** 작년에 공개된 구글 리서치 논문입니다 **
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (A.K.A) Vision Transformer
개요
비전 AI도 CNN없이 풀 수 있다!
Transformer만을 사용하여 이미지 분류 태스크 수행하기
- 이미지는 이미지 조각의 시퀀스로 처리함
- 대량의 데이터에 대해 사전 학습한 후 작은 이미지 인식 벤치마크(이미지넷, CIFAR-100, VTAB)에 적용
- 그 결과 Vision Transformer(ViT)은 여타의 SOTA CNN 기반의 모델과 비교했을 때 훌륭한 성능을 얻음.
- 동시에 학습 과정에서의 계산 자원은 훨씬 적게 소모함
[ Transformer의 계산 효율성과 scalability를 비전에 활용하자 ]
본 논문에서는 표준 Transformer을 최대한 변형 없이 직접적으로 이미지에 적용하였다. 이를 위해 이미지를 패치 조각으로 쪼갠다. 그리고 각각의 패치에 대해 선형적인 임베딩의 시퀀스를 제공하여 Transformer에 입력하였다. 이때 이미지 패치는 마치 NLP에서의 토큰과 같이 다루게 된다. 모델은 이미지 분류 태스크에 대해 지도 학습 방식으로 학습하였다.
ImageNet과 같은 중간 크기의 데이터셋에 이 모델을 적용해본 결과, 같은 크기의 ResNet 모델의 정확도보다 몇 퍼센트 정도 낮은 정확도를 얻었다. 이 결과는 기대에 미치지 못한 결과처럼 보인다: Transformer는 CNN 계열의 모델은 모델링할 수 있는 지역성과 입-출력 위치의 동일성 (translation equivariance) 등 이미지 이해에 필수적인 바이어스(inductive bias)를 학습하지 못하고, 따라서 데이터가 충분하지 못할 때 일반화 성능이 떨어지는 것은 아닐까?
하지만, 모델을 더 많은 데이터셋(1400만-3억개의 이미지)에 대해 학습했을 때는 다른 결과가 나왔다. 대량의 이미지로 학습하는 것이 CNN이 학습하는 바이어스의 힘보다 강했다. 충분히 큰 스케일에서 ViT를 사전 학습한 결과, 더 적은 데이터셋을 가진 하위 태스크에 전이 학습하여 좋은 성능을 얻을 수 있었다. ImageNet-21k 혹은 JFT-300M 데이터에 대해 사전 학습했을 때, 다양한 이미지 인식 벤치마크에 대해 ViT는 SOTA, 혹은 그에 비견할만한 성능을 얻을 수 있었다.
<ViT 성능>
| ImageNet | ImageNet-ReaL | CIFAR-100 | VTAB | |
| ViT | 88.55% | 90.72% | 94.55% | 77.63% |
| Prev-SOTA | 88.61% (EfficientNet-L2-475) |
90.9% (FixEfficientNet-L2) |
96.08% (EfficientNet-L2) |
76.3% (BiT-L, Big Transfer) |
모델
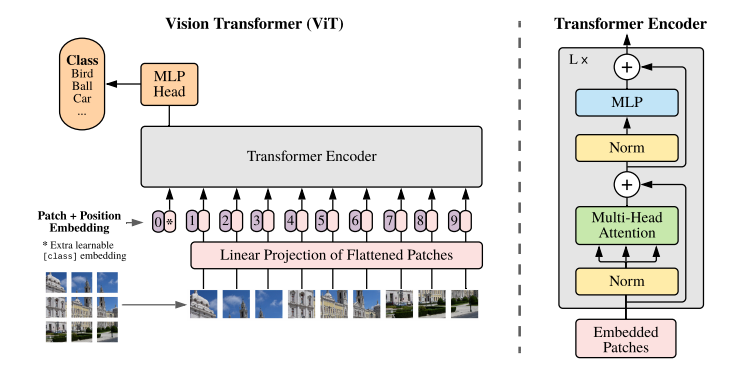
모델 개요: 이미지는 고정된 크기의 패치로 쪼개고, 각각을 선형적으로 임베딩한 후 위치 임베딩을 더하여 결과 백터를 일반적인 Transformer 인코더의 인풋으로 입력한다. 분류 과제를 수행하기 위해 추가적으로 학습되는 "classification token"을 만들어 시퀀스에 더한다.
3.1 Vision Transformer (ViT)
[ 이미지 인풋 ]
- 일반적인 Transformer은 토큰 임베딩에 대한 1차원의 시퀀스를 입력으로 받음
- 2차원의 이미지를 다루기 위해 논문에서는 이미지를 flatten된 2차원의 패치의 시퀀스로 변환함
- 즉, H x W x C → N x (P^2 x C) 로 변환
> (H, W)는 원본 이미지의 크기, C는 채널 개수를 의미
> (P, P)는 이미지 패치의 크기
> N = HW/P^2 = 패치의 개수
- Transformer은 모든 레이어에서 고정된 벡터 크기 D를 사용하기 때문에 이미지 패치는 펼친 다음 D차원 벡터로 linear projection 시킴
- BERT의 [CLS]토큰과 비슷하게 임베딩 된 패치의 시퀀스에 z0 = x_class 임베딩을 추가로 붙여 넣음
- 이후 이 패치에 대해 나온 인코더 아웃풋은 이미지 representation으로 해석하여 분류에 사용
[ 위치 임베딩 ]
- 각각의 패치 임베딩에 위치 임베딩을 더하여 위치 정보를 활용할 수 있도록 함
- 학습 가능한 1차원의 임베딩을 사용
- 2차원 정보를 유지하는 위치 임베딩도 활용해 보았으나, 유의미한 성능 향상은 없었기 때문

[ 하이브리드 아키텍처 ]
- 이미지 패치를 그대로 사용하는 대신, CNN의 결과 나온 feature map을 인풋 시퀀스로 사용할 수 있음
- 하이브리드 모델에서는 패치 임베딩 프로젝션을 CNN feature map에서 결과로 나온 패치에 대해 적용함
- 특수한 케이스로 패치는 1x1 크기를 가질 수 있는데, 이 경우는 인풋 시퀀스를 단순히 feature map에 대한 차원으로 flatten 한 후 Transformer의 차원으로 projection 한 결과임
- [CLS]에 해당하는 인풋 임베딩과 위치 임베딩은 기존 모델과 동일하게 적용함
3.2 fine-tuning과 높은 해상도 이미지 다루기
ViT는 대량의 데이터셋에 대해 사전 학습한 후 더 작은 다운스트림 태스크에 fine-tuning 하는 방법을 취한다.
Fine-tuning시에는 사전 학습된 prediction head를 제거하고, 0으로 초기화된 D x K차원의 FC-Layer를 연결한다. (K=다운스트림 태스크 카테고리 개수)
이때 fine-tuning단계에서는 더 높은 해상도에서 학습하는 것이 정확도 향상에 좋다는 것이 알려져 있다.
더 높은 해상도의 이미지를 처리해야 할 경우, 이미지 패치 크기를 동일하게 유지함으로써 더 긴 패치 시퀀스를 사용한다.
ViT는 더 높은 하드웨어의 메모리가 허용하는 한, 임의의 길이의 시퀀스를 처리할 수 있다.
단, 이 경우 사전 학습된 위치 임베딩이 의미없어진다.
이 경우 사전학습된 위치 임베딩에 원본 이미지에서의 위치에 따라 2D interpolation을 수행한다.
이러한 해상도 조절과 패치 추출 방식은 ViT에서 이미지의 2차원 구조에 대한 inductive bias를 수동적으로 다루는 유일한 포인트들이다.
실험 결과
모델 사이즈 >>

벤치마크 데이터셋 성능 >>

(정확도/ 모델 스케일링 실험에 대한 자세한 내용은 정리를 생략함)
4.5 Vision Transformer 탐색하기
ViT가 이미지 데이터를 어떻게 처리하는지 이해하기 위해 모델의 representation을 조사하였다.
[ 임베딩 프로젝션 ]
- ViT는 펼쳐진 패치를 더 낮은 차원의 공간으로 매핑한다.
- 아래 그림은 학습된 임베딩 필터 중 중요한 몇 가지 구성 요소들을 시각화한 것이다.

- 이러한 구성요소는 각각의 패치에 대해 저차원의 representation을 만드는 기본 함수들을 나타내는 것으로 해석된다.
[ 위치 임베딩 ]
- 선형 프로젝션 이후, 각각의 패치 representation에는 위치 임베딩이 더해지게 된다.
- 시각화 결과를 보면, 모델은 이미지 내의 거리 개념을 인코딩하여 위치 임베딩에서 유사성이 나타난다는 것을 알 수 있다.

- 즉, 가까운 거리에 있는 패치는 비슷한 위치 임베딩을 가지게 된다.
- 더 나아가 행-열 개념의 구조가 나타나는데, 같은 열이나 행에 위치한 임베딩이 비슷하게 나타난다는 것이다.
- 또한, 더 큰 그리드에 대해서는 sinusoidal 구조가 더 명확하게 나타나는데, 이는 위치 임베딩은 2차원의 이미지를 나타내는 법을 학습한다는 것을 의미한다. 사람이 디자인한 2차원 구조를 인식하는 임베딩이 성능 향상에 기여하지 못한 이유가 여기에 있을 것으로 보인다.
[ Self-attention ]
- Self-attention은 가장 밑단에 있는 레이어에서부터도 ViT가 전체 이미지에 있는 정보를 통합하도록 돕는다.
- 이러한 능력을 어느 정도까지 활용할 수 있는지 조사하기 위해 attention weight에 기반하여 이미지 공간 상에서 정보가 취합되는 평균 거리를 구해보았다. (여기서 attention distance는 CNN에서 receptive field와 비슷하게 해석할 수 있다.)
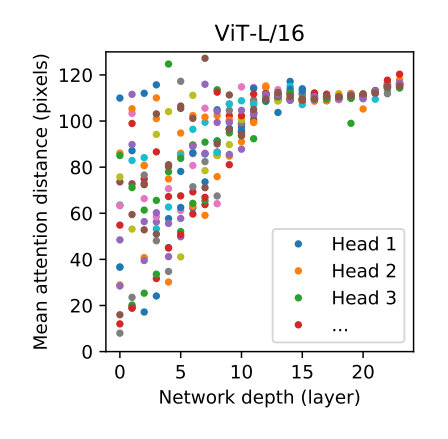
- 실험 결과 attention head 중 일부는 가장 낮은 레이어에서부터 대부분의 이미지에 attend 하고 있고, 이렇게 글로벌하게 정보를 통합하는 능력을 모델이 활용하는 것으로 보인다.
- 또 다른 attention head는 밑단 레이어에서 일관적으로 작은 거리의 패치에 집중하는 모습을 보였는데, 이렇게 지역적인 attention은 하이브리드 모델에서는 좀처럼 나타나지 않았다. 즉, 이 attention head는 CNN의 밑단에서 일어나는 것과 비슷한 작용을 하는 것이라고 유추할 수 있다.
- attention이 일어나는 거리는 네트워크의 깊이가 깊어질수록 늘어난다는 것도 찾을 수 있었다.
- 또한 전체적으로 모델은 의미적으로 분류 과제에 필요한 부분에 attend 하는 것을 찾을 수 있었다.

4.6 Self-supervision
- 라벨링 된 데이터셋에 대한 사전학습 대신 자기 지도 학습을 사전학습 과제로 실험을 진행
- 이미지에 대해 masked patch prediction 과제를 주고 ViT의 작은 모델 (ViT-B/16)을 학습해봄
- 그 결과, ImageNet에서 79.9%의 성능을 얻었고, 이는 from-scratch로 학습했을 때보다 2% 높은 성적.
- 하지만 이는 supervised pretraining에 비해 4% 떨어지는 정확도이다.

'AI > Algorithm&Models' 카테고리의 다른 글
| [논문리뷰] DALL-E: Zero-Shot Text-to-Image Generation (2) | 2021.03.13 |
|---|---|
| Multimodal Deep Learning and AI Research : 멀티모달 연구에 대한 생각 (0) | 2021.02.16 |
| 인공지능의 시대, 튜링 테스트를 넘어선 새로운 비전이 필요하다 (2) | 2021.01.09 |
| [논문리뷰] Are Sixteen Heads Really Better than One? (0) | 2020.12.29 |
| [논문리뷰] MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices (0) | 2020.12.18 |