InstructGPT : Training language models to follow instructions with human feedback
블로그 포스팅 : https://towardsdatascience.com/the-new-version-of-gpt-3-is-much-much-better-53ac95f21cfb
GPT-3 설명 : 2020.06.22 - [AI] - [논문리뷰] GPT3 - Language Models are Few-Shot Learners
GPT-3가 발표된 후 지난 2년간 GPT-3 모델은 자연어 생성 태스크에서 뛰어난 성능을 보였다. 작시나 작사부터 에세이 작성, 코딩까지 다양한 분야에서 놀라운 결과를 보였지만 여전히 한계는 존재한다. 특히 옳지 않거나 편향된 문장을 생성하는 경향성이나 잘못된 지식을 생성하는 현상이 있었기에, 대규모 언어모델을 다룰 때 프롬프트 엔지니어링(prompt engineering)의 중요성이 대두되었다.
GPT-3는 학습된 대규모 트랜스포머 모델을 대량의 언어 코퍼스에 대해 사전학습한 후, 모델은 고정한 채 <인풋 프롬프트>에 추론하고자 하는 자연어 쿼리를 입력한다. 예를 들어 모델에게 < "상담사 분이 친절하게 답변해주셨어요" 라는 문장의 감정은? > 이라고 물으면 모델은 < 긍정 >이라는 답변을 주는 방식이다. 이는 기존에 하나의 태스크를 수행할 수 있는 모델을 만들기 위해 학습 데이터셋을 수집하고 fine-tuning 하는 방식과는 다른 방식으로, 언어 AI의 패러다임이 모델을 fine-tuning하는 것이 아니라 모델에게 질문하는 방식으로 옮겨가고 있다는 것을 시사한다.
여기서 모델에게 질문하는 방법, 즉 프롬프트를 구성하는 방식이 결과물의 퀄리티를 좌우한다. 이에 따라 좋은 프롬프트를 구성하는 프롬프트 엔지니어링이 중요한 영역으로 부각되었다. GPT-3는 방대한 언어 태스크를 수행할 수 있는 만큼 특정 영역에 특화되어 있지 않기고, 프롬프트 엔지니어링을 통해 모델에게 특정 태스크를 잘 수행할 수 있는 조건을 부여하는 것이다. 예를 들어 별과 달에 대한 이야기를 쓰고 싶다면, 별과 달에 대해 쓰여진 이야기를 세 개 정도 예시로 주고, 쓰고자 하는 네 번째 이야기의 첫 번째 문장을 입력해주면 된다. 이렇게 하면 GPT-3는 네 번째 별과 달에 대한 이야기를 실수 없이 작성할 수 있게 된다.
이런 과정은 꽤나 공수가 드는 작업이다. 뿐만 아니라 어떤 식으로 프롬프트를 구성해야 하는지 잘 모르는 대중이 사용하기에 친숙하지 않다. GPT-3는 이런 한계를 극복하고자 GPT의 새로운 버전인 InstructGPT를 발표했다.
그리고 이 새로운 모델에 대한 피드백이 너무나 좋은 나머지, <Instruct>라는 수식어를 빼고 GPT-3 API에서 디폴트로 InstructGPT가 사용되도록 하였다. (API 상에서 175B InstructGPT 모델은 text-davinci-001이라는 이름으로 지정되어 있다)
InstructGPT는 자연어 지시문만으로 작동한다
기존 버전의 GPT와 InstructGPT의 가장 큰 차이는 모델에게 <직접적으로> 지시할 수 있다는 점이다.
별과 달에 대한 이야기를 쓰는 GPT-3의 예시에서, 예시 이야기 3개와 네 번째 이야기의 첫 번째 문장이라는 프롬프트는 "별과 달에 대한 이야기를 써야 한다"는 지시를 간접적으로 모델에게 전달한 것이다. 즉, 세 개의 예시를 보고 모델은 눈치껏 네 번째 이야기를 써 내려간다는 것이다.
InstructGPT에서는 프롬프트로 보다 직접적인 것을 사용할 수 있다 : <별과 달에 대한 짧은 이야기를 써 봐> 와 같이 말이다.
이러한 직접적인 프롬프트를 받은 InstructGPT는 제법 훌륭한 이야기를 써내려간다

예시를 주지 않은 채 이러한 명령을 기존 GPT-3에게 입력한다면? 모델은 형편없이 같은 어구를 반복할 뿐이다.
GPT-3에서 InstructGPT로 재학습하기
GPT-3 모델을 InstructGPT 모델로 만들기 위해 OpenAI는 다음의 세 가지 단계를 도입했다.
이때 Deepmind 팀과 함께 개발한 강화학습 알고리즘 RLHF (reinforcement learning with human feedback)을 적용한다.
Step 1.예제 데이터 수집 후 supervised policy를 학습 => SFT 모델 확보
: GPT-3가 주어진 지시문대로 행동하도록 가르치기 위해, 해당 데이터셋을 만들어 <fine-tuning> 한 모델 확보
> 이를 위해 지시 프롬프트와 그에 대한 결과물로 이루어진 데이터셋을 정의 (demonstration dataset, 13K prompts)
- 프롬프트 데이터셋으로부터 지시 prompt를 샘플링 (예) 8살 아이에게 달착륙을 설명해보시오
- 라벨러는 프롬프트에 적합한 행동을 예시로 라벨링 (예) 몇몇 사람들이 달에 갔답니다 ~~
> 이 데이터셋을 GPT-3에 대해 Fine-tuning => 결과로 SFT (supervised fine-tuning) 모델을 얻음
- 이렇게 fine-tuning 된 모델은 원래 GPT-3와 완성된 InstructGPT를 비교하기 위한 베이스라인으로 사용됨
- 지시문을 따르는 점에 있어 이 모델은 이미 GPT-3보다 성능이 우수했지만, 완벽하게 원하는 방식으로 작동하지는 않았다
Step 2. 결과물에 대한 사람의 선호도 데이터를 학습 => Reward Model 확보
: Comparison dataset을 사용해 Reward Model(보상 모델) 학습
> Comparison dataset은 33K 개의 프롬프트로 이루어져 있으며 이를 Reward Model 학습에 적합하게 구성한 것
- comparison dataset은 프롬프트와 그에 따른 결과물들 (4-9개), 그리고 그 결과에 대한 선호도 순위로 구성됨
- 즉, 프롬프트가 주어질 때 Reward Model은 결과물들에 대해 사람의 선호도를 예측하는 방법을 학습
- 이때 사용한 프롬프트는 step 1의 demonstration dataset에서 사용한 것과 다름
Step 3. 강화학습을 사용해 Reward Model에 대해 policy를 최적화 => InstructGPT
: Step1의 SFT 모델을 Step2의 보상모델을 사용해 강화학습을 통해 추가 fine-tuning
> Proximal policy optimization algorithm(PPO) 사용
- Reward Model을 보상함수로 사용하여 정책을 최적화 (InstructGPT가 사람의 피드백을 얻는 방법)
> 강화학습을 통한 fine-tuning 과정은 다음과 같이 이루어진다 :
3-1) InstructGPT는 프롬프트를 보고, 그에 대한 결과 (completion)를 추론함
3-2) 이 결과물을 Reward Model이 평가하여 reward(보상)를 계산
3-3) 보상 값이 InstructGPT에게 주어지고, 모델은 정책을 업데이트하여 사람이 원하는 아웃풋에 더 가까운 결과를 내게 됨
요약하자면, 먼저 지시문에 따라 결과를 완성하는 초기 모델을 완성한 후,
사람의 feedback을 모사하는 보상 모델(reward model)을 확보하여
이를 통해 초기 모델이 사람이 더 선호하는 결과를 추론하도록 강화학습을 진행한 것!
성능
API에서 수집한 프롬프트 평가
한 줄 요약 : "라벨러들은 InstructGPT의 아웃풋을 GPT-3의 아웃풋보다 더 좋게 평가하였다"
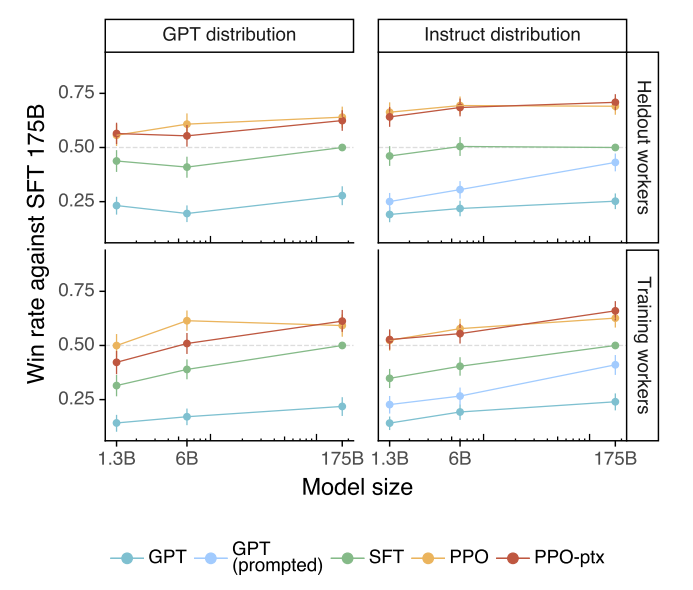
InstructGPT 계열 모델 (PPO-ppx & PPO) 는 다른 모델을 (GPT-3, GPT-3 prompt, SFT 베이스라인)에 대한 선호도가 더 높았음을 볼 수 있다. 특히 175B 사이즈의 가장 큰 모델에 있어 사용자들은 4번 중 3번 InstructGPT를 GPT-3보다 선호하였고, 프롬프트 엔지니어링을 저친 GPT모델도 InstructGPT를 이기지 못했다. 특히 학습 데이터 생성에 참여하지 않은 라벨러(Heldout workers) 그룹 또한 InstructGPT 결과를 선호하였고, 모델이 학습 데이터 라벨러의 선호를 잘 일반화한 것으로 보인다.
특히, 모델에게 명백한 조건을 입력하는 상황에서 InstructGPT의 결과물의 선호도가 특히 높았던 것으로 나타났다 :
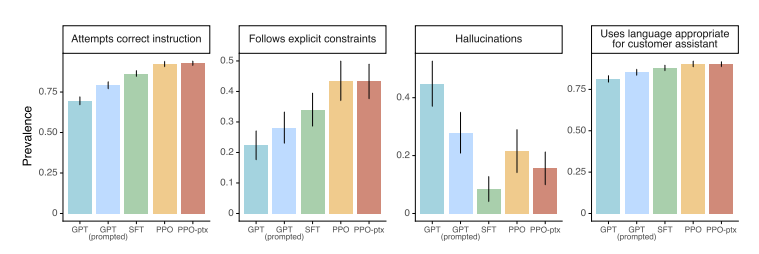
* Follow explicit constraints : 예) 답변을 두 문장 이내로 작성하시오
* hallucinations : 예) 정보를 너무 자주 만들어내지 마시오
NLP 태스크에서의 평가 : Honesty, toxicity, bias
Honesty (진실성)
모델의 진실성을 평가하기 위해 TruthfulQA 데이터셋을 활용하였다.
TruthfulQA는 "모델이 인간의 거짓말을 어떻게 흉내 내는지" 평가하는 벤치마크 데이터셋이다.
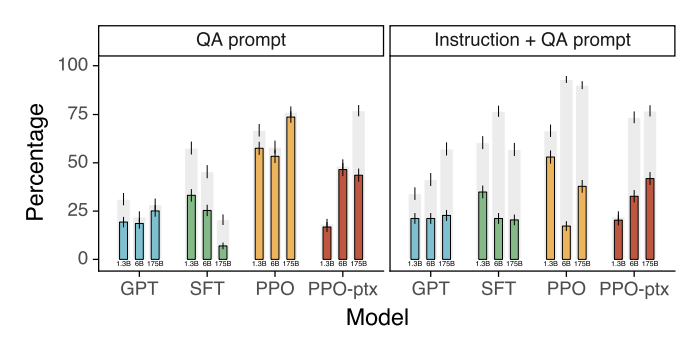
그 결과, InstructGPT는 GPT-3에 비해 두 배 더 진실된 답변을 하는 것으로 나타났다. 뿐만 아니라 closed-domain QA, 요약 태스크에 대해 평가해보았을 때, InstructGPT는 21% 정도만 말을 적당히 생성(hallucinate)하는 것으로 나타났는데, 이는 GPT-3가 보였던 41%라는 수치의 절반에 해당한다.
특히 이 결과는 기본 셋팅에서 추론한 결과이고, 모델에게 진실되도록 따로 프롬프트 엔지니어링을 진행하지 않아도 모델은 기본적으로 truthful 하게 행동한다는 것을 의미한다.
Toxicity (유해성)
InstructGPT가 내재적으로 더 '안전한' 모델은 아닌 것으로 나타났지만, 사용자의 지시를 따르는 능력이 더 높은 것으로 나타났다. 하지만 이러한 특성은 항상 사람에게 이로운 것은 아니다. 모델의 용량을 늘리는 것은 성능 측면에서 이점이 있으나, 안전 측면에서 항상 나아지는 것은 아니다. 언어모델이 사용자의 의도를 더 잘 따른다는 것은, 그만큼 오용하기 쉽다는 의미이기도 하기 때문이다.
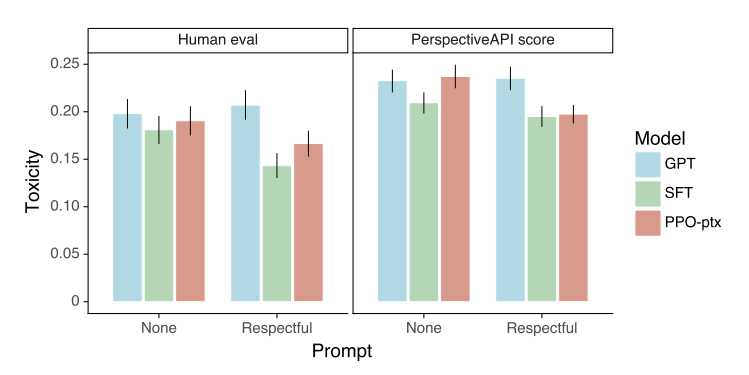
<그림 7>은 RealToxicityPrompts 데이터셋에 대해 모델의 결과를 평가한 결과이다. InstructGPT는 프롬프트에서 "Respectful"할 것을 지시했을 때 GPT-3에 비해 toxicity가 낮아진 것을 확인할 수 있지만, 일반적인 상황에서 둘은 같은 수준의 유해성을 가지는 것으로 보인다.
Bias (편향)
차별과 편향에 있어서는 심지어 InstructGPT가 GPT-3에 비해 악화된 것으로 나타났다.
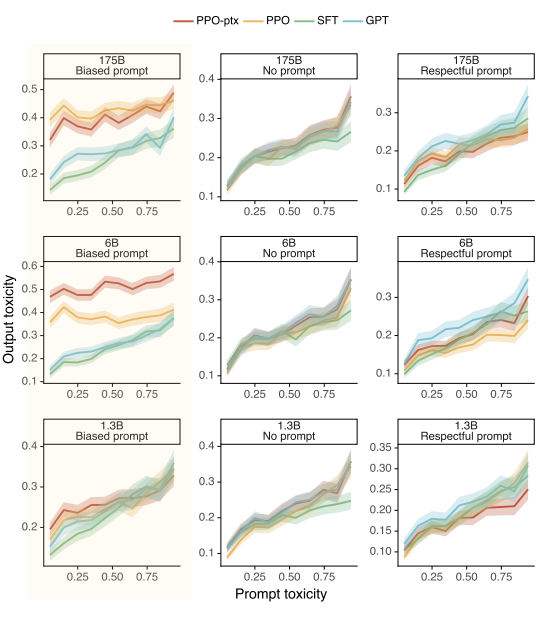
심지어 <그림 39>에서 하이라이팅 된 부분의 그래프를 보면, "Biased"라는 프롬프트를 주자, InstructGPT는 일반 GPT보다도 더 편향된 결과를 내는 것으로 나타난다.
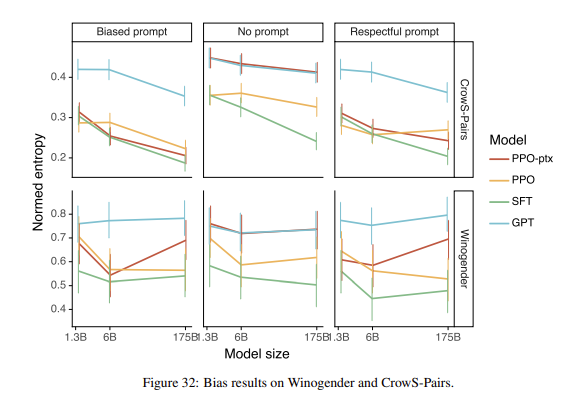
Winogender와 CrowS-Pairs 데이터셋에 대해 평가한 <그림 32>의 결과를 보더라도, InstructGPT는 일반적으로 GPT-3보다 더 biased 된 결과를 보인다. OpenAI는 이 모델이 스테레오타입이 섞인 행동을 할지라도, 그 출력에 대해 더 확신을 가진다는 것으로 분석하였다. 즉, InstructGPT 모델은 GPT-3보다 강력하며 이로 인해 잠재적으로 더 해로울 수 있다는 것을 의미한다.
이러한 결과들은 InstructGPT가 받은 보상 시그널이 특정한 그룹의 사람들에게 맞춰져 있기 때문에 차별 등의 행동을 개선하지 못하였다는 것을 암시한다. 만약 라벨의 종류가 다양했다면, 즉 더 다양한 인종, 국적, 문화를 반영하였다면 결과는 크게 달라졌을지도 모른다.
OpenAI에서는 이러한 기준에 맞게 모델을 재조정하려 노력했지만 큰 개선의 성과를 보지는 못했다. 그 이유는 GPT-3가 학습한 사전학습 데이터가 이미 편향으로 가득했기 때문일 것이다. 일부 인간의 피드백 등으로 이러한 편향과 차별을 교정하려 노력했으나, 많이 나아지지는 못했다. 아마 가장 좋은 해결책은 사전학습 데이터셋에 대한 큐레이션을 개선하여 처음부터 다양하고 질 좋은 데이터로 모델을 학습하는 것이다.
InstructGPT가 학습한 "선호"의 대표성에 대한 논의
목적 함수의 변화 : 왜 OpenAI는 GPT-3가 사람을 따라하도록(alignment) 했을까?
: 단순히 다음 토큰을 예측하는 "Next Token Prediction" 태스크는 충분히 유용하지 않기 때문에.
OpenAI팀은 GPT-3가 학습한 자기지도학습 기반의 다음 토큰 맞추기 태스크는 모호한 목적함수이기에, 모델이 진실성 있고 무해한 결과물을 내도록 재정의하고자 하였다. 하지만 이러한 목적함수를 수식적으로 기술하는 것은 쉬운 일이 아닐 것이다.
"인간에게 유용하고 무해함"이라는 것을 어떻게 정의할 수 있을까?
OpenAI는 좀 더 명확한 사람의 의도를 이해하도록, 즉 프롬프트의 지시를 잘 따르도록 하는 목적함수를 고안하기로 했다.
이는 라벨러가 모델이 할 수 있는 답변에 등수를 매김으로써 전달되는데, InstructGPT는 사람들이 매긴 추론 결과의 좋고 나쁨을 시그널로 삼아 사람이 더 좋게 생각할만한 행동을 하도록 학습한다.
즉, 사람의 점수는 모델이 a) 유용하고, b) 정직하며 c) 무해한 특징을 가지도록 시그널을 주는 역할을 한다.
여기서 "정직하다"는 개념은 어떻게 정의할 수 있을까? 어쩌면 정직함이란 내재적으로 믿고 있는 것과 행동으로 표출되는 것의 상관관계로 정의할 수 있겠다. 하지만 '블랙박스' 형태를 가지는 언어모델의 내재적 믿음이란 정의하기 어려울 것이다. "무해하다"라는 것을 정의하는 것도 까다롭다. 이는 모델이 실제로 어떤 곳에 적용될지와 관련이 깊기 때문이다. 범용 언어 모델을 배포한다는 것은 '유해 언어 검출 모델'을 배포하는 것과는 매우 다른 일이다.
이러한 모호성으로 인해 OpenAI는 라벨러들이 점수를 매길 때 "유용성" 측면을 가장 우선시하도록 지시했다. 사용자가 "원하는" 답변이 유해한 답변일지라도 말이다. 다음 순위로는 진실성과 무해함을 우선시하도록 지시했는데, 이것이 실제 모델 사용 시 중요한 특성일 것이기 때문이다.
인간 선호의 다양성 (Diversity of alignment)
새롭게 학습된 모델은 답변에 있어 어떤 것이 더 좋고 나쁨을 배웠지만, 이 순위에 대해 모든 인간이 동의할 것을 목표로 한 것은 아니다. InstructGPT 모델은 일반적인 관점에서 <인간>의 선호에 더 가깝지만, <인간>에게는 InstructGPT에 반영되지 않은 엄청난 다양성이 존재한다. 모델은 분명 라벨러들, 혹은 OpenAI 연구자의 선호를 학습하고, 그의 평가를 같이하지만, 그 이외 나머지 사람들은 어떻까? OpenAI 역시 이러한 부분을 우려했고, 다음과 같이 표현하였다 :
"연구자, 고용된 라벨러들, 혹은 API 고객이 올바른 선호의 표본이라고 생각하고 있지는 않다"
바이어스를 줄이기 위해 OpenAI는 라벨러 선택에 있어 특정 기준들을 도입했다. 그중 핵심 기준은 "다른 인구통계적 그룹의 선호에 민감할 것"이었다. 라벨러들은 대부분 미국 혹은 동남아시아의 영어를 구사할 수 있는 사람이었기에, 사회의 다양성을 반영하기에 부족할 것이다. 게다가 AI alignment를 정의하기 위해 '평균적임'을 사용하는 것은 진정한 의미의 재정렬로 이루어지지 않을 수 있다. 평균적인 것은 소수의 선호를 거의 반영하지 못하고, 다수의 선호에 큰 가중치를 주기 때문이다.
어쨌든 다양한 그룹에 동조하는 모델을 만드는 것은 더 안전하고 신뢰 가능한 모델을 구축하는 데에 중요하다. 하지만 AI alignment에 대해 연구할 때, 사람들은 매우 다양하다는 것을 잊어서는 안 된다. 모든 사람들에게 해롭지 않은 수준의 모델을 어떻게 만들 수 있을까? 일단 가능한 시작점은, 적어도 라벨러를 각 그룹을 대표하는 사람을 한 명씩은 선별하거나, 각 그룹에 적합한 맞춤 모델을 만드는 것이다.
하지만 여기에는 또 다른 어려움이 존재한다. "그룹"이라는 것은 어떻게 정의할 수 있을까? 인종, 성별, 나이, 국가, 종교?
특정한 그룹에 적합한 특정 모델이 더 넓은 사회에는 영향을 미치지 않도록 하려면 어떻게 해야 할까?
AI alignment를 정의하고, 연구함에 있어 이러한 윤리 철학적인 질문을 깊게 고민해보아야 할 것이다.

'AI' 카테고리의 다른 글
| [논문리뷰] DeepMind RETRO - 수 조개의 토큰 DB로부터 정보를 검색해 강화된 언어모델 (0) | 2022.06.24 |
|---|---|
| AI alignment - 인공지능과 사람의 <동상동몽> (2) | 2022.04.17 |
| [논문리뷰] 알파코드 - Competition-Level Code Generation with AlphaCode (0) | 2022.03.30 |
| [ML Ops] - 지속가능한 AI서비스를 위한 Model Drift의 인지 및 관리 (0) | 2022.02.20 |
| [논문리뷰] Relative Position Representations in Transformer (0) | 2022.02.04 |



