AutoML-Zero: Evolving Machine Learning Algorithms From Scratch

"우리의 목표는 AutoML이 한 걸음 더 나아갈 수 있음을 보여주는 것이다 -
이제는 기본적인 수학 연산을 기본 블록으로 하여 AutoML은 전체 기계학습 알고리즘을 자동으로 찾아낼 수 있다."
사람의 디자인을 최소화하고, 밑단부터 기계학습 알고리즘을 자동으로 탐색하는 방법을 제안한 논문
코드도 오픈소스로 공개해버림!!
논문 >> https://arxiv.org/pdf/2003.03384v1.pdf
코드 >> https://github.com/google-research/google-research/tree/master/automl_zero
AutoML인데, 결국 사람이 디자인한 아키텍쳐에 의존하고 있었다
지금까지의 방법론들은 전문가가 디자인한 정교한 레이어를 기본 블록으로 쓰는 등, 사람의 직관이 반드시 들어갔다.
- 이에 따라 탐색의 결과는 인간이 디자인한 것에 편향되고, AutoML의 독창적인 가능성은 억제됨
- 훨씬 적은 탐색 공간만을 살펴보기 때문에, 성능을 보일 수 있는 대부분의 탐색 공간은 고려조차 되지 않음
-그나마도 탐색 공간은 '잘' 디자인하기 위해 연구자들의 정교한 노력이 필요한 상황이었음
휴먼 디자인의 공수를 줄이기 위해 고안된 AutoML인데, 블록을 만들고 탐색 공간을 정의하느라 노력이 또 필요한 아이러니?
# 그래서 본 논문에서는...
- 기본적인 수리 연산만을 기본 블록으로 자동으로 아키텍처를 서치하는 AutoML-zero를 소개함.
- 이러한 구조의 탐색 영역은 굉장히 일반적이고 광활한데, 진화적인 탐색을 이용해 두 층의 뉴럴넷을 backprop으로 학습하는 것을 발견해 내기에 이름.
- 또한 학습된 모델은, 바로 하위 태스크에 대해 진화해 좋은 성능을 내버림!!
# AutoML-Zero란...
- 목표는 아주 잘게 분할된 공간에 대해 모델, 최적화 및 초기화 방법 등을 동시적으로 탐색하는 것이다.
- 이 때 디자인 등의 측면에서 사람의 개입을 최대한 억제한다.
- 그 결과로 아주 다양한 공간을 탐색하고, 심지어는 뉴럴넷 알고리즘이 아닌 영역까지도 발견함을 목표로 한다.
# '일반성(genericity)'에 대하여
- 이러한 특성으로 인해 AutoML-Zero는 현존하는 다른 방법론들에 비해 탐색이 매우 어렵다.
- 지금까지의 탐색 공간은 '좋은 솔루션'들이 밀집된 공간에서 탐색을 해왔다면
- AutoML-Zero는 탐색 공간이 너무나 일반적인 나머지, 그 공간은 듬성듬성하다(sparse)
본 논문에서 제안하는 프레임워크에서 기계학습 알고리즘이란 세 가지 함수 - Setup(), Predict(), Learn() 로 구성된 컴퓨터 프로그램으로, 한 번에 하나의 예제를 예측하고, 그로부터 학습한다. 이 함수들에 있는 '지시사항'은 작은 메모리 내에서 기본적인 수학 연산을 하는 것인데, 각각의 지시에서 사용한 연산과 메모리 주소는 탐색 공간에서 자유 파라메터가 된다. 이런 방법은 전문가 디자인에 대한 의존성을 줄이지만, 탐색의 공간은 너무나 sparse한 나머지 랜덤 서치와 같은 방법은 엄두조차 낼 수가 없다. (랜덤 서치로 아주 사소한 태스크에 대해 좋은 알고리즘을 학습할 확률은 1조 분의 1 정도)
이렇게 일반적인 공간을 탐색하는 데에 수많은 시도가 필요하기 때문에...
1) 작은 태스크를 프록시 태스크로 사용하고
2) cpu에서 1초에 1만 개의 모델을 탐색할 수 있는 최적화된 오픈소스 인프라를 구축한다.
3) 적용할 함수가 동일한 것이 있는지 체크하여 이미 본 알고리즘은 다시 평가하는 일이 없도록 하여 속도를 4배 향상했다.
# 진화 탐색 방법은 효과적이었다
AutoML-Zero 방법이 살펴봐야 할 공간이 방대하고 드문드문함에도 불구하고, 진화 탐색은 솔루션에 도달하였다.
프로그램을 랜덤하게 수정하고, 주기적으로 최고 성능을 내고 있는 것들을 선택함으로써 괜찮은 알고리즘을 찾을 수 있었다.
# 논문 실험 미리 보기
1. 인공 실험에서 진화 방법론은 backprogagation 하는 방법을 발명해냈다..!
2. CIFAR-10 태스크에서 추출한 2개 클래스 분류 문제에서 사람이 디자인한 뉴럴넷보다 논문의 진화 알고리즘의 성능이 더 좋았고, 곱셈 간섭이나 그라디언트 정규화, 웨이트 평균과 같은 흥미로운 연산을 발견해냈다.
방법론 개요
AutoML-Zero는 태스크의 집합 T가 주어질 때 좋은 성능을 내는 알고리즘을 자동으로 찾는 것이 목표이다.
즉, 어떤 알고리즘의 공간 A로부터 최적이면서도 일반화할 수 있는 a*를 찾는 것이 탐색 실험의 목적.
탐색은 다음과 같이 이루어진다 :
1. 실험을 통해 어떤 알고리즘에 대해 태스크 집합의 부분집합 T_search에 대해 성능을 측정함
2. 이 중 성능이 좋은 후보 알고리즘들을 뽑아냄
3. 이제 태스크의 다른 부분집합 T_select에 대해 각 후보의 성능을 체크 (validation 하는 것처럼..!)
논문에서는 주로 CIFAR-10 데이터에서 2개 클래스를 샘플링하여 사용한다. CIFAR-10 데이터는 원래 3072차원의 데이터이지만, 계산 비용을 줄이고 처리율을 높이기 위해 이를 랜덤하게 8~256차원으로 축소해 만든 프록시 태스크에 대해 탐색하였다.
탐색의 결과 가장 좋게 나온 알고리즘의 성능을 CIFAR-10 데이터에 대해 사람이 디자인한 베이스라인 모델과 비교한다. 이때에는 원래의 차원을 그래도 사용하였고, 훈련에 전혀 사용하지 않은 테스트 데이터에 대해 비교한다. 또한, 실험의 결과가 CIFAR-10에 국한되는 것이 아니라는 것을 보이기 위해 SVHN, ImageNet, Fashion MNIST 데이터에 대해서도 실험을 하였다.

Search Space
# 알고리즘, 프로그램, 지시(instruction)에 대한 개념
- 알고리즘은, 스칼라/ 벡터/ 행렬에 대해 별도의 주소 공간을 가지는 작은 가상 메모리로 작동하는 컴퓨터 프로그램
- 메모리 공간은 부동소수점을 처리하고, 태스크의 인풋 feature에 대해 차원을 공유함
- 프로그램은 '지시'의 시퀀스,
> 각각의 지시는 그의 함수를 결정하는 하나의 연산을 가짐 (예. 벡터에 스칼라 곱하기)
> 기계학습에 대한 알려진 개념을 배제하기 위해 행렬 분해나 도함수 등의 개념은 연산에서 배제함
> 지시들은 또한 연산에 특화된 인자를 가지는데, 이들은 메모리를 표현하기 위해 사용됨
(스칼라 주소 0으로부터 인풋을 읽어라, 벡터 주소 2에 아웃풋을 저장해라 등등)
> 어떤 연산은 실수인 상수가 필요하고, 이들도 탐색의 대상이 됨 (정규분포로부터 샘플링하는 연산을 위한 mu, sigma 등)
> 65가지 연산에 대한 full list는 논문 참고
# 알고리즘 상세
- 알고리즘은 다음의 세 가지 구성 함수들(component functions)으로 이루어진 프로그램으로 표현됨
: Setup , Predict , Learn
- 전체 알고리즘은 훈련 단계와 평가 단계로 구성되는데,
각 단계에서는 간결성을 위해 한 번에 하나의 데이터 샘플만 활용하여 for 루프를 돌아감
훈련 단계
- Predict와 Learn을 번갈아가며 수행
- Predict는 예제의 feature (x 등)만을 보게 되고, 그에 대한 라벨은 Learn 단계에서만 볼 수 있음
- Predict를 수행되고 나면, 스칼라 주소 1에 있는 값이 무엇이든 그것은 예측 결과로 간주함.
이에 따라 Predict 연산은 이 주소에 무엇이든 쓸 수 있지만, -무한대~무한대의 값을 가지는 이 값은
Sigmoid(binary) 혹은 Softmax(multi class) 연산을 통해 0~1 사이의 확률 값으로 정규화됨.
이 과정은 s1 = Normalize(s1)이라는 지시에 의해 수행됨

평가 단계
- 평가셋에 대해 Predict 연산을 수행함.

전체 알고리즘에서 가상 메모리는 지속성이 있고 모든 단계에 있어 공유되는데, 이로 인해 초기에 메모리를 초기화해야 함.
아래의 전체 알고리즘을 나타낸 아래의 그림을 보면
1. Setup으로 메모리 변수(weight 등)를 초기화
2. Learn은 그를 훈련 과정에서 그를 조절
3. Predict는 이 메모리를 활용한다는 것을 알 수 있음
이런 과정을 통해 각각의 태스크에 대해 정확도를 산출해 낼 수 있고, 알고리즘은 평균 loss로 측정되는 정확도를 리턴하여 탐색 방법(search method)에서 알고리즘의 질을 평가하는 데에 사용함
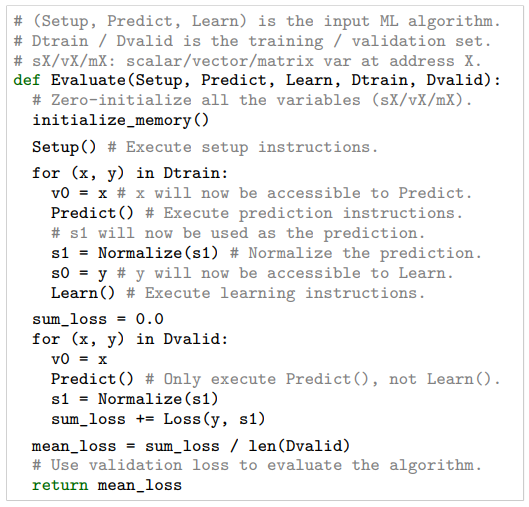
Search Method
탐색 실험에서는 구성 함수(Setup, Predict, Learn) 안에 있는 지시들을 수정해 감으로써 알고리즘을 찾아내야 한다.
논문에서는 regularized evolution search 방법을 주로 사용하는데, 이 방법은 간단하면서도 성공적이라는 것이 연구된 바 있다.
# regularized evolution search
이 방법은 P라는 모수 알고리즘을 유지하며 진행되는데, 시작점에서는 이 모집단이 빈 채로 시작한다
(알고리즘 그림을 보면 구성 함수에 어떠한 지시나 코드가 들어있지 않음 )

이제 사이클을 돌며 이 모집단이 개선되게 되는데, 그 과정은 네 가지 단계로 이루어져 있다
Step 1. 모수 집단에서 가장 오래된 알고리즘을 제거한다
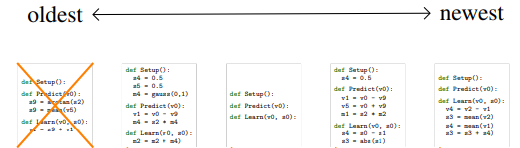
Step 2. 랜덤하게 P보다 적은 T개의 알고리즘을 선택하여 가장 좋은 성능을 가진 알고리즘을 부모(parent)로 삼는다.
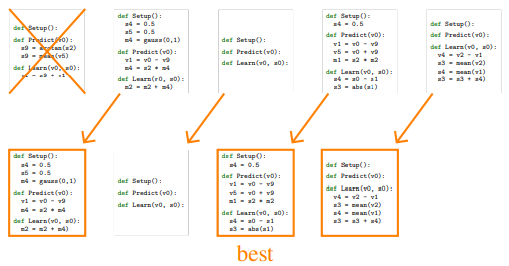
Step 3. 선택된 알고리즘을 복사한다 (똑똑한 부모에게 똑똑항 아이가 태어나는 느낌..?)

Step 4. 부모 알고리즘은 변이 되어 자식(child) 알고리즘이 되고, 이 알고리즘이 모수에 더해진다.

* 위의 네 그림은 AutoML 논문의 Figure 2 캡쳐 (The source of above figures is AutoML-Zero arxiv paper, Figure 2)
여기서 자식 알고리즘도 탐색 공간에 적합해야 하기 때문에, 변이(mutation)는 다음의 세 가지 액션 중 하나로 이루어진다:
(a) 구성 함수 중 하나에 대해 랜덤한 위치에 랜덤한 지시를 넣거나 지시를 랜덤하게 삭제함

(b) 구성 함수 중 하나에 대해 모든 지시를 랜덤화함

(c) 지시의 argument 중 하나를 랜덤하게 바꿈 (아웃풋 주소를 바꿔라, 상수를 바꿔라 등등...)

* 위의 세 그림은 AutoML 논문의 Figure 3 캡쳐 (The source of above figures is AutoML-Zero arxiv paper, Figure 3)
# 처리율 향상을 위한 트릭
하나의 cpu에서 1초에 2000~1만 개의 알고리즘을 처리하기 위해 프록시 태스크 도입 이외에 다음의 두 가지 트릭 사용:
1) functional equivalence checking(FEC) -> 속도 4배 향상
- 다르게 구성되었더라도 동일하게 작동하는 알고리즘을 찾아내 방지함
- 이를 수행하기 위해 고정된 샘플에 대해 10번의 훈련과 10번의 평가 스텝을 거친 예측 결과를 저장해 두고, 결과를 fingerprint로 해시해 놓아서 불필요한 평가를 반복할 필요가 없도록 막음
2) 허들을 추가-> 처리율 5배 향상
- worker에 대해 분산 실험을 수행하고, migration을 통해 모델을 교환할 수 있도록 함
정리하자면...
- {Setup, Predict, Learn} 이라는 세 개의 함수로 프로그램을 구성
- 각각의 함수는 65가지 기본적인 수학 연산을 조합하여 채워넣음. How?
- 랜덤 서치는 ㄴㄴ 진화 탐색 (evolution search)을 사용
- 왜냐하면 알고리즘을 구성하는 모든 것 (연산의 선택, 메모리 주소 할당, argument 설정 등)이 랜덤하게 결정될 수 있고, AutoML-Zero가 탐색해야 하는 탐색 공간은 굉장히 방대하며 sparse 하여 랜덤서치로는 엄두도 낼 수 없기 때문
- 뿐만 아니라 데이터 처리율을 높이기 위해 프록시 태스크, 함수 일치성 평가, 허들 등의 트릭을 활용함
- 그 결과, 밑바닥부터 진화한 알고리즘은 목표 태스크에 대해 좋은 성능을 낼 뿐만 아니라, 흥미로운 연산들을 발명해 냈음
- 실험 결과 정리는 (2) 편에 계속...

'AI > Algorithm&Models' 카테고리의 다른 글
| [논문리뷰] CTRL - 자연어 생성을 위한 조건부 트랜스포머 언어 모델 (0) | 2020.04.26 |
|---|---|
| AutoML-Zero: 'zero' 에서부터 스스로 진화하는 기계학습 알고리즘 (2) (1) | 2020.03.13 |
| Graph Convolutional Networks (GCN) 개념 / 정리 (7) | 2020.03.11 |
| Graph Neural Networks (GNN) / 그래프 뉴럴 네트워크 기초 개념 정리 (2) | 2020.03.10 |
| Explainable AI : 설명 가능한 인공지능 / XAI / DARPA / Google XAI / What-if 툴 (0) | 2020.02.23 |