너무너무 궁금했던 DALL-E 페이퍼가 공개되었어요 두근두근❤
사상은 예상했던 대로 텍스트와 이미지를 하나의 스트림 (concat)으로 트랜스포머에 밀어 넣는다는 것
이때 denoising VAE를 사용하여 픽셀 단위의 이미지를 이미지 토큰으로 변환해 사용했다고 한다.
이번 논문 역시 #대용량데이터와 #대규모모델이 핵심 키워드였는데,
large-scale 모델 학습을 위한 16-bit 학습, distributed optimization 등 다양한 노하우가 녹아있다.
논문: arxiv.org/pdf/2102.12092.pdf
깃헙: github.com/lucidrains/DALLE-pytorch
Abstract
본 논문에서는 하나의 데이터 소스로부터 transformer를 활용하여 text-to-image 태스크를 auto-regressive하게 모델링하는 방법을 제안한다. 충분히 많은 데이터와 큰 스케일을 사용할때, 이 접근법은 zero-shot 스타일로 평가했을 때에도 기존의 도메인 특화적인 기법에 비견할만한 성능을 보인다.
Background
Text-to-image는 텍스트를 인풋으로 받아 이미지를 생성하는 태스크이다.
모델은 자연어 텍스트와 의미적으로 알맞으면서 자연스러운 이미지를 생성할 것을 목표로 한다.
대표적인 데이터셋으로는 MS-COCO와 CUB 데이터셋이 있다.
MS-COCO
object detection, segmentation, captioning 태스크를 위해 구축된 대규모의 데이터셋이다.
이미지 캡셔닝 데이터의 경우, 이미지 당 5개의 캡션이 달려있다.

CUB
북미 새 200종에 대한 11,788개의 이미지를 포함하는 데이터셋으로, 각 이미지에 대한 5개의 fine-grained 설명을 포함한다.

평가 척도
IS(Inception Score) - 생성된 이미지의 질을 평가하기 위한 척도로, 특히 GAN 모델 평가에 사용된다. IS는 사전학습된 딥러닝 모델을 사용하여 생성된 이미지를 분류한다. 특히, inception-V3 모델을 사용한다(이름이 Inception Score인 이유). 생성된 모델을 분류기에 넣으면 특정 클래스에 속할 확률이 계산될 것이다. 이러한 예측 결과가 IS로 요약되어 평가되는 것이다. IS는 <이미지의 질: 이미지는 어떤 특정 물체 같아 보이는가?>와 <이미지의 다양성: 다양한 물체가 생성되었는가?>로 평가된다. IS는 최저 점수 1점 ~ 최고 점수 1000점을 가진다(사전학습 모델이 분류할 수 있는 물체의 클래스 수)
FID(Fréchet inception distance) - 실제 이미지와 생성된 이미지 사이의 feature vector간의 거리를 계산한 점수이다. IS와 마찬가지로 inception-v3 모델을 사용하여 마지막 pooling layer에서 나온 벡터 간의 거리를 평가한다. 2020년 기준으로 GAN모델의 결과를 평가하는 표준 척도로 사용하고 있고, FID가 낮을수록 좋은 모델로 해석할 수 있다.

기존 접근법
기존의 연구는 특정 데이터셋에 대해 잘 작동하는 모델링 기법을 찾아내는 데에 집중되어 있었다. 이 과정에서 복잡한 아키텍처나 보조 손실함수, 추가적인 정보(물체 라벨/ segmentation 마스크 등)가 활용되기도 했다. 대표적인 아키텍처로 AttnGAN, DM-GAN, DF-GAN 등이 있다.
** 참고자료
- machinelearningmastery.com/how-to-implement-the-frechet-inception-distance-fid-from-scratch/
IDEA
- 120억 개 파라미터의 autoregressive transformer 모델을 2억 5천만 장의 이미지-텍스트 쌍에 대해 학습
- 데이터셋은 인터넷에서 수집하였으며, 그 결과 유연하면서 자연어로 통제 가능한 이미지 생성 모델을 학습
- 결과적으로 MS-COCO 데이터셋에서 zero-shot으로도 높은 성능을 획득
(사람이 평가했을 때, 평가자들이 기존 연구 결과보다 90% 더 높게 선호한다는 결과)
- 또한, image-to-image translation에서도 기본적인 수행 능력을 가지는 것을 확인하였다

놀라운 것은 실험 결과, 자연어로 묘사한 다양한 컨셉을 꽤나 창의적이고 그럴듯한 방법으로 조합해냈다는 것 👏
어떻게 이런 것이 가능했을까?
DALL-E의 목표는 autoregressive하게 텍스트와 이미지 토큰을 하나의 스트림으로 받아들여 트랜스포머를 학습시키는 것.
나이브하게 생각할 수 있는 방법은 이미지 픽셀과 텍스트를 적당히 임베딩해서 트랜스포머에 집어넣는 것이다.
하지만 이미지 토큰으로서 픽셀을 직접 활용하게 되면 고해상도의 이미지에 대해 엄청난 메모리가 소요된다.
게다가 Likelihood 목적함수(PixelCNN++)는 픽셀 사이의 짧은 디팬던시를 모델링하고, 우리가 인식해야 하는 이미지의 구조(low-frequency)보다는 지나친 디테일(high-frequency)을 학습하는 데에 지나친 모델링 자원을 사용하게 된다.
따라서 DALL-E에서는 2-stage 학습 단계를 통해 이러한 문제를 해결한다.
Stage 1.
- discrete VAE를 학습하여 256x256 RGB 이미지를 32x32 그리드의 이미지 토큰으로 압축한다.
- 각각의 이미지 토큰은 8192가지 값을 가질 수 있다고 가정한다.
- 이러한 압축을 통해 transformer가 처리해야 하는 context 크기를 192배 압축하면서, visual quality는 유지할 수 있다.

-> 인코더는 공간적인 해상도를 8배 줄이는 작용을 한다. 디테일(예. 고양이 털의 질감이라던지 글씨, 얇은 선)은 일부 손실되거나 왜곡되지만, 전반적인 이미지의 특성은 여전히 알아볼 수 있는 수준이다. 논문에서는 8192라는 큰 vocabulary size를 사용함으로써 정보의 손실을 최소화하였다.
🦊 트랜스포머의 Self-attention은 인풋 토큰(=문맥)의 길이에 제곱한 연산량을 가진다. 이미지를 픽셀 단위로 넣게 되면, 문맥의 길이는 가로x세로 해상도의 크기만큼 커져 연산에 부담이 생기면서도 각 토큰이 담는 정보량은 RGB로 적은 상황이 된다. DALL-E에서는 dVAE를 통해 원본 이미지 해상도만큼의 문맥을 (32x32=1024)로 줄이는 대신, 각 토큰의 정보 벡터를 크게(8,192) 가져감으로써 트랜스포머 아키텍처에 더 적합한 형태로 변형한 것이다.
<Variational AutoEncoders>
AutoEncoder은 뉴럴 넷에서 차원을 압축하기 위해 고안된 방법이다. Encoder-Decoder 세팅에서 점진적으로 최적화를 통해 입력 데이터(x)에서 필요한 정보를 압축한 벡터(z=e(x))를 인코딩하는 것을 목표로 한다.
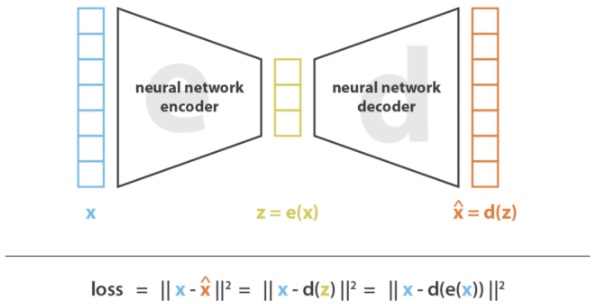
이러한 auto-encoder은 맥락을 가지는 이미지를 생성하는 태스크에 활용할 수 있다. 인코딩 된 벡터는 어떠한 "특징(예. 피부색, 머리색, 성별 등)"을 담은 latent variable으로 볼 수 있다. 그렇다면 디코딩 시에 만들고 싶은 특징에 대한 latent space에서 샘플링한 벡터를 활용하면 원하는 특징에 따른 이미지를 만들 수 있을 것이다. 하지만, 이런 식으로 잘 통제된 latent vector를 찾는 것은 쉽지 않은 일이다. 여기서 variational autoencoder가 등장한다. 디코더를 생성 목적으로 사용하기 위해서는 latent space가 regular해야 한다는 전제조건이 있다. 이러한 regularity를 확보하기 위해 학습 과정에서 auto-encoder를 regularize하여 과적합을 방지하고, latent space가 생성에 적합한 성질을 가지도록 하는 것이 VAE의 핵심이다.
VAE에서는 인풋이 latent space에 대한 확률분포로 인코딩된다. 이제 latent space로부터의 점은 해당 분포로부터 샘플링되고, 샘플링된 포인트가 decoding되어 reconstruction error를 계산하게 된다. 구현 관점에서 인코딩된 확률분포는 정규분포로 prior를 주는데, 이로써 인코더는 평균과 covariance matrix를 리턴하면 된다.
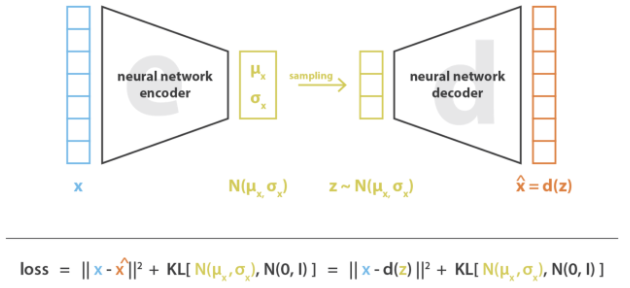
<Discrete Variational AutoEncoders>
그런데, 이러한 latent variable이 discrete prior를 가진다면, 이러한확률 모델은 이산적인 클래스를 가지는 데이터셋을 자연스럽게 포착할 수 있을 것이다. 하지만 이산 분포에 대한 backprop은 일반적으로 불가능하기 때문에 이러한 모델은 학습이 어렵다. dVAE는 discrete latent variable을 사용하여 VAE를 backprop을 통해 학습할 수 있는 방법을 제안한 것이다. DALL-E에서는 latent variable을 32x32 grid에 대해 V=8,192인 사전을 가지도록 디자인했기 때문에 dVAE 아키텍처를 활용했다.
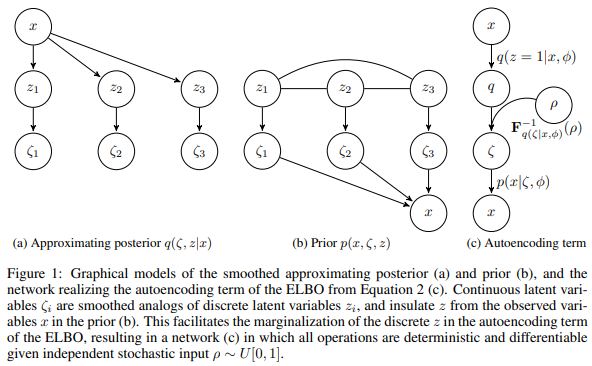
**참고자료:
- towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73
Stage 2.
- 256개의 BPE-인코딩된 텍스트 토큰과 32x32=1024 이미지 토큰을 concat하여 트랜스포머에 입력
- 텍스트와 이미지 토큰에 대한 결합 확률 분포를 학습한다.
전체적인 학습 프로세스는 이미지 x와 캡션 y, 인코딩된 RGB이미지에 대한 토큰 x의 결합확률분포에 대한 evidence lower bound(ELB)를 최대화하는 과정으로 해석할 수 있다.
이 과정은 확률분포를 factorize하여 다음과 같이 모델링한다:

그리고 이 모델의 lower bound는 다음과 같다:

이 lower bound는 beta = 1일 때만 성립하지만, 실제적으로는 더 큰 값을 사용하는 것이 유효했다.
** 참고자료
- ELB : Auto-Encoding Variational Bayes / Stochastic backpropagation and approximate inference in deep generative models
- ELB explained: mbernste.github.io/posts/elbo/
- Lower bound property: beta-VAE
METHOD - detail
2.1. Stage One: Learning the Visual Codebook
첫 번째 단계에서는 pi와 theta에 대해 ELB를 최대화하는데, 이는 이미지만에 대해 dVAE를 학습한다는 뜻이다.
- 초기 prior $p_psi$는 K=8192의 codebook vector에 대한 uniform categorical distribution으로 설정하고
- $q_phi$는 인코더 아웃풋인 32x32 그리드 공간에 대한 8192 logit에 대한 categorical distribution으로 파라미터화
이러한 셋팅에서 ELB는 optimize 하기 상당히 까다롭게 된다:
- $q_phi$는 이산 확률분포이기 때문에 그라디언트를 최대화하기 위해 reparameterize하기 어렵다.
- 기존 연구에서는 이로 인해 online cluster assignment procedure + straight-through estimator를 사용하기도 했다.
- DALL-E에서는 gumbel-softmax relaxation을 사용하여 $q_phi$에 대한 기댓값을 $q_phi^T$로 대체한다. (T->0으로 될수록 덜 relax)
Relaxed ELB는 Adam으로 최대화하고, exponentially weighted iterate averaging을 사용한다.
이때 안정적인 학습을 위해 다음과 같은 세 가지가 중요하다는 것을 발견하였다:
1. relaxation temperature과 step size에 대한 annealing schedule :
T를 1/16으로 annealing 하면 relaxed validation ELB가 실제 validation ELB와 거의 유사해진다는 것을 발견했다.
2. 인코더의 마지막과 디코더의 시작점에 1x1 컨볼루션 사용하기 :
relaxation 주변의 컨볼루션에서 receptive field 크기를 줄였을 때 실제 ELB로 더 잘 일반화한다
3. 인코더와 디코더 resblock에서 나가는 activation에 작은 상수 곱하기 : 시작 부분에서 학습이 안정적
또한 KL weight beta = 6.6으로 설정했을 때 학습이 끝난 후 reconstruction error가 작다는 것을 실험적으로 발견했다.
2.2 Stage Two: Learning the Prior
두 번째 단계에서는 $phi$와 $theta$를 고정한 채 텍스트와 이미지 토큰에 대한 prior distribution을 학습한다.
이때 $psi$에 대한 ELB를 극대화하며, $p_psi$는 120억 파라미터를 가지는 sparse transformer를 사용한다.
텍스트와 이미지 쌍이 주어질 때,
- 캡션은 소문자화한 후 16,384개 단어 사전을 사용해 BPE-encode한다. (최대 256 토큰)
- 이미지는 32x32 = 1024 토큰으로 인코딩하고, 이때 단어사전 수는 8192이다.
- 이때 이미지 토큰은 dVAE인코더 로짓에서 argmax sampling을 통해 얻는다. (gumbel noise를 더하지 않음)
- 최종적으로 텍스트와 이미지 토큰은 concat하여 하나의 데이터 스트림으로 모델에 입력한다.

트랜스포머는 decoder-only model로, 이미지 토큰은 64개의 self-attention layer에서 모든 텍스트 토큰에 접근 가능하다.
이러한 모델에 대해 self-attention mask를 어떻게 사용하느냐에 따라 세 가지 변형이 가능하다:
- text-to-text attention : 항상 casual mask 적용
- image-to-image attention : row / column / convolutional attention mask 적용 가능
이때 논문에서는 <텍스트가 텍스트에 attend>, <이미지가 텍스트에 attend>, <이미지간의 attend>를 모두 수행할 수 있는 하나의 attention operation을 찾아내 사용하였고, 이 방법은 각각 필요한 attention을 독립적으로 사용하는 것보다 좋았다.
텍스트 캡션의 길이를 256 토큰으로 제안했지만, 마지막 텍스트 토큰과 이미지의 시작 사이 padding 부분에서는 무엇을 해야 할지 명확하지 않았다. 하나의 방안은 해당 부분의 self-attention에서 logit을 -inf로 설정하는 것이다. 하지만 논문에서는 256개의 텍스트 위치에 따라 각기 다른 special padding 토큰을 추가해 사용하였다. 이 토큰은 텍스트 토큰을 사용할 수 없을 때만 사용하게 된다. 이 방법은 validation loss를 높게 만들 수 있지만, OOD caption에 대해 더 작 작동한다.
<트랜스포머 인풋 구조 예시>
아래 그림은 MAX_TEXT_LEN=6일때 트랜스포머 구조를 보여준다.
각각의 박스는 모델의 벡터 사이즈인 d_model = 3968을 나타낸다.
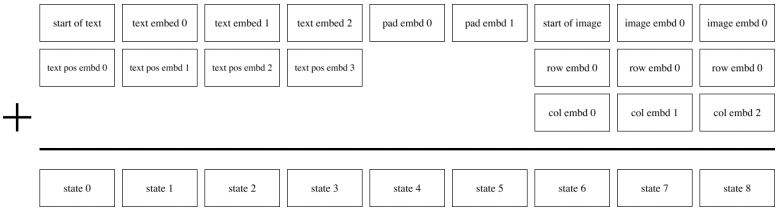
텍스트의 경우
- <start of text> 스페셜 토큰으로 시작
- 실제 토큰이 들어온 경우 텍스트 임베딩 + 위치 임베딩이 더해져서 벡터로 들어감
- <padding>이 필요한 경우, padding에 대한 임베딩이 들어감.
- 이때 pad임베딩은 몇 번째 패딩이냐에 따라 다르게 학습된 임베딩.
이미지의 경우
- <start of image> 스페셜 토큰
- 이미지 토큰에 대한 임베딩(8192->d_model) + row position embedding + col position embedding
텍스트와 이미지 토큰에 대한 cross-entropy loss는 배치에 있는 각각의 텍스트와 이미지 토큰의 개수를 사용하여 normalize했다. 기본적으로 이미지 모델링에 관심이 있기 때문에 텍스트에 대한 cross-entropy loss에는 1/8, 이미지에 대한 cross-entropy loss에는 7/8을 곱하여 loss를 계산하였다. 이 목적함수는 Adam + exponentially weighted iterate averaging을 통해 최적화한다. (Appendix B.2)
2.3. Data Collection
기존에 Conceptual Captions 데이터에 대해 12억 파라미터로 실험을 했을 때, MS-COCO의 확장본으로 330만 장의 텍스트-이미지 쌍을 사용했다.
이번에는 모델 파라미터를 120억으로 10배 scale up하기 위해서, JFT-300M과 비슷한 스케일로 2억 5천만 장의 텍스트-이미지 쌍 데이터를 수집했다. 이 데이터는 MS-COCO 데이터를 포함하지 않지만, Conceptual Captions와 YFCC100M의 필터링된 부분집합을 포함한다. MS-COCO는 YFCC100M으로부터 만들어졌기 때문에, 학습 데이터는 MS-COCO validation image를 일부 포함할 수 있다.
2.4 Mixed-Precision Training
GPU 연산 자원을 아끼고 throughput을 증대하기 위해
- 16-bit precision 사용 : 대부분의 파라미터와 Adam moment, activation은 16-bit 정밀도로 저장
- activation checkpointing & backward pass에서 resblock 내의 activation을 재연산한다.
여기서 10억 개가 넘는 파라미터를 16-bit 정밀도를 사용해 diverge하지 않게 학습하는 것이 가장 어려운 파트였다!!
논문에서는 학습 불안정성의 원인이 16-bit 그라디언트에서 생기는 underflow 때문인 것으로 분석하였다.
이에 학습 중에 underflow를 방지하기 위한 가이드라인을 작성하여 사용하였다. (Appendix D 참고)
그중 하나의 방법은 per-resblock gradient scaling이다.
- Resblock에서 생기는 activation gradient의 norm은 초기 resblock에서 멀어질수록 단조 감소한다.
- 모델이 깊어지고, 넓어질수록 윗단의 resblock에 있는 activation gradient의 exponent는 16-bit 형식의 최소 단위보다 작아질 수 있다.
- 결과적으로 이러한 그라디언트는 0으로 반올림되고, underflow 현상이 생기는 것이다.
- 이러한 underflow 현상만 제거하더라도 모델을 안정적으로 수렴하게 할 수 있음을 발견했다.
일반적인 mixed precision 학습을 사용하면 절댓값 기준으로 activation gradient의 최소~최댓값 범위에서는 underflow를 방지하면서 16-bit 정밀도를 유지할 수 있다. NVIDIA V100 GPU에서 이 범위는 5bits로 설정되어있다. 이 정도 정밀도는 같은 스케일의 언어 모델에 있어서는 충분하나, text-to-image 모델에서는 부족하였다.
따라서 모델에 있는 각각의 resblock에 대해 각기 다른 gradient scale을 사용한다.
이 방법은 Flexpoint라고 불리는 일반적인 mixed-precision training의 대안이라고 생각할 수 있다.
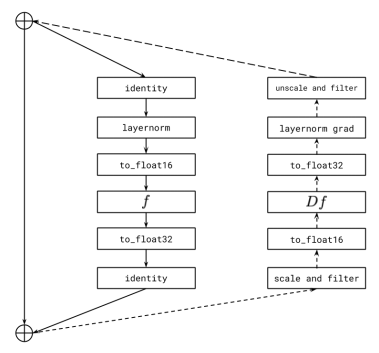
<per-resblock gradient scaling에 대한 개념도>
실선은 forward propagation에서 이루어지는 연산을, 점선은 backpropagation 연산을 나타낸다. 각각의 resblock에 들어오는 그라디언트를 각각의 그라디언트 스케일을 사용해 scaling 하고, 내보내지는 그라디언트를 연속적인 resblock의 그라디언트에 더하기 전에 unscale 한다. identity path에 있는 그라디언트와 activation은 32-bit 정밀도로 저장되어 있다. [filter] operation은 모든 Inf 혹은 Nan value를 0으로 대체한다. 이를 수행하지 않으면 현재 resblock에서 발생한 noninfinite 이벤트가 이후 resblock에 있는 모든 그라디언트의 스케일을 불필요하게 낮추고, underflow를 야기하기 때문이다.
🦊 무슨 말인지 모르겠군 ^^.....
2.5 Distributed Optimization
120억 파라미터 모델은 16-bit precision으로 저장하더라도 24GB 메모리를 차지한다.
따라서 parameter sharding을 사용하여 GPU 한 대에도 모델이 다 올라가지 않는 문제를 해결한다.
parameter sharding은 compute-intensive 연산을 사용하여 intra-machine 간의 통신에서 생기는 latency를 거의 없앤다.
모델 학습을 위해 구축한 클러스트에서 머신 사이의 bandwidth는 같은 머신 내의 GPU간의 bandwidth보다 훨씬 작다.
이로써 머신 간에 그라디언트를 취합하는 과정에서 드는 비용이 병목으로 작용하게 된다.
논문에서는 PowerSGD를 사용해 그라디언트를 압축함으로써 이러한 비용을 최소화하였다.
PowerSGD가 필요한 이유는 다음과 같다:
1. backprop과정에서 그라디언트를 error buffer로 축적해둠으로써 각기 다른 buffer를 할당하는 것 대비 메모리를 절약
2. error buffer를 0으로 만드는 인스턴스를 최소화 (mixed-precision backprop에서 생기는 nonfinite 값 혹은 체크포인트에서 모델을 재시작할 때 등)
3. Gram-Schmidt 대신 Householder orthogonalization을 사용함으로써 수치적인 안정성을 더한다.
4. 16FP를 사용함으로써 발생할 수 있는 underflow를 피할 수 있다.
2.6 Sample Generation
트랜스포머로부터 샘플링한 결과물을 pretrained contrastive model을 사용하여 rerank한다.
이미지 캡션에 대한 후보 이미지가 주어졌을 때, contrastive model은 이미지가 캡션과 얼마나 잘 매칭 되는지에 기반하여 점수를 매겨준다. 이 과정은 language-guided search의 일환으로 볼 수 있고, 또한 auxiliary text-image matching loss를 사용하는 것과도 비슷하다고 볼 수 있다.

향후 실험 결과에서는 temperature reduction 없이(t=1) N=512를 사용해 reranking한 결과를 보여준다 (그림2제외)
Experimental Results
3.1 Quantitative Results
- 기존 방법론 - AttnGAN, DM-GAN, DF-GAN
- DALL-E - zero-shot 셋팅에서 평가
아래 그림은 기존 방법론들과 DALL-E의 결과를 정성적으로 비교한 결과이다.

아래 도표들은 MS-COCO와 CUB 데이터에 대해 DALL-E와 기존 방법들을 비교한 결과이다.
그림에서 X축은 Gaussian blur를 적용할 때의 radius size를 나타낸다. dVAE 인코더로부터 나온 토큰을 사용하여 트랜스포머를 학습한 논문의 접근법은 모델이 시각적으로 인간에게 정보를 전달할 수 있는 low-frequency 특성을 모델링할 수 있도록 하였다. 하지만 이는 동시에 정보의 압축으로 인해 디테일(high-frequency)은 살리지 못하게 한다는 약점으로 작용하기도 한다. 이러한 효과를 고립하여 테스트해보기 위해 Validation 정답 데이터에 가우시안 필터를 적용하여 점수를 계산한 결과를 함께 report한다.


<Figure 9-(a)> MS-COCO 대한 FID & IS, Blur 사이즈에 대해 그림
MS-COCO 데이터에 대해 DALL-E 모델은 FID 점수에 있어 기존의 최고 모델의 2point 이내로 차이나는 좋은 성적을 거두었다. 특히 이는 데이터에 특화된 학습 없이 얻은 결과이다. DALL-E 에서 사용한 데이터는 YFCC100M 데이터에 대한 부분집합을 포함하고, 이는 MS-COCO validation 데이터 중 21%를 차지한다는 것을 알아냈다. 이러한 효과를 제거하기 위해 학습에 포함된 데이터를 제거하고 점수를 계산해 보았으나, 특별한 차이점은 없었다.
(실선 - 전체 validation data 결과, 점선 - 해당 데이터 제거한 결과)
가우시안 블러의 경우 특히 radius 1의 블러를 적용했을 때 최고의 FID 점수를 얻을 수 있었다. 블러 사이즈가 커질 경우, 다른 모델과의 격차가 많이 벌어졌다.
🦊 음... 결과를 극대화해 보이기 위한 트릭 아닌가욘...? 뭐.. 어쨌든 radius=0일때도 MS-MOCO에서는 좋은 결과

<Figure 9-(b)> CUB 대한 FID & IS, Blur 사이즈에 대해 그림
CUB 데이터셋에 대해서는 CUB데이터에 대해서는 좋지 않은 결과를 얻었는데, 기존 SOTA 대비 40 point가량 떨어지는 것으로 나타났다.
이는 CUB 데이터셋을 zero-shot으로 접근하는 것이 fine-tuning의 접근 방식 대비 특이한 도메인을 포착하기에 적합하지 않았기 때문인 것으로 분석한다.
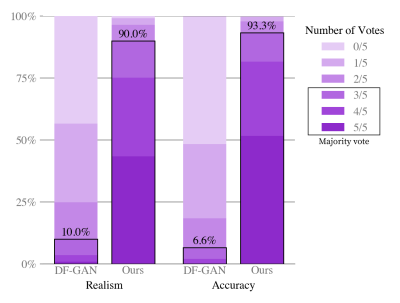
<모델에 대한 human evaluation 결과>
MS-COCO 데이터에 대해 다섯 개 중 가장 현실적인 이미지를 고르도록 했을 때, DALL-E는 90%의 확률로 선택되었다.
캡션과 가장 매칭 되는 이미지를 고르도록 했을 때, DALL-E는 93.3% 선택되었다.
3.3 Qualitative Findings
DALL-E는 전혀 예상하지 못했던 방향으로도 텍스트->이미지 태스크를 푸는 것으로 나타났다.
예를 들어 <아코디언으로 만들어진 코가 뾰족하게 생긴 돼지> 같은 캡션에 대해서도 이미지를 생성해냈다!
뿐만 아니라 복합적인 생성도 가능한 것으로 일부 보였지만, 이러한 태스크에 대해서는 일관성 없는 결과를 도출하였다.
어느 정도의 신뢰성 내에서 image-to-image translation도 가능한 것으로 나타났다.
더 다양한 예시는 OpenAI 홈페이지에서 만나볼 수 있다

🦊트랜스포머에 텍스트와 이미지를 동시에 인식시키기 위해 dVAE를 통해 [이미지 토큰]을 만들어낸 것이 흥미로웠다. 결국 라지 스케일 학습을 통해 V=8192가지에 해당하는 이미지 특질이 자연어와 결합 확률분포를 학습했을 것이라는 점이 재밌다. 하지만 dVAE의 학습과 트랜스포머 학습이 독립적으로 이루어지다 보니 좀 더 깊은 인터렉션이 안된다는게... 암튼 이미지 토큰에 대한 사전개수는 어떻게 결정됐는지, 실제로 text-to-image sampling은 어떻게 구현했는지 부분은 좀더 스터디해보기!




