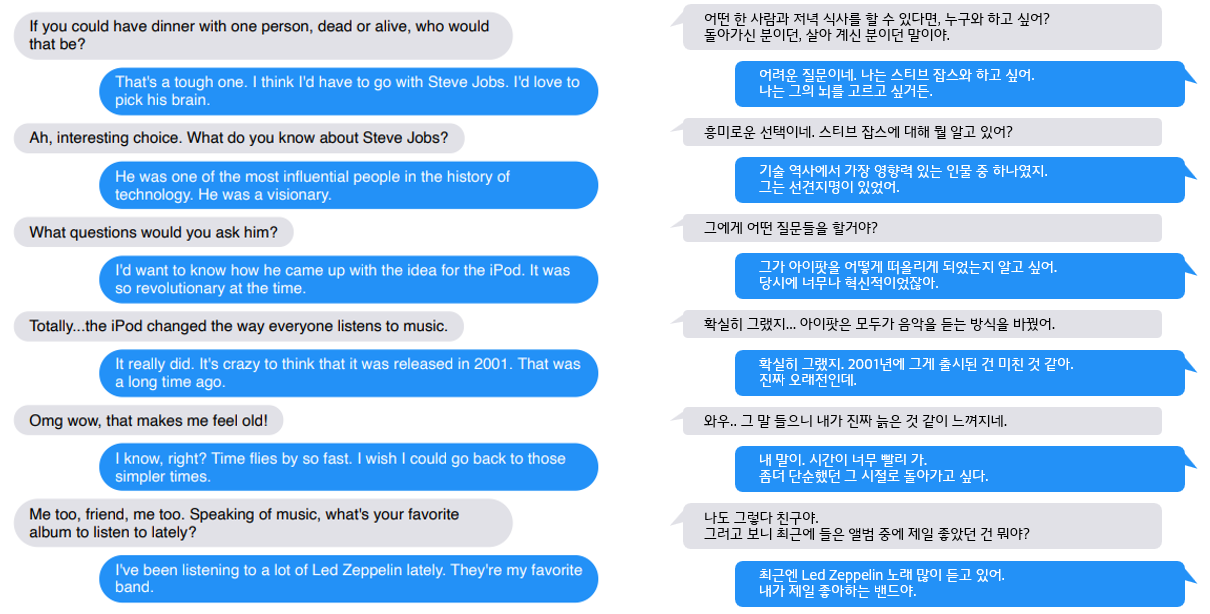
BLENDER
> 페이스북 AI에서 발표한 오픈 도메인 챗봇 모델
> 대화에 적절히 개입하고, 지식과 강세, 페르소나를 나타내면서 멀티턴 대화에서 일관적인 성격을 유지하는 것에 초점
> 90M, 2.7B, 9.4B 개의 파라미터를 가지는 모델을 공개함
> 사람이 평가해보았을 때, 멀티턴 대화 시스템에서 호응도(engageness)와 사람다움(humanness)에서 다른 모델을 능가
> 특히 구글의 Meena와 비교할 때 호응도 25~75% 개선, 사람다움이 35~65% 개선되었다고 봄.
"오픈 도메인 챗봇을 만드는 레시피를 제공합니다"
기존의 오픈 도메인 챗봇 연구에 따르면 뉴럴넷 파라미터 수와 데이터 크기를 늘리면 성능 향상에 효과가 있었다.
본 논문에서는 단순히 모델 크기를 스케일링하는 것 이외에 아래 두 가지 접근법이 유용하다고 말한다.
(1) 블렌딩 스킬 - Blended Skill Task(BST) 셋업 사용
본 논문에서는 성격과 개입, 지식, 강조 등 모델에게 학습시키고자 하는 부분에 초점을 맞춘 태스크를 선택하고, BST 셋업으로 훈련하였다. BST는 훈련 데이터와 초기 대화 컨텍스트 (페르소나&주제)를 통해 학습시키고자 하는 특성에 초점을 맞추게 하는 학습법인데 다음의 두 가지 장점이 있는 것으로 나타났다:
> 작은 모델로도 좋은 성능 - BTS를 사용한 작은 모델은 이를 사용하지 않은 큰 모델보다 성능이 좋았다.
> 모델에게 적합한 특성 학습 - BTS는 바람직한 측면을 강조함과 동시에 수많은 코퍼스를 학습하다 보면 모델이 학습하게 될 수 있는 나쁜 측면은 억제하였다.
(2) 생성 전략
NLG에서 디코딩 알고리즘은 크리티컬한 부분 중 하나인데, 같은 perplexity를 가지는 모델이라도, 다른 디코딩 전략을 사용하면 그 결과가 아주 다를 수 있다. 기존 연구들에서는 beam search가 sampling 전략보다 좋지 않다는 결과가 있었지만, 본 논문에서는 search 파라미터를 잘 설정하면 트레이드오프를 제어하면서 좋은 결과를 얻을 수 있다는 점을 밝힌다. 특히, 최소 beam level을 조절함으로써 답변의 단순함과 흥미로운 정도를 조절할 수 있다.
생성 전략은 특히 봇에 대한 사람의 평가에 영향을 미치는데, 길이가 너무 짧고 응답이 무던하거나, 지나치게 장황하여 말이 많으면 봇이 사람 말을 듣고 있지 않다고 판단하기 때문이다.
모델 아키텍처
Retrieval, Generative, Retrieve-and-refine 세 타입의 아키를 고려함. 각각은 트랜스포머 구조를 사용.
(1) Retrieval
> 대화 이력을 인풋으로 받아 다음 대화 발화문을 선택하는 아키텍처
> 아주 큰 후보 답변 세트에 대해 스코어링을 해서 가장 높은 점수를 받은 발화를 리턴하는 방식
> 훈련 데이터에 있는 모든 답변을 후보 답변 집합으로 사용함
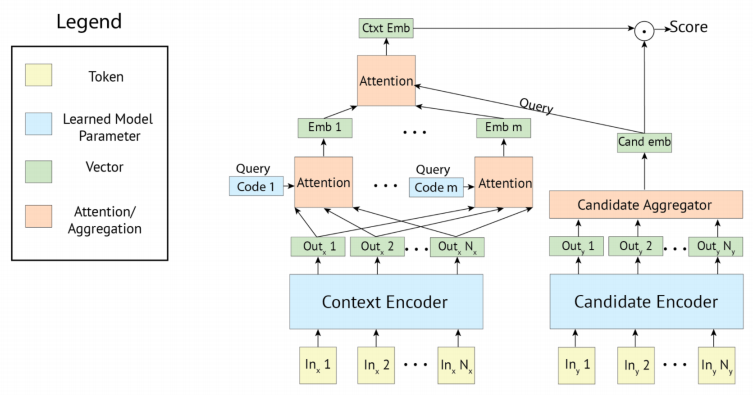
Retrieval에서는 poly-encoder 구조를 사용하였다.
Poly-encoder은 여러 representation(N개의 코드들)을 사용해서 문맥의 전체적인 특성을 인코딩하고, 이 인코딩 된 특성들은 각각의 가능한 후보 답변들에게 attend 된다. 이 attention 메커니즘을 사용할 때 하나의 글로벌 벡터 representation을 사용하는 것보다 성능이 좋았고, 계산적으로 여전히 가능한 수준이었다. 참고로 poly-encoder은 다양한 대화 모델에서 SOTA 성능을 보이는 알고리즘이다.)
논문에서는 256M, 622M 파라메터 두 가지 poly-encoder을 고려하였고, 코드 개수에 대한 파라미터는 N=64로 설정했다.
(2) Generator
> 일반적인 Seq2Seq 트랜스포머를 사용하는 모델
ParlAI에서 사용한 버전을 사용해 구현하였고, 사전학습 데이터에 대해 훈련한 BPE 토크나이저를 사용했다.
90M / 2.9B / 9.4B 파라메터를 가지는 세 가지 모델을 고려하였는데, 9.4B 모델은 4층의 인코더 레이어, 32층의 디코더 레이어, 4096 차원 임베딩 with 32개 attention head를 가진다. 2.7B 모델은 2층의 인코더, 24층의 디코더, 2560 차원 임베딩 with 32개 attention head를 가진다.
(3) Retrieve and Refine
> 생성 이전에 무언가를 받고, 답변을 생성함
> 일반적인 생성 모델은 외부 지식에 직접적으로 접근하지 못하는데, 모델에 내포되어 있는 정보는 부족하기 때문
> 대화 retrieval과 지식 retrieval 두 가지를 고려함
Dialogue Retrieval
먼저 (1)의 retrieval model을 사용해 대화 이력이 주어질 때 답변을 받아오고, 이를 generator의 인풋으로 [대화 이력 + 스페셜 토큰 + 받아온 답변]을 넣어 답변을 생성하게 하는 방법. retrieval 모델은 사람이 실제로 사용하는 생동감 있는 답변이기 때문에 생성 모델은 필요할 경우 copy 알고리즘을 통해 더 나은 답변을 제공할 수 있다.
Knowledge Retrieval
위의 방법에서 답변 대신 거대한 지식 베이스에서 외부 지식을 받아오는 방법. 이 모델은 Wizard of Wikipedia task를 풀기 위해 고안되었기 때문에, 이 모델은 Wizard Generative model이라고 부른다. 대화에서 지식을 어떻게 사용해야 하는지 지도 학습으로 학습하기 위해 Wizard of Wikipedia task를 사용하였기 때문이다. 이 시스템에서는 TF-IDF 기반으로 위키 덤프에서 관련 지식을 찾아오고, Transformer retrieval model을 이용해 후보에서 필요한 하나의 문장을 골라 생성에 조건부로 사용한다. 추가적으로 트랜스포머 기반의 분류기를 사용해 retrieval을 사용할지 말지를 각 턴마다 판단하도록 하여, 외부 지식이 불필요할 경우 지식을 받아오는 과정은 생략하게 하였다.
훈련 목적 함수
Retrieval을 위한 랭킹
> Cross-Entropy loss 사용
> 올바른 후보 (y_cand1) 이외에 나머지 (n-1) 개 후보는 negative sampling으로 생성
> 훈련 중에는 배치로 negative sample을 생성해 각 후보에 대한 임베딩을 재사용하여 학습 속도를 증가.
> 또한 이 방법을 통해 큰 배치로 훈련 가능 (512)
생성 태스크
> 일반적인 Likelihood 방법으로 학습 (MLE)

Retrieve & Refine에서 알파-블랜딩 사용
> 단순히 받아온 답변을 이어 붙여 MLE로 학습했을 때는 결과가 좋지 않았음.
> 이는 받아온 답변과 정답 답변(gold label)과의 관련성이 명확하지 않아 모델이 답변을 무시한 채 생성하기 때문.
> 받아온 답변을 모델이 확실하게 사용할 수 있도록, 학습 중 alpha%만큼은 정답 답변 대신 받아온 답변을 생성하게 함.
> 이를 통해 retrieval과 generator-only 모델 사이의 간극을 스무딩 할 수 있음.
생성 태스크에서 unlikelihood training
> unlikelihood loss(UL)를 사용하면 동어 반복을 줄이고 overrepresented 토큰 문제를 완화할 수 있다는 연구가 있었음.
> 이 방법에서는 각 타임 스텝에서 어떤 토큰의 집합에 대해 페널티를 부과함.
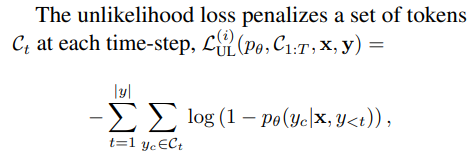
> 전체 loss는 MLE와 UL을 가중합 한 형태
> likelihood는 전체 시퀀스의 확률 분포를 모델링하고자 하는 반면, unlikelohood는 바이어스를 수정하는 역할을 함.
> 구체적으로 각 타임 스텝에서 negative candidate에 대해 likelihood는 GT 토큰의 확률을 끌어올리고, UL은 negative candidate에 있는 토큰에 대한 확률을 끌어내리는 식으로 작동함.
> 특히 훈련과정 동안 모델 생성 문장에 대해 n-gram의 분포를 트래킹 하고, 사람이 생성한 발화보다 그 개수가 더 많은 n-gram을 negative candidate로 활용함으로써 모델이 같은 어구만 계속 생성하는 현상을 막을 수 있음.
디코딩
본 논문에서는 잘 알려진 디코딩 방법들을 테스트해보고 비교 분석하였다.
> Beam Search
> Sampling
> Response Length - beam으로 생성하면 일반적으로 너무 짧게 생성. minimum length와 predictive length 고려
> Subsequence Blocking - 동어 반복 문제를 해결하기 위해 반복되는 n-gram을 방지함
훈련 디테일
랭킹 모델 / 생성 모델 사전학습
랭킹모델 - Fairseq 툴킷을 통해 사전학습 진행
- 256M 모델 = <fairseq: A fast, extensible toolkit for sequence modeling>
- 622M 모델 = 같은 모델에 대해 MLM loss로 사전학습
- 모든 하이퍼파라메터는 RoBERTa 모델과 동일
생성 모델도 마찬가지로 Fairseq로 사전학습
- 2.7B & 9.4B 모델 : Adam 옵티마이저로 훈련
데이터 : pushshift.io Reddit
Fine tuning
ParlAI 툴킷을 사용해 finetuning : 대화 모델 훈련 & 평가에 특화된 툴킷!
> 사전학습과 달리 GPipe 스타일의 모델 병렬화를 통해 레이어가 각기 다른 GPU에서 공유되고, 각각의 미니 배치는 더 작은 마이크로 배치로 분화되어 최대의 throughput을 유지하도록 하였다.
> Adam 옵티마이저가 좋았고, Fairseq 스타일의 mixed precision 학습을 하였다.
> 1e-6 ~ 1e-5 사이의 learning rate에서 fine-tuning 모델은 수렴하였다.
데이터 : ConvAI2 / Empathetic Dialogues (ED) / Wizard of Wikipedia (WoW) / Blended Skill Talk

Safety Characteristics
모델이 결국 사람 대화에서 배우기 때문에, 불순한(!) 특성도 학습해버릴 수 있음.
fine-tuning에서 사용한 BTS 태스크들은 크라우드 워커들이 가이드에 따라 생성한 것이기 때문에, 사전학습에서 사용한 레딧 발화보다는 안전할 것이다. 하지만 모델이 나쁜 말을 하지 않게 하기 위해 "나쁜말 분류기"를 만들고, adversarial하게 나쁜말 데이터를 수집하여 분류기가 더 강건할 수 있도록 만들었다. 테스트 시에는 발화를 최종적으로 내보내기 전에 나쁜말 분류기를 통해 한 번 더 검사를 했다. 그럼에도 불구하고, 실험 결과 이런 보조 안전장치도 완벽하지 않은 것으로 나타났다.
평가 방법
ACUTE_Eval
> 기계적인 평가 지표를 논문에 포함했지만, 핵심적인 평가 방법은 ACUTE-Eval에 있음.
> 이 방법에서는 두 개 대화 쌍에 대해 어떤 대화가 더 나았는지 선택하도록 하여 평가자마다 생길 수 있는 점수에서의 편향 문제를 없앨 수 있음.
> 사람 평가자는 두 개의 긴 대화를 보고, 다음의 두 가지 질문에 답해야 함 :
a. 길게 대화를 할 때, 어떤 챗봇(speaker)과 대화하고 싶나요?
b. 어떤 챗봇(speaker)이 더 사람처럼 느껴지나요?

Self-Chat ACUTE-Eval
> 사람이 모두 평가하는 것은 비싸기 때문에, self-chat 모드에서 봇끼리 대화하게 하여 성능을 평가함
실험 결과 섹션... 너무 길다. 다음에 읽어봐야징 ㅎㅎ 예시만 휙휙 보자!
예시들 보니 멀티 턴 대화에서 맥락을 유지하면서 잘 대답하는 것 같음.
잘 된 예시로 고른 것이지만, 유식하고 (외부 지식 활용 good) 자연스럽게 대화를 잘 이어나가는 게 신기함.
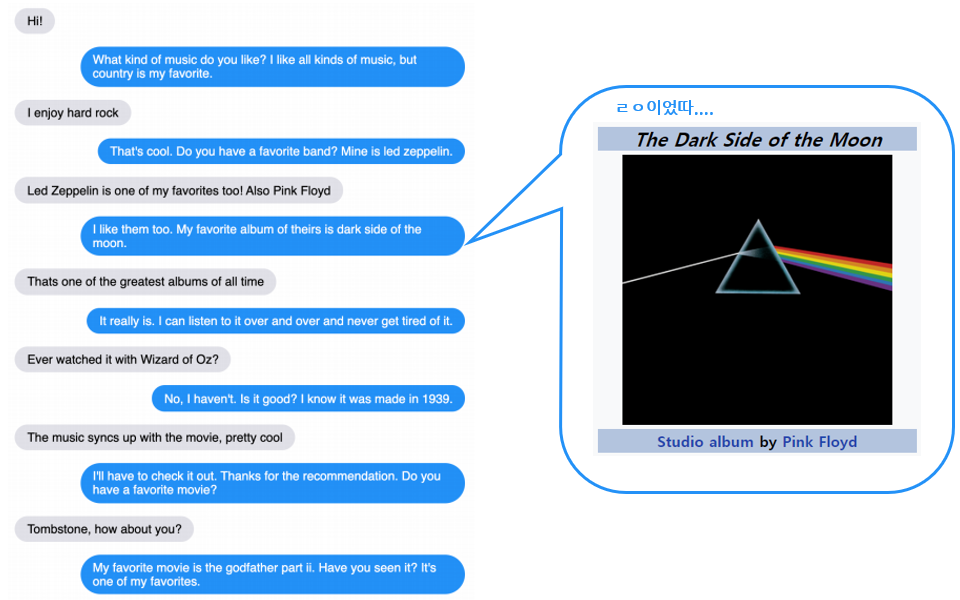
페르소나를 가질 수도 있음 (9.4B generative 모델 예시)

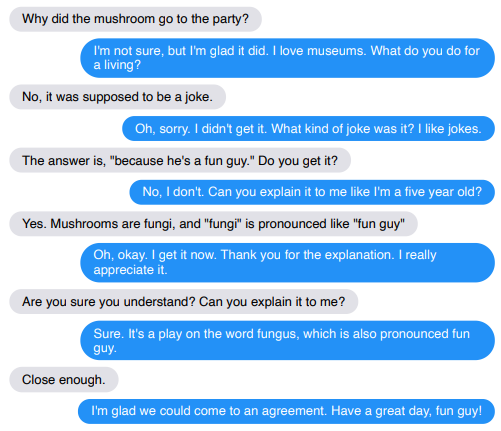
실패 케이스도 있는데... 영어 쪼크 못 알아듣는 것이 남 일 같지가 않다 ㅎㅎㅎ.....

Discussion
(1) Best 모델조차도 여전히 실수를 한다
- 한 대화 안에서 말을 반복하거나, 한 말 사이에 모순이 생김
- 다른 대화에서 같은 어구를 반복해 생성함
- hallucinate knowledge
(2) 14 턴 이내의 짧은 대화에 대해 사람 평가를 진행했는데, 더 긴 턴의 대화는 더 못 할 것.
- 일단 긴 대화는 트랜스포머 구조적으로 대화 히스토리를 주는 데에 한계가 생김.
- 낙관적인 측면은, 긴 메모리를 위한 연구가 진행되어 왔고, 꽤 성과가 있었음!
- 하지만, 평가 역시 만만찮은 과업인데, 더 긴 대화를 모으고 평가를 진행해야 하기 때문. 대안으로, 대화에 대해 주제와 같은 시드를 주고, 평가 과정 중 사람 대화자가 주제에 좀 더 초점을 맞추어 대화를 이어나감으로써 봇의 능력을 더 철저히 검증할 수 있을 것.
- 모델링 측면에서는 긴 대화를 하게 하면 봇에게 어떤 맥락 정보를 줄 것인지가 더 중요해짐.
- BST에서 문맥 초기에 주어지는 페르소나와 주제는 대화에서 흥미로운 발화를 유도하는데, 긴 대화를 위해서는 이러한 설정을 더 상세하게 해야 할 것.
(3) 챗봇 디플로이에 있어 '바른 행동을 하게 하는 것'은 여전히 과제로 남아 있음.
- 봇이 사람 평균보다 더 결함이 없길 기대하는데, 사실 봇은 그들이 하는 말이 뭔지 잘 이해하고 있지 않음.
- 나쁜 말(toxic language)을 사용하지 않고, 성차별적인 발언을 하지 않게 하는 연구가 진행되어 왔지만, 아직 갈 길이 멀다.
(4) perplexity 이외에 고려해야 할 사항들...
- perplexity와 사람의 평가가 상관관계가 있다는 등 논문이 있었고, perplexity는 오랫동안 표준적인 object로 사용되어 옴.
- 물론 perplexity도 중요하지만...
. 훈련 데이터 선택도 중요함
. 디코딩 알고리즘에 따라 같은 perplexity를 가지는 모델이라도 다른 결과를 냄
- 실험에서 9.4B 모델은 2.7B 모델보다 perplexity는 낮았지만, 사람 평가에서 눈에 띄게 좋다는 평가를 받지는 못함. 낮은 perplexity를 달성하는 것 못지않게, 디코딩 알고리즘이 좋은 결과를 내는 데에 중요할 수 있다.
#논문 리뷰 #NLG #챗봇 #대화모델

'AI > Algorithm&Models' 카테고리의 다른 글
| 한국어 자연어 처리 데이터셋 목록 (9) | 2020.05.24 |
|---|---|
| [논문리뷰] ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators (5) | 2020.05.24 |
| [논문리뷰] CTRL - 자연어 생성을 위한 조건부 트랜스포머 언어 모델 (0) | 2020.04.26 |
| AutoML-Zero: 'zero' 에서부터 스스로 진화하는 기계학습 알고리즘 (2) (1) | 2020.03.13 |
| AutoML-Zero: 'zero' 에서부터 스스로 진화하는 기계학습 알고리즘 (1) (0) | 2020.03.13 |