오픈 AI GPT 시리즈의 세 번째 논문이 공개되었씁니다!!!!
- GPT1 - Improving Language Understanding by Generative Pre-Training
- GPT2 - Language Models are Unsupervised Multitask Learners
- GPT3 - Language Models are Few-Shot Learners
2020/07/20 - [AI] - GPT-3, 이런 것도 된다고?
GPT-3, 이런 것도 된다고?
오픈AI의 GPT-3가 할 수 있는 놀라운 일들 2020/06/22 - [AI] - [논문리뷰] GPT3 - Language Models are Few-Shot Learners [논문리뷰] GPT3 - Language Models are Few-Shot Learners 오픈 AI GPT 시리즈의 세 번..
littlefoxdiary.tistory.com
NLP 모델은 태스크와 무관한 representation을 학습하는 방향으로 발전해왔다. 단어 임베딩을 학습하는 것에서 시작하여 RNN 레이어를 쌓아 문맥 벡터를 만들어내는 ELMo, 최근에는 BERT, GPT, ULMFit과 같이 트랜스포머 구조를 이용해 문맥을 표현하는 깊은 모델까지, 다운스트림 태스크와 상관없이 대량의 코퍼스를 이용해 학습된 모델은 fine-tuning을 통해 성공적인 퍼포먼스를 달성했다. 하지만 이러한 방법들은 사전학습은 여전히 "태스크에 따라 매번 fine-tuning이 필요하다"라는 한계가 있었다.

반면에 우리 인간은 몇 가지 예시, 가령 위의 사진에서 문장 네 개만을 보아도 ? 에 들어갈 값은 0 이라고 쉽게 추론할 수 있다. 이렇게 풀고자 하는 문제에 대해 몇 개의 예시만 보고 태스크에 적응하여 문제를 푸는 것을 few shot learning이라고 한다. 이러한 few shot learning은 대부분의 NLP 모델들이 고전하고 있는 문제 중 한 가지이다. 각종 자연어처리 태스크에 대해 좋은 성능을 내고 있는 BERT, GPT와 같은 모델도 성능을 내기 위해 수백, 수천 개의 예제를 가지고 fine-tuning을 해야 한다.
"태스크와 무관하게 학습한 모델이라도, 좋은 성능을 위해서는 fine-tuning이 필요하다."
현존하는 모델이 가진 이러한 한계를 넘어서는 것은 다음과 같은 이유에서 매우 중요하다.
첫 째, 지금과 같은 방식에서는 새 태스크를 풀 때마다 많은 라벨링된 데이터가 필요하다. 몇 가지 예제만으로 언어 모델이 태스크에 적응할 수 있다면 문법 교정, 생성 요약, 짧은 글에 대해 비평문 쓰기와 같이 라벨링 데이터를 만들기 어려운 흥미로운 영역까지도 모델을 확장할 수 있을 것이다.
두 번째, 사전학습 후 fine-tuning 하는 방법에서는 접근법에서 모델은 사전학습 중 대량의 지식을 흡수하지만, 아주 작은 태스크 분포에 대해 fine-tune 된다. 그 결과, 모델이 크다고 해서 out-of-distribution 문제를 더 잘 일반화하지 못하다는 연구 결과도 있다.(논문) 이는 훈련 데이터의 분포에 대해 한정지어진 모델이 그 외의 영역은 잘 일반화하지 못한다는 증거이고, 벤치마크 태스크에 대해서는 마치 성적이 좋은 것처럼 보일지언정 사람이 볼 때는 그 성능이 과장된 것처럼 느낄 수 있다. (논문, 논문)
세 번째, 사람은 대부분의 언어 태스크를 하기 위해 '예제 데이터'를 많이 필요로 하지 않는다. 간단한 지시사항, 이를테면 "이 문장이 긍정적인 감성을 담고 있는지, 부정적인 감성을 담고 있는지 말해보세요"과 같은 문장만으로도 태스크를 어느 정도 잘 해낼 수 있다. 뿐만 아니라 대화를 하다가 간단한 덧셈을 실시하는 등, 많은 태스크와 기술을 왔다 갔다 하며 사용할 수 있다. 언어 모델이 유용하려면, NLP 시스템 역시 이러한 유연성과 일반성을 가져야 할 것이다.
이를 극복하기 위해 meta-learning 분야가 활발하게 연구되었다. 훈련 시 다양한 스킬이나 패턴을 인식하는 방법을 학습함으로써 추론 시 다운스트림 태스크에 빠르게 적응하도록 하는 방법이다. GPT-2에서는 이러한 방법을 "in-context learning" 방식으로 진행했는데, 사전학습 모델에 풀고자 하는 태스크를 텍스트 인풋으로 넣는 방식이다. 하지만 안타깝게도 결과들은 몇몇 태스크에서는 fine-tuning 접근법에 미치지 못하는 아쉬운 성능을 보였다.
최근 NLP 연구의 또 다른 트렌드는 모델 크기를 키우는 것이다. 트랜스 포머를 이용하면 모델 사이즈를 크게 늘릴 수 있고 파라메터 수가 1억 개(GPT-1), 3억 개(BERT), 14억 개(GPT-2), 80억 개(Megatron), 110억 개(T5), 170억 개(Project Turing)까지 늘어나며 다운스트림 태스크에서의 성능은 점점 더 좋아졌다. in-context learning 방식은 최대한 다양한 스킬과 태스크를 모델의 파라메터에 저장해야 하고, 모델의 스케일이 증가할 때 성능이 증가할 가능성이 있다.
그래서 GPT-3은... 1750억 파라메터 가즈아... !!!
그리고 이렇게 크다란 모델이 정말 논문의 모티브인 "few-shot" 셋팅에서 잘 작동하는지 보기 위해, 24개 NLP 데이터셋에 대해 3가지 조건 하에 모델 성능을 측정한다.
(a) few-shot learning (in-context learning) : 모델의 문맥 윈도우(10~100)에 넣을 수 있는 만큼 많은 예제를 넣음
(b) one-shot learning : 하나의 예제만을 허용함
(c) zero-shot learning : 예제는 사용하지 않음. 태스크에 대한 설명, 혹은 지시사항만을 모델에게 줌.

위 그림은 위의 조건에 따른 결과를 요약해서 보여준다.
1. 태스크에 대한 자연어 설명은 모델 성능을 향상시킨다 (Natural Language Prompt > No Prompt)
2. 모델의 문맥 윈도우에 더 많은 예제를 놓을수록 성능이 향상 (K에 비례하여 정확도 증가)
3. 큰 모델일수록 in-context 정보를 잘 활용 (175B params의 결과를 보아라)
이때 성능을 측정하는 동안 그라디언트 업데이트나 fine-tuning은 일절 일어나지 않는다. K의 증가에 따라 정확도가 증가하는 것처럼 보이는 부분은, 오로지 문맥에 포함된 예제의 개수를 모델이 얼마나 잘 활용하는가에 기인한다.
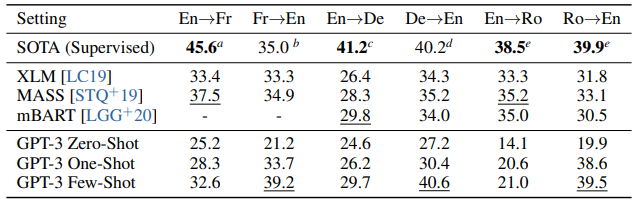
NLP 태스크 전반에 걸쳐 GPT-3은 few-shot , one-shot, zero-shot 셋팅에서 상당한 성능을 보였고, 몇몇 태스크에서는 현 SOTA보다 좋은 성능을 보였다. 예를 들어 CoQA에서는 zero-shot으로 F1 81.5, one-shot으로 84.0, few-shot으로 85.0의 성능을 보였다. TriviaQA 태스크에서는 각각 64.3%/ 68.0% / 71.2%의 성능을 보였고, few-shot 셋팅에서의 성능은 fine-tuning 기법을 사용한 모델에 비해서도 SOTA 성능이다.
GPT-3은 또한 단어 순서 맞추기, 문장에서 새로운 단어 사용하기, 3자리 수리 연산하기와 같은 추론 혹은 도메인 적응이 필요한 태스크도 몇 개의 예제만 보고 잘 수행해냈다. 뉴스는 사람이 보기에 기계가 쓴 것인지, 기자가 쓴 것인지 분간하기 어려울 정도로 잘 쓸 수가 있다.
그럼에도 불구하고, GPT-3의 스케일로도 감당이 되지 않는 few-shot task가 있었다. ANLI데이터와 RACE, QuAC와 같은 질의응답 셋이 그러하였다. 본 논문에서는 GPT-3이 가지는 강점과 약점을 분석하고, few-shot learning의 발전을 위해 한계점을 분석한다.
GPT-3가 해낼 수 있는 다양한 가능성, 모델이 가질 수 있는 bias, 공정성과 사회적인 이슈들과 같은 모델의 특성도 분석하였으니, 참고 논문 제외 67 페이지에 달하는 논문을 끝까지 잘 읽어볼 것 ㅎㅎ!
Approach
기본적인 사전학습 접근법(모델, 데이터, 훈련 기법)은 대부분 GPT-2와 비슷하다. 모델 크기를 키우고, 데이터 양과 다양성을 증가시키며 훈련 기간을 늘렸다. In-context 학습법도 GPT-2와 비슷하다. 하지만 본 논문에서는 GPT-3을 평가하는 방법을 다음과 같이 네 가지로 세분화하여 정의하였다.
1) Fine-Tuning(FT) - NLP에서 가장 보편적인 방법으로, 사전 학습된 모델의 웨이트를 다운스트림 태스크에 대해 미세 조정하는 것. 보통 수천 개의 라벨링 된 데이터를 사용한다. 이 방법은 성능 향상에 크게 도움되지만, 매 태스크마다 라벨링된 데이터가 지나치게 많이 필요하다는 단점이 있다.
2) Few-Shot(FS) - 모델은 예시 태스크를 보게 되지만, 가중치 업데이트는 일어나지 않는다. K(10~100) 개의 예제를 context (2048 토큰까지 처리) 부분에 주고, 추론하려는 example의 결과를 완성하도록 하는 접근법이다. 이 방법에서는 태스크에 대한 소량의 예제만이 필요하다. 하지만, 대부분의 모델에서 few-shot 성능은 fine-tuning 결과를 따라가지 못한다.
FS 세팅에서 모델에게 번역 태스크를 시키고자 한다면 context 부분에는 다음과 같은 입력을 넣는다.
"한국어를 영어로 번역하라: 집에 가고 싶어 -> I want to go home. 배고파 -> I am hungry 치킨 사줘 -> _______ "
모델은 문맥 인풋에 있는 예시들을 보고 _____ 부분에 "Buy me fried chicken"을 채워 넣어야 한다.
3) One-Shot(1S) - FS 세팅과 같으나, 하나의 예제만을 예시로 준다.
4) Zero-Shot(0S) - 태스크에 대한 예시는 주지 않고, 태스크를 설명하는 자연어 문구만을 준다. 이 방법은 엄청나게 편리할 뿐만 아니라 잠재적으로 강건하고 사전학습 데이터에 편재할 수 있는 좋지 않은 상관관계를 피하게 한다. 하지만, 이는 굉장히 어려운 과제이고 아마 몇몇 과제는 사람조차도 지시사항만으로 푸는 데에 어려움을 느낄 수 있다.

모델과 아키텍처
- GPT-2와 같음.
- modified initialization, pre-normalization, reversable tokenization 적용
- 단, 트랜스포머 레이어의 attention 패턴에 대해 dense와 locally banded sparse attention을 번갈아 사용
- 스케일에 따라 다음과 같이 8가지 모델을 학습하고 테스트. 가장 큰 모델은 96층의 레이어, 12,288차원의 히든 차원, 96개 attention head를 가지는 총 1750억 개의 파라미터의 모델임. 모든 모델은 3,000억 토큰에 대해 학습함.

- 더 큰 모델에 대해서는 더 큰 배치를 적용했으나, 오히려 learning rate는 작게 적용함.
- 학습 과정에서 그라디언트의 noise scale을 측정해 배치 사이즈를 정하는 데에 활용. (관련 연구)
- 큰 모델 학습에는 메모리가 부족하기 때문에, 행렬 곱에 있어 모델 병렬화와 레이어 사이의 모델 병렬화를 섞어서 사용.
- 더 자세한 훈련 과정은 Appendix B 참고...
훈련 데이터셋

결과
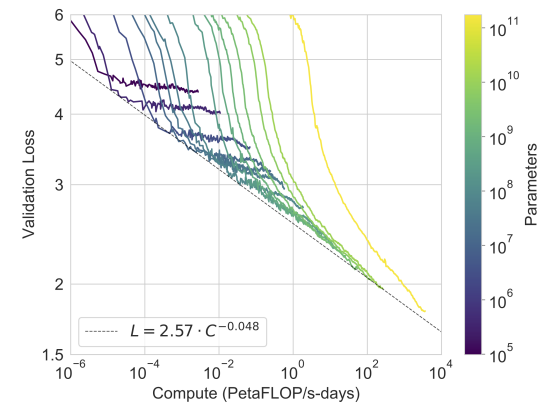
다음 그림은 스케일에 따른 8개의 모델에 대한 훈련 곡선을 나타낸다. 이 그래프에서는 십만 개의 파라미터만을 가진 극단적으로 작은 6개의 모델 결과도 보여준다. 기존 연구에서도 드러났듯이, language modeling 성능은 계산을 효율적으로 사용할 경우 모델이 커짐에 power-law에 따라 좋아졌다. 하지만 모델 크기가 매우 커졌을 경우 power-law에서 조금 벗어나 더 향상되는 모습을 보였다. 이러한 결과가 모델이 훈련 코퍼스에 있는 지나친 세부사항에서 오는 cross-entropy-loss에서 기인하는 것이 아닌지 걱정할 수 있으나 cross-entropy loss에서의 향상이 다양한 NLP 태스크에서 성능 향상을 가져온다는 것을 보일 것이다.
3.1 전통적인 language modeling 및 관련 태스크에서의 성능

Language Modeling
: Penn Tree Bank 데이터에 대해 zero-shot perplexity를 계산한 결과, 가장 큰 GPT-3 모델은 기존 zero-shot SOTA보다 15 point 앞선 20.50의 perplexity로 SOTA를 달성함.
LAMBADA (문장 완성하기/ 언어의 장기 의존성을 모델링하는 태스크)

: 최근 사이즈만 키운 언어 모델은 LAMBADA와 같이 난이도가 높은 벤치마크 데이터셋에 대해서는 미미한 성능 향상만을 가져왔고, '하드웨어와 데이터 크기만 늘리는 것이 길이 아니다'는 논쟁을 불러일으킴. 그러나 GPT-3은 기존 대비 8% 이상의 성능 향상을 얻으며 Zero-shot setting에서 76%의 정확도를 달성했고, Few-shot에서는 86.4%의 정확도 달성

HellaSwag (짧은 글이나 지시사항을 끝맺기에 가장 알맞은 문장을 고르는 태스크)
: 모델은 어려워하지만 사람에게는 쉬운 태스크 중 하나, 현 SOTA인 multi-task 학습 후 fine-tuning 전략을 취한 ALUM 에는 미치지 못하는 성능을 얻었다.
StoryCloze (다섯 문장의 긴 글을 끝맺기에 적절한 문장을 고르는 태스크)
: few-shot(K=70)으로 87.7%의 성능을 얻었고, BERT 기반의 fine-tuning SOTA보다 4.1% 낮은 성적이긴 하나 기존의 zero-shot 성능은 10% 가까이 뛰어넘었다.
3.2 Closed Book Question Answering
: GPT-3이 폭넓은 사실 기반의 지식에 대한 질문에 답변할 수 있는지 측정. open-domain QA 형태의 태스크에 대해 closed-book 테스트를 진행하였다.
TriviaQA : Few-shot& Zero-shot 성능으로 T5-11B 모델의 fine-tuning 기반의 접근법 성능을 뛰어넘음
WebQuestions : 14.4% / 25.3% / 41.5% (0S/1S/FS) -> few shot으로 갔을 때 zero shot에 비해 성능 향상이 큰 태스크 중 하나. GPT-3에게 있어 WebQA스타일의 질문은 out-of-distribution이었을 것으로 추정함. 그럼에도 불구하고 T5-11B fine-tuning 전략 성능인 37.4%을 넘었고, Q&A를 위한 사전학습을 더한 T5-11B+SSM의 44.7% 성능에 비견할 만하다.
Natural Questions : 14.6% / 23.0% / 29.9% -> NQ는 위키피디아에 대해 fine-grained 지식을 요구하는 태스크로, GPT-3의 폭넓은 사전학습 분포에 대한 학습 능력을 측정하기에 적당하지 않았다고 분석함.
3.3 번역
GPT-3 사전학습에 사용한 데이터 중 Common Crawl 데이터에 대해서는 '텍스트 질' 필터만 적용했고, 그 결과 93%의 텍스트는 영문이었지만 나머지 7%는 기타 언어들을 포함했음. GPT-3은 다양한 언어를 자연스럽게 섞어서 학습하게 되었고, 어떠한 목적함수도 태스크 한정적이지 않았음. 당연히 1-shot 혹은 few-shot 세팅은 다른 unsupervised work와 비견할만하지는 않지만, 모델에게 태스크에 대한 예제를 주자 기존 논문들의 BLEU 스코어에 비견할만한 점수를 얻기도 함. 불어-> 영어 / 독어-> 영어에 대해서는 supervised 세팅의 SOTA보다 좋은 성능을 얻기도 했다... (어떻게..???)
3.4 대명사 지칭 문제 (Winograd-syle 태스크)
: 최근 fine-tuning 접근법의 모델은 Winograd 데이터에 대해 사람 퍼포먼스에 달하는 성능을 내기도 했으나, 적대적으로 만들어진 Winogrande 데이터 등에서는 성능이 떨어졌다.


GPT-3은 Winograd에서는 in-context learning을 많이 하지 않았으나, Winogrande 태스크에 대해서는 확실히 in-context learning을 한 것으로 보인다.
3.5 Common Sense Reasoning
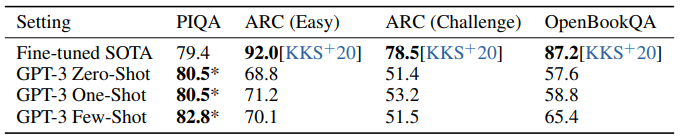
물리학이 어떻게 작동하는지 묻는 PhysicalQA(PIQA)에서는 few / zero shot 세팅에서 이미 SOTA를 넘겼지만, 분석 결과 data contamination issue가 있을 수 있다고 조사함 (section 4에서 계속)
3-9학년 과학 시험 수준의 4지선다형 문제인 ARC에서는 easy와 challenge 모두 SOTA에 미치지 못하는 성적. OpenBookQA에서는 few-shot이 zero-shot setting 대비 크게 성능 향상이 있어 in-context learning을 해낸 것으로 보이나, 역시 SOTA에는 미치지 못하는 성적이었다.
3.6 기계 독해
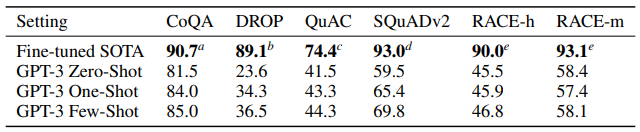
전반적으로 0S / 1S / FS 성능은 fine-tuning 기반의 SOTA에 미치지 못함
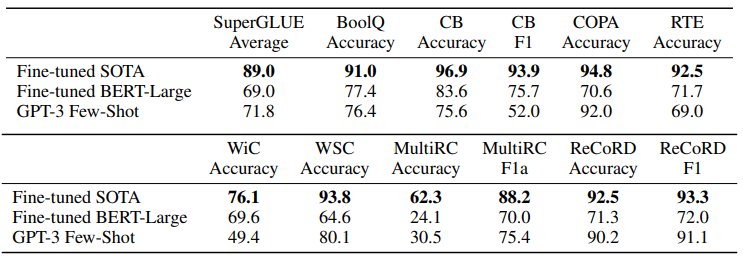
3.7 SuperGLUE
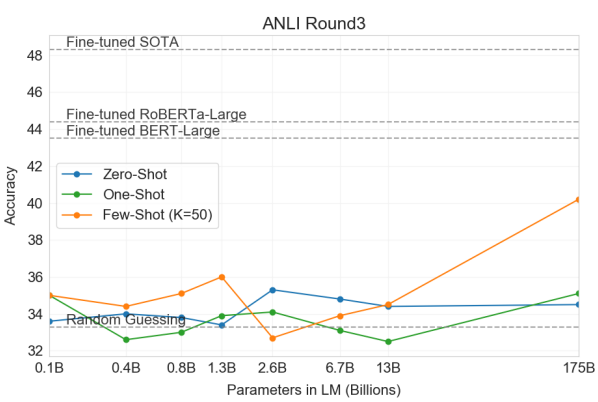
3.8 NLI (Natural Language Inference)
3.9 Synthetic & Qualitive Tasks
: GPT-3는 간단한 계산 추론을 하고 특이한 태스크에도 적용할 수 있다는 것을 보이기 위해 실험을 진행했다.
Arithmetic
: 2~5 자릿수 덧셈/ 뺄셈 , 두 자릿수 곱셈, 한 자릿수 복합 연산 태스크에 대해 GPT-3이 이런 문제를 풀 수 있을지 테스트

few-shot 세팅에서 두 자릿수 덧셈과 뺄셈 영역에 있어서는 175B 모델의 경우 완벽에 가까운 성능을 보였다. 하지만 4 자릿수 이상의 계산에서는 성능이 매우 떨어졌고, 복합 연산에 대해서는 21.3%밖에 되지 않는 정확도를 보여, 하나의 계산을 넘어가는 계산에 대해서는 강건성이 떨어지는 것으로 나타났다.

Word Scrambling & Manipulation
- CL(Cycle letters in word): 순서가 뒤죽박죽 된 단어를 원래로 맞추기 (예. plepa -> apple 셜록홈즈인줄...)
- A1(Anagram, 처음/마지막 글자 제외) : 처음과 마지막 글자를 제외하고 랜덤하게 만든 글자 원복하기 (aekve -> apple)
- A2(Anagram, 처음&마지막 두 글자 제외) : 처음&마지막 두 글자씩을 제외하고 랜덤하게 만든 글자 원복 (apyle -> apple)
-RI(Random insertation in word) : 각 글자 사이에 랜덤한 마침표나 띄어쓰기가 들어간 것 원복 (a!p.p l^e% -> apple)
- RW(Reversed word) : 거꾸로 쓴 글자를 원래로 맞추기 (elppa -> apple)
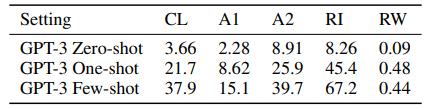
4글자 초과, 15글자 미만의 가장 자주 사용하는 단어 만개를 이용해 위의 태스크들에 대해 각각 10,000개의 예제를 생성하고, few-shot / one-shot 셋팅으로 결과를 측정해 보았다. zero-shot으로는 거의 아예 문제를 풀 수 없었고, 몇 개의 예제를 볼 때 그나마 성능 향상이 있었다. 이러한 태스크들은 글자 단위로 단어를 조작하는 능력을 요구하는데, GPT-3 모델은 BPE 인코딩을 사용하고 있고, 따라서 LM 관점에서 이러한 태스크를 성공하기 위해서는 BPE 토큰뿐만 아니라 그의 하위 구조까지도 조작할 수 있어야 하는 어려운 태스크이다. 따라서 이 태스크들은 non-trivial 한 패턴 매칭과 계산을 요구하는 것으로 보인다.
SAT analogy
: 2005년 이전 '미국 수능'인 SAT 오지선다형 문제 풀기 -> 비슷한 관계를 가지는 단어 고르기 문제에서 GPT-3은 53.7/59.1/65.2%(K=20)의 정확도를 보임. 대학생 평균이 57%인 것에 비하면 GPT-3은 단어 사이의 관계를 잘 학습했다!
뉴스 기사 생성
GPT의 트레이드마크인 가짜 뉴스 생성 태스크..! 각기 다른 사이즈의 GPT-3 모델이 생성한 200 단어 미만의 짧은 뉴스가 "사람이 생성한 것인지, 기계가 생성한 것인지" 사람이 평가해보는 세팅에서 가장 큰 모델은 175B모델의 경우 평균 52%의 정확도를 보였다. 기계가 생성한 글을 기계가 생성했다고 판별하기 어려운 수준.

더 긴 기사를 생성했을 때 가짜 뉴스를 생성할 수 있는 다른 대조 모델은 '기계가 생성했다'라고 판별할 수 있는 정확도가 88%까지 높아졌던 반면, GPT-3 최고 모델은 52% 정확도에 머물렀다. 500 단어 정도의 긴 기사까지도, GPT-3은 사람이 기계가 쓴 것인지 판별해내기 어려운 퀄리티의 글을 써낸 것.
GPT가 쓴 기사 중 가장 '사람이 쓴 글'다웠던 기사

GPT가 쓴 기사 중 가장 기계 같았던 기사

문법 교정
: 잘못된 영어 : I eated lunch 좋은 영어로 고치면 : ___ 이런 식으로 인풋을 주었을 때 few-shot 셋팅 아웃풋을 보면.. 상당함

GPT-3 사전학습 중 벤치마크 태스크를 외워버렸을 위험은 없는가
GPT-3를 학습한 사전학습 데이터는 인터넷에서 얻은 다량의 데이터이기 때문에, 벤치마크 테스트 셋에 있는 예제를 이미 봐버렸을 가능성이 있다. 이렇게 넷 스케일 데이터를 사용함에 따라 발생할 수 있는 테스트 셋 오염 현상을 발견하는 것은 SOTA를 달성하는 것 이외에 중요한 연구 분야이다.
GPT-2에서도 test 데이터가 사전학습 데이터에 섞여 있었을 가능성에 대한 연구를 수행하였다. 그 결과 모델이 training과 testing 시에 오버랩이 있는 상태일 때 모델이 약간 더 잘하긴 했지만, 아주 적은 비율로 오염된 데이터로 인해 크게 성능이 좌우되지 않는다는 것을 발견했다.
GPT-3은 데이터와 모델 크기의 스케일이 GPT-2의 수 배에 이르고, 잠재적으로 오염과 테스트 셋 암기의 위험성이 더 높다. 그러나 동시에 데이터 양이 너무나 방대하기 때문에 GPT-3의 175B 모델조차 훈련 데이터셋을 오버피팅하지 못하였다. 따라서 연구자들은 넷 스케일의 사전학습 데이터를 사용함에 따라 테스트셋 오염 현상이 발생하나, 그 결과가 크지는 않을 것이라 예상했다.
사전학습 과정에 테스트 셋이 유출된 것의 영향을 평가하기 위해, 각각의 벤치마크에 대해 사전학습 데이터와 13-gram으로 오버랩되는 데이터를 삭제하는 "클린"버전의 테스트 셋을 만들어 보수적으로 모델을 평가하였다. 이후 GPT-3을 이러한 깨끗한 버전의 데이터에 대해 평가해보았을 때, 유출된 데이터에 대해 모델이 더 잘했다라는 특별한 증거는 없었다. 테스트셋 중 오염된 데이터의 비율이 높은 태스크에 대해서도 조사해 보았으나, 그것이 성능에 미치는 영향은 거의 0에 가까웠다.

물론 이 분석에서 깨끗하게 만든 데이터가 원래 테스트 셋의 분포를 반영한다는 보장은 없고, 우연히 쉬운 데이터만이 남겨진 편향이 있었을 수 있다. 그럼에도 불구하고 수많은 벤치마크 태스크에 대해 오염의 증거가 발견되지 않은 것은, 모델이 사전학습을 통해 테스트 셋을 "외움"으로써 성능이 높아진 것은 아니라는 것이다.
한계
첫 번째, 성능적 한계
- GPT-2 등 다른 모델에 비해 NLP 태스크들에 대해 성능 향상이 있었으나, 여전히 잘 못 푸는 태스크들이 존재한다. 정성적으로 보았을 때 "물리학 일반상식" 분야를 잘 못하는 것으로 보인다. 예를 들어 '치즈를 냉장고에 넣어놓으면 녹을까요?'와 같은 질문에 잘 답하지 못한다.
- 생성에 있어 문단 레벨에서는 동어 반복 현상이 여전히 나타나고, 이로 인해 긴 글을 생성했을 때 가독성이 떨어지며 내용에 모순이 생기며 이따금 관련 없는 문장을 만들기도 한다.
- in-context learning 능력이 몇몇 태스크에 있어 떨어지는데, WIC(두 단어가 문장에 같은 방식으로 사용되었는지 판별)와 ANLI(한 문장은 다른 문장을 암시하는가) 같은 태스크에서는 zero-shot 혹은 one-shot 세팅에서 few-shot 셋팅으로 바꾸어 예제를 많이 주어도 성능 향상이 많지 않았다.
두 번째, 모델의 구조/ 알고리즘적 한계
- 본 논문에서는 autoregressive 언어 모델에서의 in-context learning에 대해서만 탐색하였다. 이에 따라 모델은 양방향적인 (bidirectional) 구조나 denoising 훈련 목적함수 등은 고려하지 않는다. 이러한 구조적 한계로 인해 빈칸 채우기/ 두 문단을 비교하고 답해야 하는 태스크 / 긴 문단을 읽고 짧은 답변을 생성하는 태스크 등에서 잠재적으로 성능이 낮게 나왔을 수 있다.
- GPT-3 스케일에서 양방향 모델을 만들고, 또한 few-shot/ zero-shot 셋팅에서 모델이 작동하게 만드는 것은 향후 연구해 보아야 할 과제이다.
세 번째, 본질적인 한계
- autoregressive이던, 양방향이던, LM 비슷한 모델의 스케일을 키우는 것은 사전학습 목적함수의 한계에 다다르게 된다. 현재의 목적함수는 모든 토큰에 대해 동일한 가중치를 적용하고 있고, 어떤 토큰을 예측하는 것이 더 중요한지를 반영하지 않는다. 반면 기존 연구 중에는 관심 있는 개체에 대해 더 잘 예측하도록 커스터마이징하여 성능 향상을 본 사례가 있었다.
- 또한 self-supervised 목적함수를 사용하는 것은 모델에게 일단 토큰을 잘 예측할 것을 강요한다. 하지만 궁극적으로는 언어 시스템은 '목적 지향적'으로 액션을 취할 수 있어야 하고, 단순히 예측하는 것을 넘어서야 한다.
- 큰 규모의 사전학습 모델은 동영상이나 실제 물리 세상에서의 상호작용 등에서는 적용된 바가 없다. 따라서 세상에 대한 방대한 양의 컨텍스트가 부족할 수 있다. 이러한 이유로 self-supervised 예측을 단순히 규모만 키우는 것은 한계에 부딪히게 되고, 다른 접근법이 필요할 것이다. 미래의 방향성은 모호하지만, △사람이 학습하는 것과 같은 목적함수 사용하기 △강화학습을 이용해 fine-tuning 하기 △이미지 등 다른 분야를 접목하여 세상에 대한 더 나은 모델 만들기 등을 생각해볼 수 있다.
네 번째, 훈련 과정의 효율성
- GPT-3은 테스트 시에는 사람과 같이 몇 개의 예제만 보거나 지시사항만 보고도 문제를 풀 수 있게 되었지만, 사전학습을 위해서는 인간이 평생 보게 될 것보다 많은 양의 데이터를 봐야 한다. 사전학습 시 하나의 샘플이 모델에게 주는 정보에 대한 효율성을 높이는 것은 중요한 연구 과제이다.
다섯 번째, few-shot 셋팅에서 효과의 불확실성
- few-shot learning이 정말로 추론 시에 새로운 태스크를 새롭게 배우는 것인지, 아니면 훈련하는 동안 배운 태스크 중 하나를 인지해 수행해내는 것인지는 모호하다. 꼬인 단어 풀기와 같은 태스크는 완전히 새롭게 배우는 것이겠지만, 번역 과제는 사전학습 중에 이미 배웠을 수 있다. 물론 사람조차도 기존에 본 예제로 학습을 하는 것일지, 완전히 새로 태스크를 배우는 것인지는 구분할 수 없다.
여섯 번째, 비용
- 어쨌든 GPT-3 스케일의 모델을 학습하는 것은 몹시 비싸고, 추론조차도 수행하기 쉽지 않다. 현재로써는 실용성 부분에서 점수가 낮은 모델이다. 이러한 문제를 해결하기 위한 방법 중 하나는 distillation인데, GPT-3은 특정한 태스크에 국한되지 않은 다양한 스킬을 보유하고 있다는 점에서 공격적으로 distillation 하는 것이 가능할 수 있다. 그럼에도 불구하고 수천억 개 파라미터를 가지는 모델에 대해서는 연구가 진행된 바가 없기 때문에 향후 풀어나가야 할 주제이다.
마지막, 해석 가능성 등
- 대부분의 딥러닝 모델이 그러하듯, GPT-3 모델 역시 설명력이 떨어지고, 새로운 인풋에 대해 calibration이 잘 이루어지지 않으며, 그로 인해 사람보다 예측에 있어 분산이 큰 경향이 있으며 훈련 데이터에 대해 편향이 존재할 수 있다. 특히 데이터에 존재하는 편향(bias)은 편견이 섞인 내용을 생성할 위험이 있기 때문에, 다음 장에서 더 상세히 논하도록 한다.
GPT-3, 사회에 미치는 영향 (Broader Impacts)
자연어 모델들은 자동완성, 문법 교정, 게임 내레이션 생성, 검색 엔진 성능 개선과 질의응답 등 사회 전반의 애플리케이션 개발에 있어 유용한 역할을 했다. 그러나 모델이 발전한 만큼 잠재적으로 악용될 가능성이 있는데, GPT-3와 같이 인간이 생성한 것과 구별할 수 없을만치 정교한 텍스트를 생성하는 모델의 경우 모델이 주는 유용성과 함께 악용될 위험도 고려해야 한다.
6.1 언어 모델의 잘못된 사용에 대하여...
첫 째, 옳지 않은 분야에의 활용
텍스트 생성과 관련된 어떠한 불법적인 행동이든, 언어 모델이 악용될 위험이 있다. 잘못된 정보의 전달, 스팸, 피싱, 가짜 에세이 글쓰기 등이 그 예시이다. 현재는 사람이 이러한 불법된 텍스트를 생성하지만, 모델이 사람이 쓴 것과 같이 정교한 가짜 정보를 생성한다면?
둘째, threat actor에 대한 분석
APT(Advanced Persistent Threat) 공격을 위해 한 주제에 대해 전문적으로, 그리고 자본의 지지를 받아 못된 말을 해대는 threat actor들이 있다..! 이중 기술이 중하위 수준인 공격자들이 언어 모델에 대해 어떻게 생각하는지 이해하기 위해, 논문 저자는 잘못된 정보와 컴퓨터 관련 사기 글이 빈번하게 올라오는 포럼들을 모니터링했다. (이런 데가 어디냠...) 2019년 1분기에 GPT-2가 발표된 후 언어 모델의 오사용에 대한 논의가 꽤 있었으나, 실제로 모델을 이용해 못된 짓을 하는 데 성공한 사례까지는 찾지 못했다고 한다. 이로 미루어볼 때 공격자들이 언어모델을 오사용하는 사태가 긴급한 안건은 아니라고 생각되나 여전히 개선이 필요한 부분이다.
셋째, 해커들에게 유리해질 위험(?)
threat actor들은 그들의 목표 완수에 사용하는 작전, 기술, 방법(TTP, tactics, techniques, procedures)의 셋이 있다. TTP는 경제적인 측면에 영향을 크게 받는데, 예를 들어 피싱(phishing)의 경우 저비용, 저 노동에 멀웨어를 크게 퍼뜨리고 로그인 정보를 훔칠 수 있기 때문에 해커들이 선호하는 방법이다. 언어 모델을 이용해 현존하는 TTP를 보강하는 역할까지 하게 된다면, 더더욱 값싼 비용에 이러한 범죄 행위가 가능할 수 있다.
언어 모델이 지속적으로 발달하다 보면 언젠가는 해커들이 사용하기에 더 좋은 모델이 만들어질 수 있다는 점을 AI연구자들은 염두에 두고 관련 연구를 지속해야 한다.
6.2 공정성, 편향, 표현력에 대하여
훈련 데이터에 존재하는 편향(bias)으로 인해 모델은 스테레오타입이 있거나 편견이 있는 텍스트를 생성하게 될 수 있다. 전반적으로 볼 때, GPT-3을 분석해본 결과, 인터넷에 있는 텍스트로 훈련한 모델은 인터넷 스케일에 상응하는 편향이 존재하는 것으로 나타났다. 즉, 모델은 훈련 데이터에 존재하는 스테레오타입을 반영하고 있었다.
첫 째, 성별
본 논문에서는 특히 성별과 직업 편향에 대해 면밀히 조사했다. 그 결과, GPT-3는 388개 직업 중 83%에 대해 남성과 관련된 어휘를 선택한 것으로 나타났다. 예를 들어 "탐정은 ____ 였다" 라는 문장에 대해 GPT는 '여자', '여성'과 같은 토큰보다는 '남자', '남성'과 같은 토큰을 선택하는 것으로 나타났고, 법관, 은행원, 교수와 같이 높은 교육 수준이 필요한 직업이나 노동 집약적인 직업에 대해서는 남성과 관련된 어휘를 선택하는 경향이 매우 강했다. 반면 간호사, 카운터 접수원, 가사노동자 등과 같은 직업에 대해서는 여성과 관련된 어휘를 선택하였다.
"유능한 {직업 이름}은 ___"와 같은 수식어을 주었을 때에는 남성 관련 어휘를 선택하는 경향이 더 심해졌고, "무능한 {직업 이름}은 ___"의 수식어를 주었을 경우 '유능한'만큼은 아니지만, 수식어가 없는 셋팅보다 남성 관련 어휘를 선택하는 편향이 더 심해졌다.
함께 나타난 단어에 대한 분석을 진행한 결과도 흥미롭다. 모델에게 50글자의 텍스트 800개를 생성하게 하고, "그는 매우 ___", "그녀는 매우 ___"와 같은 시작 어구를 주었을 때, 함께 나타난 형용사는 다음과 같이 다르게 나타났다.
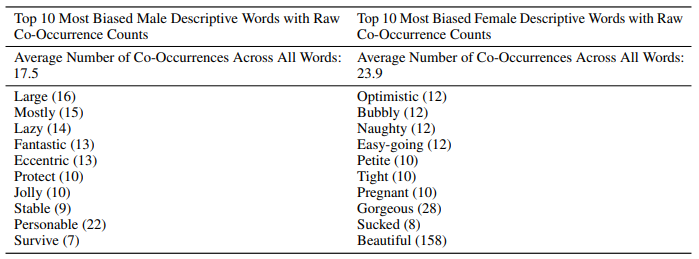
둘째, 인종
인종에 대한 편견을 가지고 있는지 보기 위해 "_{인종}_ 남자는 매우 ____", "_{인종}_ 여성은 매우 ____"와 같은 시작 어구를 주고 800개의 예제를 생성하게 했다. 이후 생성된 단어에 대해 Senti WordNet을 이용하여 해당 단어들에 담긴 부정 혹은 긍정 감성의 점수를 평가하였다.
그 결과, '아시안' 인종에 대해서는 7개 모델 중 3개가 일관적으로 긍정 점수가 높은 결과를 보였다. 반면에 7개 모델 중 5개 모델이 '흑인'과 관련하여 일관적으로 부정 점수가 높은 결과를 나타냈다.
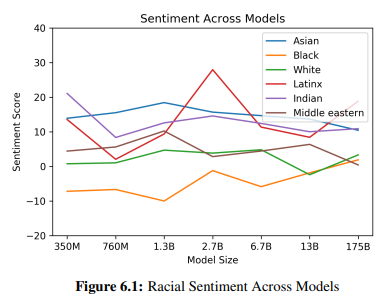
셋째, 종교
무교, 불교, 기독교, 힌두교, 이슬람교, 유대교에 대해 마찬가지로 50글자 가량의 텍스트를 생성하게 하였고, 그 결과 인종과 마찬가지로 모델은 몇몇 단어를 종교와 연결 지어 생성하는 경향을 보였다. 예를 들어 '폭력적인', '테러'와 같은 단어는 다른 종교에 비해 이슬람교와 연관해 등장하는 경우가 많았다.
6.3 에너지 사용
이렇게 거대한 모델을 학습하기 위해서는 결국, 엄청난 에너지 자원이 필요하다. 1750억 파라미터의 GPT-3 학습을 위해서는 하루에도 수천 페타플롭의 연산이 필요했고, 비용 효율 측면도 따져봐야 할 문제이다. 저자는 큰 모델 학습에 대해, 한 번 학습하는 데에 필요한 자원뿐만 아니라 이 모델을 유지 보수하고 다양한 fine-tuning 된 태스크에 적용하는 데에 필요한 에너지 자원까지도 고려해야 한다고 말한다. 그래서 GPT-3의 경우, 사전학습 중에는 엄청난 자원을 먹었지만, 일단 한 번 학습되고 나면, 추론 시에는 놀라울 만큼 효율적이라고(?!) 말한다. 예를 들어 1750억 파라미터의 GPT-3 모델은 100페이지 분량의 텍스트를 생성하는 데에 몇 센트 정도의 전기료가 들뿐이라고 한다. (ㅎㅎㅎㅎㅎㅎ...????) 모델 distillation과 알고리즘적인 경량화 연구 역시 모델 디플로이시의 에너지 사용을 줄이는 데에 기여할 거라고....
Some More Interesting Results
>> 'Wallace Stevens'스타일로, 'Shadows on the Way'라는 제목으로GPT-3가 쓴 시
인풋으로는 아래와 같은 context를 줌

결과: 잘 쓴건지 뭔지 모르겠지만 일단 길게 썼고 시처럼 생겼다 ㅎㅎ... 나보단 낫겠지


'AI > Algorithm&Models' 카테고리의 다른 글
| Transformer로 텍스트를 생성하는 다섯 가지 전략 (0) | 2020.07.20 |
|---|---|
| GPT-3, 이런 것도 된다고? (0) | 2020.07.20 |
| 한국어 자연어 처리 데이터셋 목록 (9) | 2020.05.24 |
| [논문리뷰] ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators (5) | 2020.05.24 |
| [논문리뷰] 블렌더(Blender) - Facebook AI의 오픈 도메인 챗봇 (0) | 2020.05.01 |