Hugging face에서 정리한 자연어 생성 디코딩 전략 포스팅을 번역 & 정리한 포스트입니다
❤️ Source - hugging face ❤️
더 좋은 디코딩 전략으로 자연어 생성 모델의 성능 높이기
포스팅에서 소개하는 전략은 아래와 같이 표현할 수 있는 모든 auto-regressive 언어 모델에 적용 가능하다. 또한, 다섯 가지 디코딩 전략은 hugging face의 transformer 라이브러리에서 함수로 호출해 사용할 수 있다.

import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# EOS토큰을 PAD토큰으로 지정하여 warning이 나오지 않게 함 warnings
model = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)1. Greedy Search
: 타임스텝 t에서 가장 높은 확률을 가지는 토큰을 다음 토큰으로 선택하는 전략
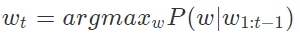
- Greedy Search 전략은 직관적이며, 짧은 텍스트를 생성할 때 괜찮은 전략이다.
- 이 전략을 통해 생성한 문장은 그럴듯하지만, 모델은 어느 순간 (꽤 빠른 시점부터) 같은 단어를 생성하기 시작한다.
- 이러한 동어 반복 문제는 자연어 생성에서 자주 발생하는 문제이지만, greedy & beam search에서 특히 자주 발생한다.
- 또한, 매 스텝에서 최고 확률의 토큰을 선택하는 이 전략은 최종 문장의 관점에서 최적이 아닐 수 있다.
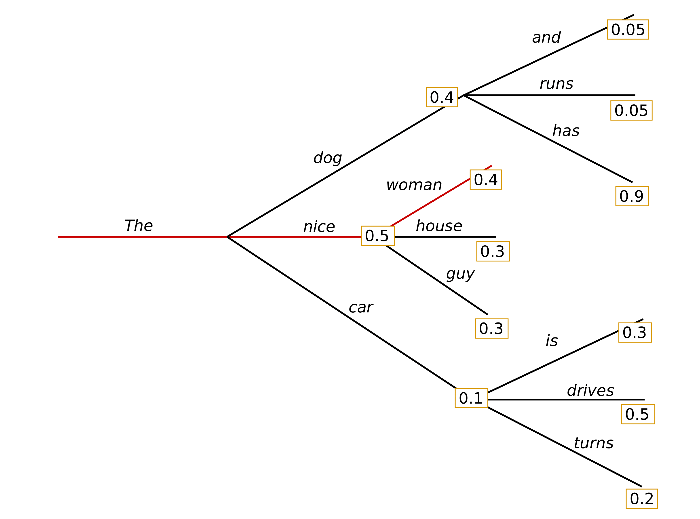
예를 들어 모델이 위와 같이 단어를 디코딩할 수 있었다고 하면, Greedy 전략에서는 매 시점 가장 높은 확률 값을 가지는 nice(p=0.5) -> woman(p=0.4)을 선택하게 되고, 이 문장의 최종 확률은 0.5*0.4 = 0.2가 된다. 하지만, nice(p=0.5) 토큰에 가려져 선택하지 못했던 dog(p=0.4)에 잇따르는 토큰은 has(p=0.9)로, 이 트랙을 따랐다면 더 좋은 토큰을 선택할 수 있었을 것이다.
<GPT-2 Greedy Search로 디코딩하기>
# 생성할 텍스트에 대한 시작 문구를 지정
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
# 디코딩 최대 길이(50글자)까지 model.generate를 통해 디코딩 진행
greedy_output = model.generate(input_ids, max_length=50)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))
2. Beam Search
: 각 타임스텝에서 가장 가능성 있는 num_beams개의 시퀀스를 유지하고, 최종적으로 가장 확률이 높은 가설을 선택하는 방법
- Greedy search가 숨겨 있는 높은 확률의 토큰을 놓칠 수 있다는 단점을 보완하기 위해 고안된 방법
- 언제나 Greedy search보다 높은 확률의 시퀀스를 찾게 되지만, 여전히 최선의 아웃풋을 보장하지는 않는다.

위의 그림은 num_beams=2로 디코딩할 때의 예시를 보여준다. 첫 번째 타임 스텝에서는 가장 높은 확률을 가지는 [The, nice (p=0.5)]와 [The, dog (p=0.4)] 두 개의 시퀀스를 유지한다. 두 번째 타임 스텝에서는 [The, nice, woman(p=0.20)]과 [The, dog, has(p=0.36)] 두 개의 시퀀스가 선택되고, greedy decoding과는 달리 더 확률이 높은 (The, dog, has)의 시퀀스를 선택하게 된다.
<GPT-2 Beam Search로 디코딩하기>
# Beam-search를 적용하고 EOS가 나오면 생성을 멈춤
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5, #1보다 큰 값을 지정
early_stopping=True #EOS토큰이 나오면 생성을 중단
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
2-1) n-gram 패널티 주기
- 동어 반복을 피하고 좀더 자연스러운 문장을 생성하기 위해 n-grams 페널티 전략을 적용할 수 있다.
- n-gram 단위의 어구가 두 번 등장할 일이 없도록, 이러한 일이 발생할 확률을 0으로 만드는 전략이다.
- 코드상에서는 아래와 같이 no_repeat_ngram_size 옵션을 설정함으로써 구현할 수 있다.
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2, # 2-gram의 어구가 반복되지 않도록 설정함
early_stopping=True
)
- 이 전략을 이용하면 훨씬 자연스러운 문장을 생성할 수 있지만, 텍스트 전체에서 n-gram으로 설정한 단어가 한 번만 등장할 수 있기 때문에 주의해서 사용해야 한다. 예를 들어 '서울 시청'에 대한 주제로 글을 쓰는데, no_repeat_ngram_size = 2로 설정하면 전체 글에서 '서울 시청'이라는 말은 한 번밖에 사용하지 못하기 때문이다!
2-2) beam search에서 k개의 beam을 모두 리턴하기
: beam을 유지하며 디코딩한 시퀀스 중 가장 높은 확률을 가지는 k의 시퀀스를 모두 리턴해 마음에 드는 것을 사용하는 전략
- 코드에서는 num_return_sequences 옵션을 통해 구현 가능. 이 때 이 값은 num_beams보다 작거나 같아야 한다.
beam_outputs = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5, # 다섯 개의 문장을 리턴
early_stopping=True
)
하지만, 모델이 자유롭게 글을 생성하는 <open-ended 생성>에서는 beam search가 최선의 전략은 아닐 수 있다:
- beam search는 기계번역이나 요약정도에는 잘 작동하지만, 생성해야 하는 텍스트의 길이가 긴 대화 혹은 스토리를 생성해야 하는 open-ended 생성에서는 좋지 않다는 연구 결과가 있다.
- beam search는 동어반복 문제가 심한 편인데, n-gram 페널티 전략으로는 '반복 없음'과 '적절한 시점에 동일한 단어를 재사용'하는 중간 지점을 찾기 어렵다.
- 인간이 사용하는 언어를 놓고 보면, 모델이 생각하기에 가장 높은 확률을 가지는 단어가 늘 다음에 오는 것은 아니다. 마치 사람이 쓴 것과 같이 자연스럽기 위해서는 너무 예측 가능한 나머지 뻔하지만은 않은, '놀라운' 단어를 생성해낼 필요도 있다.
그래서, 모델이 지루한 말만 하지는 않도록 random성을 넣을 필요가 있다🤪
3. Sampling
: 모델이 생각하는 다음에 올 토큰에 대한 확률분포에 따라 단어를 샘플링하는 방식으로 디코딩하는 전략

- 이 전략을 사용하면 각 타임스텝에서 모델이 예측한 토큰의 확률분포를 이용해 토큰을 샘플링해 문장을 완성한다.

tf.random.set_seed(0) # reproductibility를 위해 랜덤 시드 고정
sample_output = model.generate(
input_ids,
do_sample=True, # 샘플링 사용
max_length=50,
top_k=0 #top_k=0으로 설정하면 타임스텝별로 하나의 토큰만 샘플링
)- 하지만 모델이 만들어낸 확률은 smooth한 나머지, 낮은 확률의 토큰이 "지나치게 잘" 샘플링될 수 있고, 이렇게 되면 어색한 문장이 만들어질 수 있다.
- 따라서 모델이 배출한 분포에서 높은 값을 가지는 확률을 더 뾰족하게 만드는 temperature 스케일링을 사용한다.
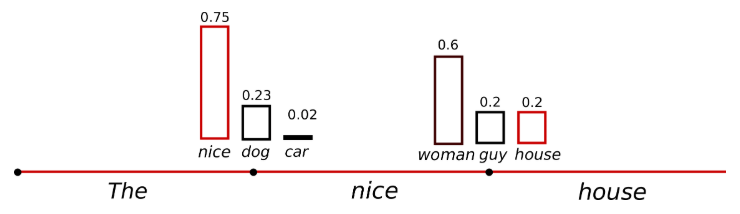
- 코드에서는 temperature 옵션을 조절하여 확률의 sharpness를 조절할 수 있고, temperature이 0에 가까워질수록 greedy decoding에 가까운 아웃풋이 나온다.
4. Top-k Sampling (논문)
: 가장 확률이 높은 K개의 '다음 단어들'을 필터링하고, 확률 질량을 해당 K개의 '다음 단어들'에 대해 재분배하는 전략
- 이는 GPT-2에서 선택한 디코딩 전략으로, 스토리 생성에서 큰 효과를 보인 방법이다.
- 예를 들어 아래 그림은 K=6으로 셋팅한 top-k샘플링을 보여준다. 각 샘플링 스텝에서 샘플링할 풀이 6개로 제한된다. 이때 6개의 가장 확률이 높은 단어 집합을 V_{top-K}로 표현하면, 첫 번째 타임스텝에서는 전체 확률에서 0.68정도에 해당하는 단어에서 디코딩하지만, 두 번째 타임스텝에서는 가능한 대부분의 토큰(0.99)을 아우르는 동시에, 너무 이상한 토큰들(a, not, the 등..)은 아예 제외할 수 있다.

- 코드상에서는 top_k 옵션을 0이 아닌 50과 같은 숫자로 주어 top-k 샘플링을 쉽게 구현할 수 있다.
- 단, 이 방법은 다음 토큰으로 필터링된 k의 단어를 아주 효과적으로 활용하지 못 할 수 있다는 우려가 있다. 그림에서 보여주는 예시만 보아도, 첫 번째 단어는 꽤나 평평한 분포에서 샘플링을 하지만 두 번째 토큰은 sharp한 분포에서 샘플링을 하게 된다. 이로 인해 첫 번째 타임스텝에서는 꽤나 괜찮아보이는 (people, big, house, cat) 등의 후보는 전혀 고려되지 못하고, 두 번째 타임스텝에서는 낮은 확률이라도 뽑게 되면 어색해지는 (down, a) 등의 토큰이 샘플링 풀에 포함되게 된다. 즉, 이 방법은 모델의 창의성을 지나치게 저하하면서도 모델이 이상한 단어를 샘플링할 위험이 있는 것이다.
5. 그래서 끝판왕(?), Top-p (nucleus) sampling
: 가능도 있는 k개의 단어로부터 샘플링하는 대신, 누적 확률이 확률 p에 다다르는 최소한의 단어 집합으로부터 샘플링
- 가장 높은 확률을 가지는 토큰부터 시작해, 확률 값의 합이 top-p로 설정한 값을 넘을 때까지 샘플링 풀에 토큰을 추가한다.
- 백문이 불여일견! p=0.92로 설정했을 때의 디코딩 스텝을 그림으로 확인하자.

- 확률이 비교적 평평했던 첫 번째 타임스텝에서는 가능성 있는 (nice, dog, ..., big, house)까지 총 9개의 토큰을 샘플링 풀에 넣어야 누적확률 0.94를 채울 수 있었다. 하지만 분포가 가팔랐던 두 번째 타임스텝에서는 확률이 굉장히 높은 (drives, is, turns)에서만 샘플링하게 되고, 이상한 토큰을 샘플링할 확률이 훨씬 적어진다.
- 코드에서는 top_p 값을 0과 1 사이의 값으로 설정하면 된다.
<GPT-2 Nucleus Sampling으로 디코딩하기>
tf.random.set_seed(0)
# deactivate top_k sampling and sample only from 92% most likely words
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92, #92%로 설정하고 샘플링하기
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))- 이론상으로는 top-p 샘플링이 더 좋아보이지만, top-k와 top-p 샘플링 전략 모두 실제로 잘 작동한다.
- 또한, 두 전략을 섞어서 사용하면, 너무 낮게 랭킹된 토큰을 사용하는 것은 피하면서도 꽤나 다양한 시퀀스를 생성할 수 있다.
<포스팅에서 소개한 모든 전략을 섞어서 사용해보면...>
sample_outputs = model.generate(
input_ids,
do_sample=True, #샘플링 전략 사용
max_length=50, # 최대 디코딩 길이는 50
top_k=50, # 확률 순위가 50위 밖인 토큰은 샘플링에서 제외
top_p=0.95, # 누적 확률이 95%인 후보집합에서만 생성
num_return_sequences=3 #3개의 결과를 디코딩해낸다
)결론
Huggingface... 고마워요 ❤️
허깅페이스 says ...
- open-ended 생성에서는 top-k 확은 top-p 디코딩이 greedy 혹은 beam search보다 좋은 전략일 수 있다.
- 하지만 안타깝게도 top-k / top-p 샘플링 전략도 동어 반복 문제는 있다. (논문)
- 게다가, 모델의 훈련 목적 함수를 잘 조절하면 beam-search가 더 유창한 텍스트를 생성한다는 연구도 있다. (논문)
- 이는 open-ended 생성이 최근 빠르게 발전하는 연구분야인만큼, 어떤 하나의 전략이 "무조건 좋다"라고 말하기 어렵기 때문.
- 포스팅에서 소개한 다양한 방법을 실험해보며 사용자의 태스크에 적합한 전략을 선택하는 것이 중요하다.

'AI > Algorithm&Models' 카테고리의 다른 글
| [논문리뷰] TaBERT: 텍스트 & 표 데이터 인식을 위한 사전학습 (0) | 2020.07.27 |
|---|---|
| [논문리뷰] Longformer: The Long-Document Transformer (3) | 2020.07.21 |
| GPT-3, 이런 것도 된다고? (0) | 2020.07.20 |
| [논문리뷰] GPT3 - Language Models are Few-Shot Learners (9) | 2020.06.22 |
| 한국어 자연어 처리 데이터셋 목록 (9) | 2020.05.24 |