TensorFlow Extended (TFX)
" 전체 머신러닝 시스템을 정의하고 배포, 모니터링할 수 있는 일련의 요소를 모두 갖춘 TensorFlow 기반 머신러닝 플랫폼"
- TFX의 목표는 구글에서 머신러닝 제품을 안정적으로 할 수 있는 플랫폼을 만드는 것이었음
- 따라서 TFX는 구글 프로덕트 수준의 scalability가 확보된 라이브러리라고 할 수 있음 (scalable production scale)
- 구글의 software engineering + ML development 기술이 집약된 플랫폼
TFX 파이프라인
일련의 기계학습 태스크를 수행하기 위해서는 모델 정의부터 프로덕션 레벨의 문제까지 복잡한 문제들을 고려해야 함.
- 데이터 준비 과정에서는
> 준비된 데이터의 통계량을 검진, 이상치/ 결측값 제거 등 데이터 클리닝 등 데이터에 대한 정밀한 관찰이 필요함.
> 기계학습에 적합한 형태로 feature engineering 작업 수행
- 모델 학습 과정에서는
> 하이퍼-파라미터 튜닝
> overfitting 방지를 위한 검증 데이터 모니터링, 모델 최적화 수행
- 배포 단계에서는
> scalable한 추론 환경 구성
> 모델 optimization을 지속해야 하고, 데이터 변화가 감지될 시 모델 수정 등 지속적인 유지/ 보수 필요
이와 같이 전체 프로세스에서는 신경 써야 할 것이 너무나 많음
TFX 파이프라인에서는 스케일러블하고 성능이 좋은 기계학습 태스크 수행을 위해 데이터 인풋부터 시작해서 모델 검증, 스키마 생성 등 일련의 작업을 파이프라인화 함. 뿐만 아니라 모델이 추론 반복적으로 수행할 수 있고, 지속 가능할 것임을 확인하기 위해 테스트를 진행하는 것도 파이프라인에 포함되어 있음.
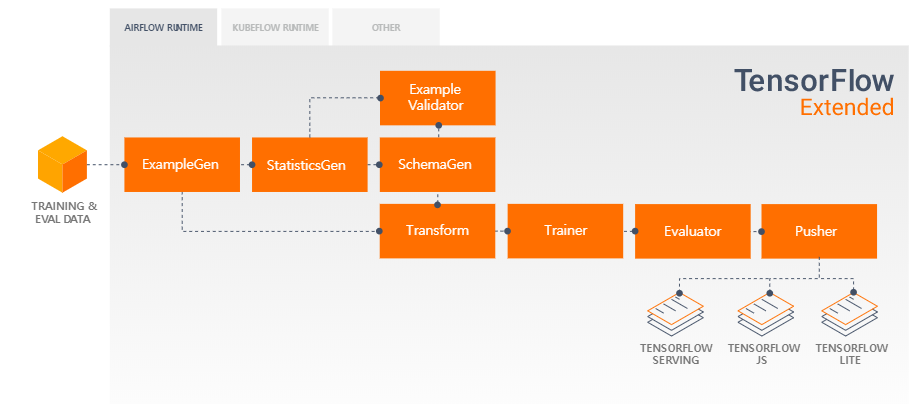
- ExampleGen: 파이프라인의 인풋 컴포넌트고, 인풋 데이터를 받아들이고 필요에 따라 쪼갬
- StatisticsGen: 데이터에 대한 통계 정보 계산
- SchemaGen: 데이터 통계를 자세히 조사하여 데이터 스키마를 생성함
- ExampleValidator: 데이터셋에 있는 이상 포인트나 결측치 등을 확인함
- Transform: 데이터에 대한 feature engineering 작업을 수행
- Trainer: 모델 훈련
- Evaluator: 훈련 결과에 대한 심도있는 분석을 통해 최종 모델이 프로덕션 레벨로 사용할 만큼 좋을 것을 검증
- Pusher: 모델을 서버 인프라에 디플로이함
주요 업데이트
2019년
- ML Metadata를 만들고
- TF2.0을 지원하고(기존에는 estimator 기반 기능만 지원)
- Fairness 지표와 TFMA(TensorFlow Model Analysis)를 제공하기 시작함
2020년에는...
- Naive Keras + TF2.0 : Keras를 TFX에서 사용할 수 있음
- TFLite in TFX : TFLite 활용이 가능해짐
- Warm starting : 모델 캐싱을 통해 머신러닝 훈련에 걸리는 시간 단축
- Cloud Google AI Pipeline 론칭!!!
Cloud Google AI Pipelines
구글 AI 플랫폼들과 TFX를 결합한 클라우드 AI 파이프라인 (베타 버전)

목표
- 강건하며 지속적인 기계학습 파이프라인을 디플로이하여 이에 대해 모니터링, 버전 트레킹, 재배포까지 가능하게 함
특징
- 기업에서 바로 활용 가능 (enterprise-ready)
> 파이프라인 버전 관리, 메타데이터 자동 트래킹, 클라우드 로깅, 시각화 등의 기능 제공
> 구글 클라우드 서비스(BigQuery, Dataflow, AI Platform Training ans Serving) 등과 연동되어 있음
- 편의성
> 설치는 Google Cloud Console에서 버튼 클릭으로 가능
> 모델 관리 및 사용이 편리함 : AI Platform Pipeline은 구글 쿠버네티스 엔진(Google Kubernetes Engine, GKE) 위에서 작동하며, 이는 파이프라인 설치 시 자동으로 클러스터를 생성함. (원한다면 이미 존재하는 GKE 클러스터를 사용할 수도 있음)
> 자체적으로 제공하는 UI에서 모든 클러스터를 관리하고, 파이프라인 버전 관리도 가능함.
- 기계학습 워크플로우에 대해 보안이 되어 있는 환경을 제공함
기술 스택
- Kubeflow Pipeline(KFP) SDK를 사용하거나, TFX SDK를 이용해 TFX 파이프라인을 커스터마이즈해 사용
- SDK는 파이프라인을 컴파일하여 Pipelines REST API로 던져주는 역할 수행
- 여기서 REST API에서는 기능 실행을 위해 파이프라인을 저장하고, 스케줄링하는 역할을 수행
- 파이프라인에 있는 구성 요소들은 GKE 클러스트 안에 있는 개별적인 포드(pod)에서 실행되고, 이에 따라 파이프라인 안에 있는 컴포넌트들이 쿠버네티스만의 경험을 제공할 수 있게 됨.
- 뿐만 아니라 구성요소들은 Dataflow, AI Platform Training, Prediction, BigQuery와 같은 구글 클라우드 서비스를 활용하여 스케일러블한 연산과 데이터 처리가 가능
- 또한, GKE의 자동 스케일링(autoscaling)과 노드 자동 할당을 통해 클러스터 내에서 GPU와 TPU 연산을 유연하게 활용

KubeFlow Pipelines
"머신러닝 워크플로우를 쿠버네티스 상에서 쉽고, 스케일러블하게 디플로이할 수 있도록 하는 기능"
하나의 E2E 머신러닝 서비스는 all-in-one 모델 하나로 이루어져 있기보다는 태스크 수행을 위해 각각의 작은 역할을 하는 일련의 구성 요소들로 이루어져 있다. 예를 들어 "챗봇"이라는 하나의 시스템은 사용자 발화가 들어오면 의도 분류 - 슬롯 필링 - DB 조회 - 발화 생성 등 "사용자의 입력을 받아 답변을 생성하기까지" 필요한 구성요소들이 조각조각 나뉘어져 있다.
따라서 이러한 머신러닝 워크플로우에서는
- 특정 시간대 특정 컴포넌트에 요청이 급증했을 때 유연하게 연산량 증가
- 시스템 개선을 위해 컴포넌트 유지 / 보수 (모델 교체 등)
등 전체 시스템을 관리할 수 있는 툴이 필요하고, 이와 같은 머신러닝 파이프라인 오케스트레이션을 단순화할 수 있는 툴이 KubeFlow Pipeline이다.
KubeFlow 파이프라인의 중요 장점은 크게 다음 두 가지이다:
1. 다양한 아이디어를 실험/ 관리
: 수많은 기술, 아이디어를 실험하고 그들을 관리할 수 있음
2. 파이프라인 컴포넌트 중 필요한 부분을 쉽게 재사용하여 E2E 솔루션을 빠르게 생성할 수 있도록 함
: 컴포넌트 유지/ 보수 시 필요한 부분은 재사용하여 파이프라인 버전 관리를 하고, 이에 따라 버전 업을 할 때마다 처음부터 워크플로우를 다시 짜야하는 공수를 없앰
KubeFlow Pipeline platform은 다음의 구성 요소 포함한다 :
> UI : 실험, job, run을 관리하고 트레킹
> 스케쥴링 엔징 : 멀티-스탭 머신러닝 워크플로우를 스케쥴링
> SDK : 파이프라인과 구성요소를 정의하고 조작함
> 노트북 : SDK를 사용해 시스템과 상호작용
참고로 KuberFlow(KFP) SDK와 TFX SDK는 커스터마이징 범위에 차이점이 있어 현재는 투 트랙으로 기능을 지원하고 있음.
- KFPSDK
> 쿠버네티스 자원 컨트롤과 컨테이너화 된 컴포넌트 간의 공유 등에 접근할 수 있는 lower-level의 SDK
> 이는 완전히 custom화 된 파이프라인으로, ML 프레임워크에 한정되지만은 않은 기능
- TFX SDK
> 머신러닝 워크로드를 위해 디자인된 것
> higher-level의 기능을 제공하면서도 데이터 전처리와 훈련을 커스터마이징이 가능한, 스케일러블한 머신러닝 파이프라인
지금은 이렇게 투 트랙으로 가지만, 나중에는 TFX SDK에서 프레임워크에 대해 중립적인 기능들을 지원함으로써(현재는 KFP를 써야만 frame-agnostic 기능 사용 가능) 합쳐질 것이라고 함.
결국, 데이터 입력부터 모델 훈련 ~ 디플로이까지 기계학습의 복잡한 파이프라인을 간편하게 관리하고, 스케일러블한 디플로이 환경까지 제공하는 것이 TFX. 게다가 이를 Cloud Google AI Pipeline에 도입하며 가상화된 환경에서 파이프라인 관리를 간편하고면서도 효율적으로 할 수 있게 되었다.
이번 TensorFlow Dev Summit에서 구글은 TFX 활용의 성공 사례로 Airbus의 국제 우주 승강장(International Space Station, ISS) 이상 감지 시스템을 소개하였다. Airbus의 ISS 중 하나인 콜럼버스 모듈은 2008년에 발사된 이후 우주에서의 생물학, 화학, 의학에 대한 연구를 진행하고 있다. 이 모듈은 초당 15000~20000건에 달하는 데이터를 생성하고 있고, 이러한 속도로 10년간 쌓인 데이터는 셀 수 없을 만큼 많다.
Airbus에서는 콜롬버스 모듈의 실시간 센서 데이터를 분석하여 이상 증상을 감지하는 시스템에 TFX를 활용하고 있다. 우주에서 사고가 발생하기 전에 이를 감지하고, 유지 보수를 계획하는 predictive maintanance를 위함이다.

간단하게 이상감지 시스템을 보면...
- 우주에서는 On-demand로
> 데이터베이스가 온프로미스로 구축되어 엄청난 양의 데이터를 저장하고 있음
> Spark 클러스터를 통해 필요한 데이터를 추출하고, 공개 가능한 부분을 TFX에 전달함
> TFX는 이제 KubeFlow 위에서 모델을 훈련
: TF Transform으로 데이터를 준비하고, TF Estimator로 모델을 훈련하며 이후 TF Serving으로 모델을 디플로이
- 지상에서는 Real-time으로
> 지상의 데이터 센터에서 가동중인 NIFI 클러스터를 통해 ISS 스트리밍 데이터를 지구에 있는 스테이션에 보냄
> 이를 다시 클라우드에 업로드하면, 클라우드의 쿠버네티스 기반 커스텀 파이썬 어플리케이션에서 이상 탐지를 실행
> 모델의 예측 결과는 우주에서 on-demand로 예측된 정보와 결합하여 'representation arrow'를 생성
> 이 지표가 특정 임계치를 넘으면 이를 이상 증세로 판단하여 과거 데이터를 참고해 레포트를 작성함
> 최종적으로 이러한 레포트는 인간 전문가가 검토하여 의사결정에 활용
AirBus에서는 이러한 시스템을 도입한 결과, 비용을 44% 절감할 수 있었다. 사람은 인간의 직관이 필요한, 진짜 중요한 일에만 집중하고 단순반복 작업에 드는 공수는 기계학습 시스템을 적극 활용한 결과이다. 또한, 문제가 생길 때 분 단위 이내에서 반응할 수 있게 되었다고 한다.
관련 자료 링크 :
- https://www.tensorflow.org/tfx
- https://www.kubeflow.org/docs/pipelines/overview/pipelines-overview/
- https://cloud.google.com/blog/products/ai-machine-learning/introducing-cloud-ai-platform-pipelines
- https://www.youtube.com/watch?v=I3MjuFGmJrg&list=PLQY2H8rRoyvzuJw20FG82Lgm2SZjTdIXU&index=15&t=0s

'AI' 카테고리의 다른 글
| 토치서브(TorchServe) - 파이토치 배포를 위한 모델 서비스 프레임워크 공개 (0) | 2020.04.28 |
|---|---|
| [논문리뷰] CTRL - 자연어 생성을 위한 조건부 트랜스포머 언어 모델 (0) | 2020.04.26 |
| TensorFlow Lite - 모바일 & IoT 디바이스를 위한 딥러닝 프레임워크 (0) | 2020.03.16 |
| AutoML-Zero: 'zero' 에서부터 스스로 진화하는 기계학습 알고리즘 (2) (1) | 2020.03.13 |
| AutoML-Zero: 'zero' 에서부터 스스로 진화하는 기계학습 알고리즘 (1) (0) | 2020.03.13 |



