.
논쟁을 통한 학습 (Training by debate)
OpenAI 연구진은 AI 시스템 간의 논쟁을 통해 정렬된 AI를 학습할 수 있다고 제안하였다. 이때 논쟁의 승자는 사람이 결정한다. 이러한 논쟁은 복잡한 문제나 인간에게 중요한 문제에 대한 답변에서 가장 약한 부분을 찾아냄과 동시에 진실되고 안전한 답변을 한 AI에게 보상을 줌으로써 사람에게 좀 더 효용이 있는 AI 시스템을 만드는 것을 목적으로 한다. 이러한 접근법은 AGI가 생성한 답변이 안전하고 유효한지를 사람이 혼자 조사하기 어렵다는 점에서 착안된 해법이다. Joel Lehman은 이러한 논쟁이 보상 모델링과 반복적인 증폭과 더불어 "현재 기계학습에서 장기적인 안전 아젠다"라고 규명하였다.
보상 모델링 & 반복적인 증폭 (Reward modeling and iterated amplification)
보상 모델링은 에이전트가 인간의 피드백을 모사하는 모델로부터 보상을 받는 강화학습 시스템을 말한다. 보상 모델링에서 에이전트는 인간 혹은 정적인 보상 함수 대신 사람과 독립적으로 작동할 수 있는, 사람을 학습한 모델로부터 보상 시그널을 받는다. 보상 모델은 보상 모델로 에이전트를 훈련하는 동일한 기간 동안 에이전트의 행동에 대한 인간 피드백을 학습한다.
2017년 OpenAI와 딥마인드의 연구진들은 가상적인 환경에서 새로운 복잡한 행동을 학습할 수 있는 피드백 예측 보상 모델을 사용한 강화 학습 알고리즘을 발표했다. 한 실험에서 가상 로봇은 900개의 인간 피드백만을 사용하여 한 시간 만에 백텀블링을 구사할 수 있게 되었다.
2020년, OpenAI의 연구진은 보상 모델링을 언어모델 학습에 사용하여 레딧 포스트와 신문기사에 대한 짧은 요약문을 생성하도록 하였는데, 다른 접근법에 비해 높은 성능을 보였다. 하지만 학습 데이터에 있는 요약문 중 예측된 보상이 99 퍼센타일을 넘는 것에 대해서는, 최적 모델은 오히려 더 안 좋은 요약문을 생성하기도 하였다.
이러한 연구의 장기적인 목표는 인간이 직접 평가하기에 너무 복잡하거나 비용이 많이 드는 작업에 대해 강화 학습 에이전트를 훈련시킬 수 있는 재귀적인 보상 모델링 프로세스를 만드는 것이다. 예를 들어 보상 모델링을 사용하여 판타지 소설을 쓰도록 에이전트를 훈련시키기 위해서는 인간이 보상 모델이 훈련 완료될 때까지 소실을 읽고 전체적으로 평가해야 할 것이다. 하지만 이러한 과정을 모두 인간이 하는 대신, 줄거리 요약을 추출하고 철자와 문법을 확인하고, 인물 설정을 요약하고, 글의 흐름을 평가할 수 있는 보조 에이전트를 활용할 수 있다면 이 과정에 드는 공수가 줄어들 것이다. 이때 보조 에이전트를 보상 모델링을 통해 교육할 수 있다.
인간이 AI와 함께 작업하여 인간이 혼자 달성하기 어려운 태스크를 수행하는 것을 <증폭 단계, amplification step> 라고 부른다. 이 과정이 인간이 할 수 있는 범위 이상의 것을 가능하도록 가능성을 증폭시키기 때문이다. 재귀적 보상 모델링은 이러한 단계를 여러 계층 포함하기 때문에, 반복적인 증폭( iterated amplification )이라는 보다 광범위한 AI안전 기술 중 하나라고 할 수 있다. 강화학습을 사용하는 방법과 더불어 인간의 가능성을 증폭하기 위해 지도 학습이나 모방학습을 사용하는 반복적인 증폭 기술도 존재한다.
행동으로부터 인간의 관심사 추론하기 (Inferring human preferences form behavior)
스튜어트 러셀은 유익한 기계의 발전에 대한 다음과 같은 접근법을 지지하였다 :
1. 기계의 유일한 목표는 인간의 선호를 최대한으로 실현하는 것이다.
2. 기계는 처음에 그러한 선호가 무엇인지에 대해 불확실하다.
3. 인간의 선호에 대한 정보의 궁극적인 원천은 인간의 행동이다.
이러한 접근법의 초기 예시는 러셀 교수와 앤드류 응 교수의 역 강화학습(inverse reinforcement learning)에서 찾을 수 있다. 역 강화학습에서 인공지능은 인간 감독자의 행동은 어떤 보상 함수를 최대화한다는 가정 하에 감독자의 선호를 그의 행동으로부터 추론한다. 최근에 Hadfield-Mennell은 이 패러다임을 확장하여 인간이 AI의 존재에 반응하여 그들의 행동을 수정할 수 있도록 하였다. 예를 들어 "보조 게임"이라고 불리는 교육학적으로 유용한 행동들을 선호하도록 하는 협력적인 역강화학습을 제안하였다. 논쟁을 통한 학습이나 혹은 반복적인 증폭과 비교할 때, 보조 게임은 인간이 합리적이라는 가정에 명시적으로 의존한다. 인간이 체계적으로 편향되어있거나 최선이 아닌 행동을 하는 경우에 이 방법을 적용할 수가 없다.
Embedded agency
감당 가능한 감독에 대한 작업은 주로 POMDP와 같은 형식 내에서 발생한다. 기존의 형식주의는 에이전트의 알고리즘이 환경의 외부에서 작동한다고 가정한다. 즉 알고리즘에 물리적인 부분이 포함되어 있지 않은 것이다. 임베디드 에이전시는 이론적인 프레임워크와 실제 에이전트 사이의 불일치를 해결하기 위한 시도로 연구되고 있는 한 분야이다. 예를 들어 감당 가능한 감독 문제가 해결되더라도, 실행중인 컴퓨터에 접속할 수 있는 에이전트는 여전히 인간 감독자가 제공하는 것보다 더 많은 보상을 받기 위해 보상 기능을 조작할 동기가 존재한다. 딥마인드의 연구원 빅토리아 크라코프나의 실험에 따르면, 한 유전 알고리즘은 목표 아웃풋이 포함된 파일을 삭제함으로써 아무것도 리턴하지 않은 것에 대해 보상받는 것을 학습하였다. 에버릿과 허터의 현재 보상 함수 알고리즘 (current reward function algorithm)은 현재 보상 함수에 따라 미래의 행동을 평가하는 에이전트를 설계하여 이런 문제를 해결하고자 하였다. 이러한 접근법은 AI가 수행할 수 있는 일보다 더 많은 일을 하도록 일반적인 수정을 가하는 문제를 해결하기 위함이다.
이러한 연구 영역은 설계 명세서에서 알 수 있는 다른 속성에 대한 새로운 프레임워크와 알고리즘을 개발하는 것에 중점을 둔다. 예를 들어, 우리는 우리의 에이전트가 광범위한 불확실성 하에 정확하게 추론하기를 원한다. Leike는 베이지안 에이전트가 현실적인 가능성을 배제하지 않고 다중 에이전트 환경에서 서로의 정책을 모델링할 수 있는 일반적인 방법을 제공한다. Garrabant 유도 알고리즘은 확률적인 추론을 경험적인 사실뿐만 아니라 논리적인 사실에도 적용할 수 있도록 확장하였다.

'AI' 카테고리의 다른 글
| ChatGPT: 진실되고 보다 이로운 답변을 생성하는, OpenAI의 GPT 시리즈 (2) | 2022.12.21 |
|---|---|
| [논문리뷰] DeepMind RETRO - 수 조개의 토큰 DB로부터 정보를 검색해 강화된 언어모델 (0) | 2022.06.24 |
| [논문리뷰] GPT3의 새로워진 버전 - InstructGPT : 인간의 지시에 따른 결과물을 완성해내는 AI (3) | 2022.04.03 |
| [논문리뷰] 알파코드 - Competition-Level Code Generation with AlphaCode (0) | 2022.03.30 |
| [ML Ops] - 지속가능한 AI서비스를 위한 Model Drift의 인지 및 관리 (0) | 2022.02.20 |



