CTRL - Conditional Transformer Language Model for Generation
논문 >> https://arxiv.org/pdf/1909.05858.pdf


CTRL은 세일즈포스닷컴(Salesforce)에서 2019년에 발표한 조건부 자연어 생성 모델이다. 텍스트 생성을 명시적으로 통제하기 위해 '컨트롤 코드(control code)' 를 도입하여 이에 조건부인 언어 모델을 학습하고, 모델이 생성하는 텍스트에 대한 특성을 더 명시적으로 표현하였다. CTRL은 Transformer 기반의 모델로, 16.3억개의 파라메터를 가진다.

컨트롤 코드란?
컨트롤 코드는 도메인, 스타일, 주제, 날짜, 개체, 개체간의 관계, 태스크와 관련된 행동 등을 통제하는 prefix같은 것이다. 모델을 비지도학습 방식으로 학습하기 위해 컨트롤 코드는 language model 학습에 사용할 raw 텍스트와 자연스럽게 함께 일어나는 구조를 활용하였다.
> 예를 들어 위키피디아, Project Gutenberg, 아마존 리뷰 등은 도메인과 관련된 컨트롤 코드로 사용
> subreddit의 도메인 이름을 활용
> URL에 관련된 정보가 있다는 것을 활용함
> 컨트럴 코드로 인해 시작 부분이 동일하더라도 도메인에 따라 예측 가능하게 다른 컨텐츠가 생성됨.
도메인에 따른 스타일 - 같은 명령어(prompt)에 대해서도 컨트롤 코드에 따라 (예측 가능한) 다른 스타일의 텍스트가 생성되고, 명령어 없이도 도메인 특징적인 텍스트를 생성할 수 있음.
도메인 prefix에 따라 생성된 텍스트의 문체에 차이가 있음.



복잡한 컨트롤 코드 - 도메인 코드에 더해 추가적인 컨트롤 코드를 더해 생성에 있어 제한 사항을 추가할 수 있음. 예를 들어 모델에게 '제목으로 시작하고, 리뷰에 대해 평접을 남겨라' 라는 제한 사항을 줄 수 있음. 더 나아가 OpenWebText에서는 URL을 이용해 각 문서를 다운로드하였고, 이 URL을 인풋 시퀀스의 맨 앞에 붙여주었는데, 따라서 훈련 과정동안 CTRL은 UTL을 이용해 도메인, 서브도메인, 객체, 객체와의 관계, 날짜 등을 특정하는 방법을 학습함.
아래의 예시를 보면 알겠지만, 이는 URL에 신문사 이름과 발간 날짜가 포함되어 있고, URL에 기사 제목이 포함되어 있기 때문에 가능했던 것으로 보인다.

특정 태스크를 시작하기 - 질의응답, 번역 등의 태스크를 시킬 수도 있음. 이는 Google의 T5에서 태스크를 prefix로 준 것과 비슷한 느낌이다.

zero-shot 코드 믹스 - 두 개 이상의 컨트롤 코드를 섞어서 사용할 수도 있다.
CTRL의 언어 모델링
일반적으로 언어 모델링(language modeling)의 목적은 길이가 n인 단어의 시퀀스 x = (x_1, ..., x_n)에 대해 이러한 시퀀스의 확률 p(x)를 학습하는 것이다. 이때 문장 x는 시퀀스이기 때문에 확률의 체인룰을 이용해 'i 번째 단어 이전의 단어가 주어질 때 i번째 단어를 맞추는 문제'로 모델링할 수 있다.

즉, 언어 모델링은 '다음 단어 맞추기' 문제로 생각할 수 있고, 현재의 SOTA 알고리즘(Transformer-XL등)은 뉴럴넷을 이용해 데이터셋 D = {x^1, ..., x^|D|}에 대해 negative log-likelihood를 최소화하는 파라메터를 찾는 방식으로 모델을 훈련하고 있다.
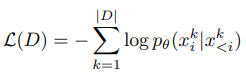
CTRL은 일반적인 언어 모델링과 다르게, 컨트롤 코드 c에 조건부로 문장 시퀀스의 확률 p(x|c)을 학습한다.

컨트롤 코드는 전반적인 생성 과정을 제어한다. 참고로, 이는 문장의 첫 토큰 x_0를 샘플링할 때도 관여를 하는데, 이는 전통적인 언어 모델링 프레임워크와는 다른 방식이다.
MODEL
CTRL은 텍스트의 앞에 컨트롤 코드를 붙인 시퀀스에 대해 학습된다. 모델은 Transformer 구조를 활용한다.
1) 토큰 임베딩 - 길이 n인 시퀀스의 각 토큰을 d차원의 벡터로 임베딩, 이때 토큰 임베딩에 sinusoidal 위치 임베딩을 더해 사용
2) Attention
- 임베딩된 벡터의 시퀀스는 행렬 X_0 (nxd차원)로 적재하여 l개의 attention 레이어에 태움.
- 여기서 i번째 레이어는 두 개의 블록으로 이루오져 있고, 각각은 모델의 차원 d를 유지함.
- 첫 번째 블록은 k개 head를 가지는 multi-head attention. 이때 미래의 토큰에는 attend할 수 없게 casual mask를 사용

- 두 번째 블록은 Feed forward 네트워크 + ReLU 활성함수를 활용하여 multi-head attention의 결과 벡터를 f차원으로 한 번 변환했다가 다시 d차원으로 변환함.

- 각각의 블록에는 layer normalization을 적용하고, residual connection을 적용하여 X_{i+1}을 생성함

3) Score 계산 - 마지막 레이어의 아웃풋을 이용해 각 토큰에 해당하는 단어를 계산함.

훈련 과정 중에는 cross-entropy loss 함수를 이용해 학습하고, 추론 시점에는 마지막 레이어에서 나오는 토큰을 Softmax 함수로 정규화하여 새로운 토큰을 샘플링하기 위한 분포로 사용한다.
생성 방법
학습된 언어 모델을 이용해 생성(or 추론)할 때는 temperature-controlled stochastic sampling을 사용하고, top-k 확률을 가지는 토큰에서만 샘플링하는 것이 일반적이다. temperature T>0와 사전에 있는 토큰 i (x_i)에 대한 점수가 주어질 때, i번째 토큰으로 예측할 확률은 다음과 같이 쓸 수 있다:

다음 토큰은 p_i가 가장 높은 top-k개 토큰에 대해 multinomial distribition에서 샘플링하는 방식으로 결정된다. 위 식에서 T→ 0이면 greedy 알고리즘, T가 무한대에 가까워지면 랜덤하게 토큰을 만드는 것과 같아진다. top-k에서 k는 하이퍼파라메터로 정하기보다는 휴리스틱하게 변하는 방식을 채택했다. 구체적으로는 threshold p_t를 두고, k는 sum(sort(p_i)) > p_t가 되는 k를 선택하는 방식으로 결정된다.
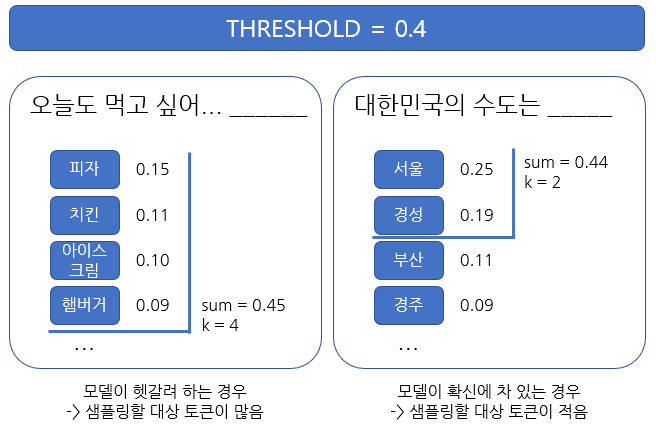
penalized sampling
전제 Q: What is the capital of Austrailia? (Q: 호주의 수도는?)이 주어졌을 때, 잘 학습된 모델은 정답인 'Canberra'에 가장 높은 확률이 나오고, 이외에 다른 멜버른, 시드니 등의 도시에 대해 0이 아닌 어떤 확률값을 줄 것이다. 이런 경우, 샘플링을 통해 토큰을 결정하게 되면 잘못된 말을 생성할 수 있기 때문에 greedy하게 생성하는 것이 맞아 보인다. 하지만 greedy하게 고를 경우 잘 훈련된 모델에서조차 동어 반복 문제가 생길 수 있다.
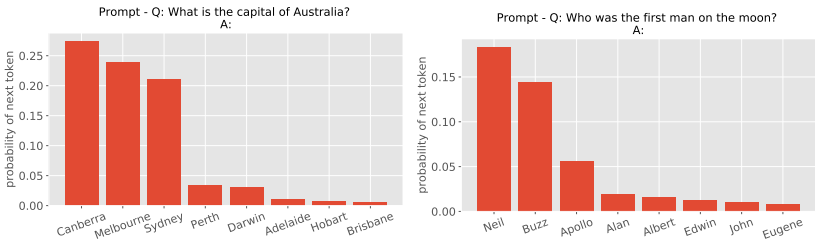
따라서 본 논문에서는 greedy에 가까운 샘플링을 통해 모델의 분포를 신뢰하면서도 기존에 생성한 토큰에 대해서는 점수에 벌점을 부여하는 방식을 제안한다. 생성된 토큰 g가 있을 때, 다음 토큰에 대한 확률은 다음과 같이 쓸 수 있다:

이 식에서 greedy sampling과 theta = 1.2 정도를 사용하면 올바른 토큰을 생성하면서 동어 반복을 피할 수 있다는 것을 실험적으로 알아내었다. 이 방법은 모델이 충분히 신뢰 가능한 분포를 생성할 때에만 유의미하다는 점에 유의해야 한다. 참고로 논문에서 학습시에는 penalized sampling을 사용하지 않고, 오로지 추론에만 사용하였다.
실험 셋팅
DATA
다양한 도메인에서 추출한 140GB의 텍스트 사용
데이터: (sub-reddit data 중간 생략)
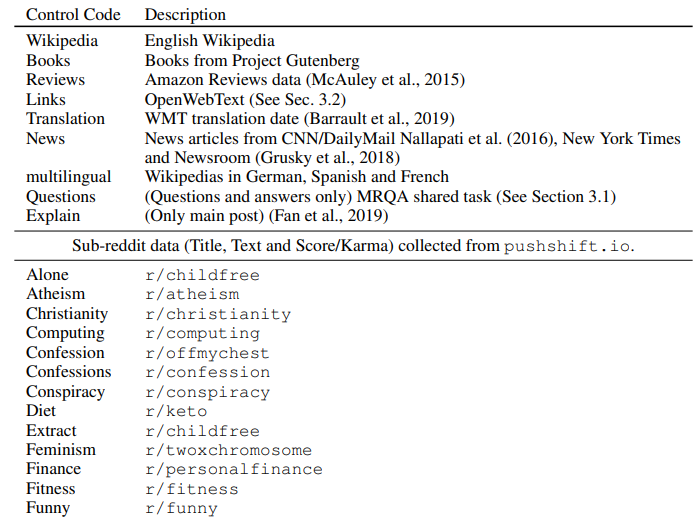
실험 셋팅
- 토크나이징 :
> 25만개 토큰에 달하는 큰 단어사전 사용
. 희귀 단어 관련 문제를 해결하기 위해 다양한 sub-word 토큰을 포함하기 위함
. 또한, 큰 단어사전을 쓰면 일반적인 단어가 많이 포함되기 때문에 긴 텍스트를 쓰기 위해 필요한 토큰 개수가 줄어듦
> 영어 위키피디아와 수집한 OpenWebText의 5% 데이터를 하용해 BPE 코드를 학습함.
> unknown 토큰을 포함시켜 전처리 과정 중 두 개 이상의 unknown을 포함한 시퀀스는 삭제함.
. 학습 데이터 용량이 줄어드는 효과
> fastBPE(https://github.com/glample/fastBPE)를 사용해 데이터를 토크나이즈
- 학습 데이터로 만들기 :
> 각 도메인에 있는 긴 시퀀스를 어떤 연속적인 토큰의 시퀀스로 자르고, 도메인 컨트롤 코드를 시퀀스의 첫 번째 코드로 붙임.
> 이로 인해 도메인 컨트롤 코드는 특별 취급 을 받게 됨.
. 도메인 컨트롤 코드는 첫 번째 토큰으로써 도메인에 있는 모든 텍스트에 전파됨.
- 모델 하이퍼파라메터
> 시퀀스 길이 256과 512로 모두 실험 : sliding-window 방법을 쓰니 좋았고, 첫 256개 토큰에 있어서는 시퀀스 길이에 따른 성능 차이 없었음.
> d = 1280, f = 8192, 48개 layer, 16개 head for multi-head attention (.........????? 48레이어...????)
> dropout = 0.1
> 토큰 임베딩과 최종 아웃풋 임베딩 레이어는 파라메터를 공유함.
- 훈련 스펙
> TPU v3 Pod의 256개 코어에서 분산학습
> batch size 1024 , 80만 iteration동안 학습
> 학습은 거의 2주가 걸림
> Adagrad 사용, linear warmup 0->0.05 (첫 25000 스텝)
> gradient clipping 0.25
Source Attribution
도메인 컨트롤 코드는 학습 데이터를 상호 배제적인 집합으로 파티션하는 데에 사용하게 된다. 언어모델은 컨트롤코드 c가 주어질 때 시퀀스의 확률 p_theta(x|c)을 학습하는 방법이다. 도메인 컨트롤 코드에 대해 prior p(c)을 정하는 것은 도메인에 대한 랭킹을 계산하는 직관적인 방법이라고 볼 수 있다.

본 연구에서는 훈련 데이터에 대한 empirical prior이 데이터 양이 많은 도메인에 지나치게 weight를 많이 준다는 것을 발견하였다. 따라서 도메인 컨트롤 코드에 대해 uniform prior을 적용하였다.

모델 훈련에 사용한 데이터는 모든 분야를 다루지 않고, 원본 데이터에 있는 문화적인 요소를 포함하고 있다. 따라서 모델을 적용한 분야에서 예측을 하더라도 내재적으로 원본 소스에 의존할 수밖에 없다.
모델은 특정 문화적 특성이 좋은지 나쁜지, 옳은지 그른지, 사실인지 아닌지에 대한 관념이 없다. 오로지 도메인과 문화적 관련성 사이에 있는 상관관계를 배울 뿐이다. 그 증거로 같은 소스에 대해 모순적인 텍스트를 생성하는 것을 볼 수 있다. CTRL은 특정 도메인은 주어진 문장에 대해 비슷한 언어를 더 많이 포함한다는 모델 기반의 증거를 제공하지만, 이를 보편적인 주장으로 내세울수는 없다.
[IN MY OPINION]
Google T5 이전에 "prefix"와 같은 느낌으로 자연어 생성에 제약 조건을 준 논문이었다. 생성 모델에서 학습 데이터에 자주 나온 어구가 해당 태스크를 수행하도록 한다는 증거는 기존에도 있었다. 예를 들어 [TL:DR] 은 "too long; didn't read"의 약자로 우리나라의 '세줄요약'와 같은 단어로 사용되는데, 이러한 소스를 포함한 텍스트를 대량학습한 GPT는 [TL:DR] 이후에는 앞에 있던 컨텍스트를 요약하는 텍스트를 생성한다는 것이 경험적으로 발견되기도 하였다.
CRTL에서는 이러한 언어 모델링적 특성을 적극적으로 활용하여 도메인에 따른 문체 특성(수록된 예문에서 뉴스와 리뷰 등은 스타일에 확연한 차이가 드러남)을 반영해 텍스트를 생성하는 시도를 하였고, 프롬프트를 이용해 원하는 요건을 모델에 입력할 수 있도록 하였다. 이때 크롤링 당시 자연스럽게 얻을 수 있는 메타정보 (도메인, URL 등)를 활용함으로써 사람의 공수를 최소화하고 비지도학습의 장점을 살렸다.
자연어 생성을 '제어'하는 모델로 할 수 있는 일은 많아보인다. 상상해보자면, 고객의 성별/ 연령에 따라 다른 어투로 답변하는 자동 응답 시스템, 페르소나를 가진 챗봇(이미 있음 ), 스타일 변환 느낌으로 평서문을 구어체로, 혹은 구어체를 평서문으로 바꾸는 모델 등 어플리케이션이 다양할 것 같다. '도메인을 특정하는 prefix를 해당 도메인에 해당하는 모든 텍스트의 시작으로 삼음으로써 그 정보가 도메인에 있는 모든 텍스트에 전파되도록 만들었다'는 CTRL 논문에서의 핵심 아이디어는 기억해 두었다가 나중에 활용하면 좋을 것 같다.
# NLU #NLG #자연어이해 #Transformer #CTRL

'AI > Algorithm&Models' 카테고리의 다른 글
| [논문리뷰] ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators (5) | 2020.05.24 |
|---|---|
| [논문리뷰] 블렌더(Blender) - Facebook AI의 오픈 도메인 챗봇 (0) | 2020.05.01 |
| AutoML-Zero: 'zero' 에서부터 스스로 진화하는 기계학습 알고리즘 (2) (1) | 2020.03.13 |
| AutoML-Zero: 'zero' 에서부터 스스로 진화하는 기계학습 알고리즘 (1) (0) | 2020.03.13 |
| Graph Convolutional Networks (GCN) 개념 / 정리 (7) | 2020.03.11 |