논문: https://arxiv.org/pdf/2104.11178.pdf
IDEA
- 라벨링되지 않은 데이터를 사용하여 multimodal representation을 학습하는 프레임워크
- VATT는 raw signal들을 인풋으로 받아 다운스트림 태스크에 적용할 수 있는 multimodal representation을 추출
- multimodal contrastive loss를 사용하여 모델을 E2E로 학습하고, 다양한 태스크에 평가
- modality에 국한되지 않는 single backbone Transformer에 대해 탐구한다 (sharing weight)
Introduction
▲ Inductive bias vs Large scale training
Convolution Neural Network는 컴퓨터 비전 태스크에 있어서 좋은 성적을 거두어왔다.
Convolution 연산이 가지는 inductive bias인 translation invariance와 locality가 이미지에 있어 효과적이기 때문이다.
하지만 자연어처리분야에서는 RNN처럼 강한 inductive bias를 가지는 모델에서 self attention 기반의 일반적인 아키텍처로의 패러다임의 전환이 일어났다. 즉, Transformer 모델이 NLP에 있어서 아주 효과적인 아키텍처라는 것이 증명되었고, 특히 대규모 코퍼스에 대해 Transformer을 사전학습한 후 다운스트림 태스크에 fine-tuning하는 것은 SOTA 달성의 핵심이 되었다.
이러한 성공에 힘입어 비전 분야에서도 attention 매커니즘을 적용하고자 하는 연구가 활발하게 이루어졌고, < 라지스케일의 (지도학습방식의) 사전학습이 (이미지 분류 문제에 있어서는) CNN의 inductive bias를 이겼다 >는 연구 결과도 나왔다. (참고: ViT- Vision Transformer )
하지만 Transformer 아키텍처에 대한 라지스케일의 지도학습 기반 사전학습은 두 가지 문제가 있다.
1. 지도학습 기반 방식은 비주얼 데이터에 있어 더 많은 부분을 차지하는 unlabeled, unstructured visual data를 배제한다.
2. 이 방식은 비전에서 Transformer을 적용할 수 있는 부분을 제한하게 되는데, 라벨링된 이미지나 비디오를 모으고, 하이파라미터를 고른 후 일반화 성능을 검증하는 데에 많은 비용과 시간이 들기 때문이다.
따라서 본 논문에서는 다음과 같은 질문에 초점을 맞춘다 :
" 어떻게 라지스케일의, 라벨링되지 않은 데이터를 활용하여 트랜스포머를 학습할 수 있을까 "
▲ Organic supervision for vision
NLP 분야에서는 masked language modeling을 통해 트랜스포머를 사전학습을 한 것이 효과적이었다.(BERT, GPT)
성공의 요인에는 자연어는 트랜스포머 구조에 있어 본질적인 형태(organic supervision)를 가진다는 점이 있다.
시퀀셜한 단어와 구, 문장이 문맥을 이루고, 그것이 합쳐져 의미와 구조가 형성되기 때문이다.
이러한 맥락에서 볼 때, 시각 데이터에서 가장 본질적인 supervision이 가능한 데이터는 multimodal video다.
동영상은 디지털 세상에서 풍부하게 존재하고, 시간/공간적인 양상으로 인해 supervision에 적합하며 사람 라벨링이 필요 없다. 이러한 영상의 양은 어마어마해서, 비주얼 세계에서 미리 정의한 inductive bias 없이도 트랜스포머를 학습하기에 충분하다.
▲ 연구 주제
(1) 자기지도학습 기반의 multimodal 사전학습 연구
본 연구에서는 세 개의 트랜스포머에 대한 self-supervised multimodal pretraining을 연구한다
- 각각의 트랜스포머는 비디오의 raw RGB 프레임, 오디오 웨이브폼, 그리고 전사된 텍스트를 인풋으로 받는다.
- 이 트랜스포머를 VATT (video, audio, text Transformers) 라고 부른다.
VATT는 BERT와 ViT의 아키텍처를 거의 그대로 사용하는데, tokenization과 linear projection 부분만 각각의 modality에 따라 다르게 디자인하였다. 이는 아키텍처에 대한 수정을 최소한으로 하고도 다양한 프레임워크나 태스크로 transfer할 수 있도록 하기 위함이다. 또한, 사전학습의 경우 사람의 라벨링 공수는 최소화하도록 디자인하였다.
(2) modality-agnostic 모델에 대한 연구
더 나아가 VATT는 트랜스포머에 대해 강한 제약 조건을 걸었다 :
비디오, 오디오, 그리고 텍스트 modality에 있어 weight를 공유하는 것이다.
이는 모든 modality에 있어서 단일의, 일반적인 목적의 모델이 존재할 수 있는지 테스트하기 위함이다.
(물론 tokenization과 linear projection 레이어에 있어서는 modality간의 특수성이 여전히 존재한다)
이러한 관점에서 zero-shot video retrieval 태스크에 있어서의 결과는 예비 결과이지만 유의미한데,
modality-agnostic한 VATT가 modality 특수적인 모델에 비견할만한 성능을 낸 것이다.
(3) DropToken 제안
트랜스포머를 학습하는 데에 있어 복잡도를 줄이면서도 모델 성능에는 크게 영향을 주지 않는 DropToken 방식을 제안한다.
DropToken은 학습 과정에서 랜덤하게 인풋 비디오와 오디오 시퀀스의 토큰 중 일부를 drop하는 것을 의미한다.
이 방식은 트랜스포머 학습에 있어서 유의미했는데, 트랜스포머의 계산복잡도는 인풋 시퀀스 길이의 제곱에 비례하기 때문이다.
Approach
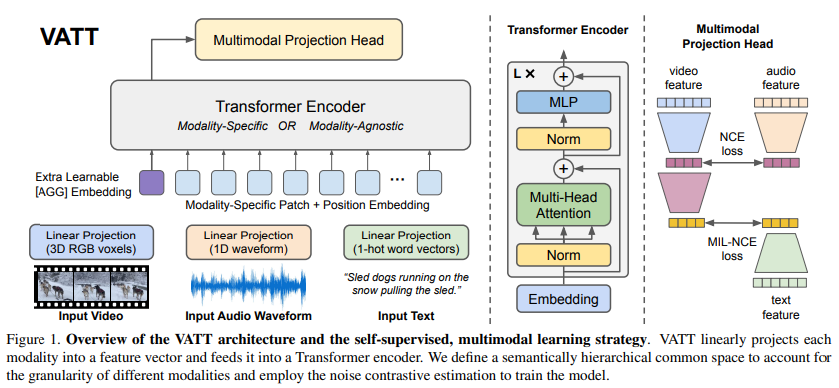
각각의 modality는 tokenization 레이어를 통해 raw input이 embedding vector로 프로젝션 되고, 트랜스포머 레이어를 탄다.
VATT는 두 가지 셋팅에서 실험을 진행하였다 :
1) 백본 트랜스포머가 각각의 modality에 대해 다른 웨이트를 가진다
2) 모든 트랜스포머는 웨이트를 공유하고, 어떠한 modality든 하나의 백본 트랜스포머를 통해 처리한다
어떠한 셋팅이든 백본은 modality 특이한 representation을 추출할 수 있으며, 그 결과는 common space로 매핑된다.
3.1 Tokenization & Positional Encoding
VATT는 raw signal을 인풋으로 받는다.
Vision : 영상 프레임의 3 채널 RGB 픽셀
- T x H x W 차원의 전체 비디어 클립을 [T/t] x [H/h] x [W/w] 패치의 시퀀스로 파티셔닝한다. (각 패치는 txhxwx3 voxels)
- 전체 voxal들에 대해 linear projection을 적용하여 d차원의 vector representation을 만든다.
- position encoding을 위해 dimention-specific한 학습 가능한 임베딩을 정의하여 계산한다 :

Audio : air density amplitude (wave-form 형태로 들어옴)
- raw audio waveform은 1차원의 인풋으로, 길이 T'를 가진다.
- 이를 [T'/t']개의 세그먼트로 파티셔닝하고, 각각의 패치는 t' 길이의 waveform이 되게 한다.
- 각각의 패치에 대해 linear projection을 적용하여 d차원의 vector representation을 만든다.
- position 인코딩을 위해 [T'/t']개 위치에 대한 학습 가능한 임베딩을 설정한다.
Text : 단어의 시퀀스
- 학습 데이터셋에 대해 v차원의 단어사전을 정의한다.
- 인풋 텍스트 시퀀스를 v차원의 one-hot-vector로 매핑한 후, 이를 d차원으로 매핑하는 임베딩 레이어를 거친다.
3.1.1 DropToken
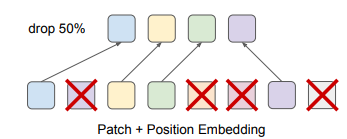
본 논문에서는 DropToken이라는 방식을 적용하여 트랜스포머 학습에 있어서의 복잡도를 줄인다.
비디오나 오디오에 대해 토큰 시퀀스를 인풋으로 받았을 때, 랜덤하게 토큰 중 일부를 샘플링하여 인풋으로 활용한다.
트랜스포머 계산 복잡도는 인풋 길이의 제곱에 비례하기 때문에, 이 방법을 통해 계산수를 효과적으로 줄일 수 있다.
raw input에 대해 해상도나 차원을 줄이는 대신, high-fidelity 인풋을 유지하면서 토큰을 샘플링하는 이 방법이 효과적이었는데, 비디오나 오디오에 있어 상당 부분은 반복성이 있기 때문인 것으로 분석한다.
3.2 The Transformer Architecture
VATT에서는 NLP에서 주로 사용되는 Transformer 아키텍처를 그대로 활용한다.

여기서 x_AGG는 전체 인풋 시퀀스의 정보를 모으는 데에 사용하는 learnable embedding이다.
이 토큰은 추후 classification과 같은 태스크에서 활용된다.
텍스트 모델에서는 position encoding을 제거하는 대신, Multi Head Attention 모듈의 첫 번째 레이어에서 각각의 attention score에 대해 relative bias를 학습하도록 하였다. 이렇게 모델을 수정함으로써 텍스트 모델의 웨이트를 SOTA 언어 모델인 T5에 바로 transfer할 수 있다.
3.3 Common Space Projection
모델을 학습에 있어서는 common space projection과 contrastive learning을 사용한다.
{비디오-오디오-텍스트} 트리플이 주어질 때, semantically hierarchical common space mapping을 정의함으로써 비디오-오디어 쌍, 그리고 영상-텍스트 쌍을 코사인 유사도를 통해 비교할 수 있도록 한다.
비디오, 오디오, 텍스트에 있어 semantic한 정교성에 있어 차이가 있다고 가정하면, 이런 비교는 특히 타당하다.
이를 위해 아래와 같이 multi-level projection을 정의하였다:

(a&b) g_v→va & g_a→va: 각각 영상과 오디오를 매핑하는 projection head로, 비디오와 오디오의 공통 공간인 S_va로 매핑
(c&d) g_t→vt & g_v→vt: 각각 영상과 텍스트를 매핑하는 projection head로, 비디오와 텍스트의 공통 공간인 S_vt로 매핑

이런 식으로 multi-level common space projection을 진행하는데, 다른 modality는 다른 수준의 semantic granularity를 가지기 때문에 이러한 사실을 inductive bias로 부가하여 common space projection을 실시한다는 아이디어이다.
여기서 (b)g_a→va와 (c)g_t→vt 는 단층의 lonear projection을 사용하였고, (a)g_v→va와 (d)g_v→vt는 ReLU activation을 사용해 두 층의 레이어를 사용하였다. 학습을 쉽게 하기 위해각 linear layer 뒤에 batch normalization을 사용하였다.
3.4 Multimodal Contrastive Learning
비디오-텍스트, 그리고 비디오-오디오 쌍에 대해 Noise-Contrastive-Estimation(NCE)를 사용한 자기지도학습을 고안했다.
▲ 데이터 구성
{비디오-오디오-텍스트} 스트림이 주어질 때, 다른 타임라인으로부터 비디오-텍스트 그리고 비디오-오디오 쌍을 구성한다.
같은 영상에서 온 쌍이라면, 두 modality를 positive pair로, 다른 영상에서 온 쌍은 negative pair로 간주한다.
NCE 목적함수는 positive 쌍간의 유사도를 극대화하고, negative 쌍간의 유사도를 최소화하는 방향으로 설정한다.
▲Multiple-Instance-Learning-NCE (MIL-NCE)
사전학습용 데이터에서 전사 텍스트는 일반 음성인식기를 사용했기 때문에 노이즈가 많이 섞여있다.
뿐만 아니라 어떤 ]아예 오디오나 텍스트가 존재하지 않는 영상 시퀀스도 존재했다.
따라서 Multiple-Instance-Learning-NCE를 사용해 영상 인풋을 타임라인상 가까운 여러 개의 텍스트 인풋에 매치한다.
(이 방법은 기존 연구에서 valina NCE를 변형하여 영상-텍스트 매칭 개선에 사용한 방법이다.)
본 논문에서는 비디오-오디오 쌍에 대해서는 일반적인 NCE Loss를, 비디오-오디오 쌍에 대해서는 MIL-NCE를 사용했다.
수식으로 쓰면, common space가 주어질 때, loss 함수는 다음과 같다.
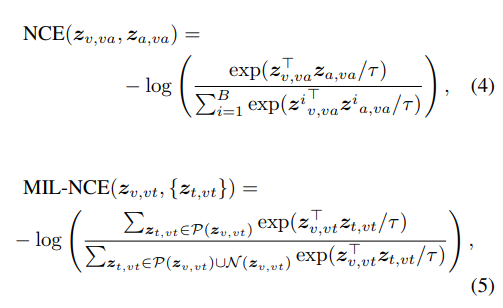
(4) 식에서 B는 배치사이즈로, B개의 비디오-오디오 쌍 중 하나가 positive pair인 배치를 구성해 학습한다.
(5) 식에서 P(z)와 N(z)는 각각 비디오 클립 $z_{v,vt}$ 주변의 positive / negative 텍스트 클립이다.
- $P(z_{v,vt})$ 는 비디오 클립에서 가장 가까운 다섯 개의 텍스트 클립을 포함한다.
- $tau$ 는 positive를 negative와 분리하는 목적함수에 softness를 부여하는 역할을 한다.
전체 VATT 모델의 E2E 목적함수는 다음과 같다.

($lambda$ 는 두 loss간의 비중을 조절한다)
Experiments
4.1 Pre-Training Datasets
internet videos
- 120만 개 영상
- 각각은 오디오, 내레이션 스크립트(자동 음성인식기로 전사)가 있는 여러 개의 클립들로 구성
- 1억 36만 쌍의 {비디오-오디오-텍스트} 트리플 존재
AudioSet
- 유튜브에 있는 200만 개의 영상에서 샘플링한 10초가량의 오디오 클립들로 구성
- 다양한 오디오 이벤트와 그에 대한 영상이 존재하지만 전사 텍스트는 부재함
데이터셋에 대한 라벨링 작업은 일절 이루어지지 않았고, 데이터셋들로부터 유니폼하게 클립들을 샘플링하여 미니배치를 구성.
AudioSet은 텍스트가 없기 때문에 텍스트 인풋을 0으로 채웠고, 여기서 나온 샘플에 대해서는 MIL-NCE loss 사용하지 않음.
4.2 Downstream Tasks and Datasets
Video action recognition
- UCF101 (101개 클래스, 13,320개 비디오)
- HMDB51 (51개 클래스, 6,766개 비디오)
→ 이 두 데이터셋은 모델 사이즈에 비해 데이터가 적기 때문에 vision 백본을 freeze하고 linear classifier만 학습
- Kinetics-400 (400개 클래스, 234,584개 비디오)
- Kinetics-600 (600개 클래스, 366,016개 비디오)
- Moments in Time (339개 클래스, 791,297개 비디오)
→ vision 백본으로 모델을 initialize한 후 해당 데이터들에 대해 fine-tuning을 진행함
Audio event classification
- ESC50 (50개 클래스, 2000개 오디오 클립)
→ audio Transformer을 freeze하고 linear classifier만 학습
- AudioSet (527개 클래스, 200만 개가량의 오디오 클립)
→ audio Transformer로 초기화한 후 fine-tuning 진행
Zero-shot video retrieval
- YouCook2 (3100개 영상-텍스트 쌍)
- MSR-VTT (1000개 영상-텍스트 쌍)
이 실험은 영상-텍스트 간의 common space representation이 잘 학습되었는지 평가하기 위해 진행한 것
형가 척도로는 Recall at 10 (R@10)을 측정함
Image classification
- 영상과 이미지 사이에는 도메인 차이가 존재하지만, VATT 사전학습으로 얻은 vision Transformer을 이미지 도메인에 적용해보았다.
- ImageNet에 바로 실험을 해보았고, 아키텍처나 tokenization 파이프라인에 수정을 가하지 않았다.
4.3 Experimental Setup
Input
- 비디오 : 사전학습 동안에는 두 개의 사전학습 데이터로부터 10 fps로 32 프레임을 샘플링. 이 프레임들에 대해 랜덤하게 시간적으로는 일관성 있도록 공간상에 크롭을 진행함 (relative area in [0.08, 1] / aspect ration [0.5, 2]) 이후 크롭된 영상은 224x224로 리사이즈하고, 이후 horizontal flip과 color augmentation 적용 / RGB 값은 [0,1] 사이에 있도록 값을 clipping하고, 인풋이 [-1, 1]에 있도록 normalize / 패치 사이즈는 4x16x16 사용
- 오디오 : 비디오 프레임과 싱크가 맞도록 48kHz로 샘플링. 인풋이 [-1, 1]에 있도록 normalize / 패치 사이즈 128 사용
- 텍스트 : vocabulary 사이즈는 2^16 (word2vec과 동일 ㅎㄷㄷ...). 시퀀스는 최대 16개 단어 포함하도록 함
사전학습 과정에서는 DropToken 50% 적용.
비디오 fine-tuning과 평가에 있어서는 32 frame + temporal stride 2로 25 fps로 샘플링 (2.56초) , 320x320 크롭
Network setup in VATT

- VATT-MA : modality agnostic 버전 - Medium 사이즈 사용
- Modality specific한 실험에서는 텍스트는 Small , 오디오는 Base 사이즈 사용
-> 이 설정 값에 따라 비디오-오디오-텍스트 백본에 대해 3가지 변형 모델 확보
-> Base-Base-Small (BBS), Medium-Base-Small (MBS), Large-Base-Small (LBS)
Projection heads and contrastive losses
- d_va(비디오-오디오 공간) = 512 / d_vt(비디오-텍스트 공간) = 256으로 설정
- NCE와 MIL-NCE 계산 전에 벡터를 normalize하고 temperature=0.07, lambda=1 사용
Pre-training setup
- Adam 옵티마이저를 사용해 VATT를 from-scratch로 사전학습
- 초기 learning rate = 1e-4 , 10k 스텝 동안 warmup 진행, 총 500k step동안 학습(배치사이즈=2048)
- quarter-period cosine schedule을 사용해 learning rate를 1e-4에서 5e-5까지 떨어뜨림
- 추가 탐색 실험에서는 배치 사이즈 512 사용
- TensorFlow v2.4에서 모델을 구현하였고, TPUv3 256개에서 3일간 학습
(비디오/오디/ 이미지 등 fine-tuning 전략은 정리 생략)
4.4 Results
4.4.1 Fine-tuning for video action recognition

- 모든 데이터셋에 대해 TimeSFormer을 포함한 기존 연구보다 높은 정확도를 얻음
- (a) 이 중 TimeSFormer은 지도학습기반 사전학습을 한 ViT로 초기화한 모델에 대해 fine-tuning을 진행한 모델임
- VATT는 사전학습에 있어 사람이 만든 라벨이 전혀 필요하지 않았음에도 좋은 모델을 만들었다는 점에서 유의미함
- VATT는 multimodal 비디오에 대해 self-supervision을 사용한 첫 번째 사례이며, from-scratch로 Transformer 모델을 학습한 것에 비해 획기적인 성능 향상을 보였다는 점에서 논문에서 제안한 사전학습 기법이 유의미하다는 것을 볼 수 있음.
- (b) 뿐만 아니라, VATT-MA-Medium 결과를 볼 때, modality에 국한되지 않고 비디오-오디오-텍스트 간에 백본을 공유하는 모델이 modality-specific 한 VATT-Base에 비견할만한 성능을 보임. 즉, 데이터 modality를 통합하여 단일 트랜스포머 백본을 사용할 수 있는 가능성을 보인 실험 결과로 해석.
4.4.2 Fine-tuning for audio event classification
Multi-label 오디오 이벤트 분류 데이터셋인 AudioSet에 평가하고, mAP와 AUC, d-prime 점수를 계산

- (a) 현존하는 CNN 기반의 모델 대비 모든 metric에 대해 성능이 우월함
- (b) modality agnostic 한 백본의 성능이 modality 특수성을 가지는 모델과 거의 동등한 성능을 보임
- VATT는 오디오 이벤트 분류 태스크에서 트랜스포머 모델로 CNN 기반 모델을 이긴 첫 번째 사례.
- 특히, 수작업으로 생성한 feature가 아닌 raw waveform을 인풋으로 사용한다는 점에 주목할만함.
4.4.3. Fine-tuning for image classification
이 실험은 multimodal 영상 도메인에서 학습한 지식을 이미지 도메인에 tranfer 할 수 있음을 보여준다.
결과표는 백본 구조를 수정하지 않은 채 VATT를 ImageNet에 fine-tuning 한 성능을 보여준다.
다만, VATT는 본래 voxel-to-patch 레이어가 있기 때문에, 이미지를 time에 맞게 4번 복사해 넣어주었다.

- (c)와 (d)를 볼 때, 영상 도메인에 대한 사전학습으로도 from-scratch 대비 크게 성능이 향상되었다
- 심지어 대량의 이미지 데이터에 대해 사전학습한 것(b)에 비견할만한 성능을 보였다.
4.4.4 Zero-shot retrieval
VATT-MBS 모델에 비디오와 텍스트 쌍을 인풋으로 넣고, S_vt 공간상에서 representation을 추출하였다.
이후 YouCook2와 MSR-VTT 데이터에 있는 각각의 비디오-텍스트 쌍 사이의 유사도를 계산하였다.
텍스트 쿼리가 주어질 때 영상과 쿼리의 유사도를 기반으로 영상의 랭킹을 매겼고, top-10으로 뽑힌 영상에 정답 영상이 있는지를 체크한 R@10 점수를 계산하였다. 또한, 정답 영상의 rank에 대한 중간값을 매겨보았다. 이러한 실험 결과를 기존의 두 가지 베이스라인 결과와 비교해 보았다.

- (b)~(c) zero-shot retrieval 성능은 배치사이즈와 epoch 수의 영향을 크게 받는다. (MMV에서도 밝혀진 연구 결과) 하지만 VATT(c)는 에폭 수와 배치 사이즈가 MMV 모델(b)의 절반임에도 불구하고, 그에 비견할만한 성능을 보였다.
- 더 큰 배치사이즈(8192)를 사용해서 더 오랜 에폭 동안(6 에폭) 학습하자, VATT의 성능은 YouCook2에서MIL-NCE와 완전히 성능을 얻었고, MSRVTT에서 R@10 29.2 / MedR 42를 얻었다.
- 또한 전사 텍스트가 noisy 데이터여서 그런지, VATT와 같이 정교한 언어 모델은 성능이 떨어지는 것을 관측했다.
- 간단한 linear projection만으로 모델이 잘 작동하였기 때문에, 향후 더 높은 품질의 텍스트 데이터를 탐구해볼 만할 것으로 예상한다.
4.4.5 Linear Evaluation
VATT의 백본 웨이트를 고정한 상태에서도 다른 데이터들에 대해 일반화를 잘하는지 테스트해 보았다.
이 실험은 비디오와 오디오 modality에 초점을 맞추었고, 백본을 freeze한 상태에서 선형 분류기만 fine-tuning한다.
또한, Low-rank classifier에 더해서 SVM 결과를 테스트해보았다.
그 결과 VATT는 MMV에서 사용한 최고 성능의 CNN기반 모델보다 좋은 성능을 내지 못했지만, 다른 베이스라인 모델과는 비견할 만한 성능을 보였다. 이 결과로 미루어볼 때, VATT의 백본은 선형적으로 분리 가능한 feature을 덜 학습한 것으로 보인다. 특히 contrastive estimation head가 비선형적인 projection을 사용할 때 이런 결과는 확연했다.

4.4.6 Feature visualization
▲ 영상 인풋에 대한 representation이 클래스에 따라 잘 분리되었다.
Kinetics-400 데이터에 대해 fine-tuning된 modality-specific 모델과 modality-agnostic 모델을 사용하여 그 결과로 나오는 feature representation을 t-SNE를 사용해 시각화해 보았다. 결과 비교를 위해 vision Transformer을 Kinetics-400 데이터에 대해 from-scratch로 학습한 모델의 시각화 결과도 보았다.

- (b)~(c) : Fine-tuning된 VATT 모델이 from scratch로 학습한 모델보다 더 좋은 분리 형태를 보인다
- 영상 모드에 최적화된 모델(b)과 modality에 무관하게 학습된 모델(c)의 representation 차이에 큰 차이가 없다
▲ modality-agnostic 모델은 영상과 텍스트의 신호를 비슷한 concept로 매핑한다.
더불어 VATT 백본을 fine-tuning 없이 조사해보았다.
YouCook2의 영상 중 1000개의 영상을 랜덤 추출하고, VATT 모델이 추출한 representation 두 가지를 저장해보았다.
(1) tokenization layer을 거친 직후의 feature (Transformer의 인풋 스페이스)
(2) common space projection 이후의 feature (아웃풋 스페이스) -> 이 결과로 loss를 계산하게 됨

- modality agnostic 세팅에서는 modality specific한 모델에 비해 representation이 더 섞여 있다 : 즉, modality agnostic 모델은 다른 modality에서 온 다른 신호(symbol)를 같은 개념(concept)을 묘사하는 것으로 받아들인다는 것이다. 이 결과는 NLP에서 하나의 언어 모델이 여러 개의 언어를 처리할 수 있는 것과 같은 현상으로 해석된다.
VATT가 알맞게 짝지어진 <비디오-텍스트> 쌍과 랜덤하게 짝지어진 쌍을 잘 구분하는지 보기 위해 모든 가능한 조합에 대해 pairwise 유사도를 계산하고, Kernel Density Estimation(KDE)을 통해 positive vs negative pair 간의 유사도 분포를 시각화했다.

- modality-specific, 그리고 modality-agnostic 모델 모두 아웃풋 공간에서 positive와 negative 쌍을 잘 구분하는 것으로 나타났고, 이는 다른 modality에 있어 의미적인(semantic) common space를 학습할 수 있다는 것을 보여준다.
4.5 Ablation study
4.5.1 Inputs
VATT는 raw multimodal signal을 인풋으로 받기 때문에 인풋 크기와 패치가 성능에 큰 영향을 줄 수 있다.
이 부분을 조사하기 위해 먼저 비디오에서 샘플링한 프레임의 개수와 크롭 사이즈를 변경하되, 패치 크기는 5x16x16으로 유지해 실험해보았다. 그 결과, 크롭 사이즈를 작게 하거나 프레임 수를 크게 하면 영상 관련 태스크 성능 저하를 가져왔으나, 오디오 분류에는 영향이 크게 없는 것으로 나타났다.

위 실험에서 가장 좋게 나온 프레임 크기를 유지한 채, 비디오 패치 크기를 변경해보았다. 시간, 혹은 공간 차원에 있어 4x16x16을 넘어가는 패치를 사용하는 것은 성능에 있어 좋지 않았다. 이 패치 크기보다 작게 할 경우, 실험 시간이 너무 오래 걸리기 때문에 그런 실험은 하지 않았다.

마지막으로 오디오 패치 크기가 성능에 미치는 영향에 대해 실험하였다. 그 결과, 패치 크기는 128을 사용하는 것이 가장 좋았다.

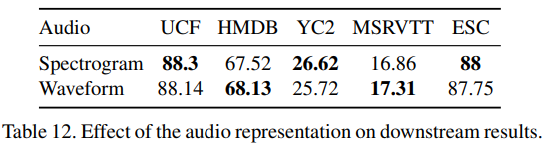
또한 raw waveform 대신 handcrafted spectogram을 인풋으로 사용하는 실험을 진행해보았다. (MEL spectrogram with 80 bins, the STFT length of 42 ms, and the STFT step of 21 -> 이는 MMV 모델 셋팅을 참고한 결과) 그 결과, Spectogram을 사용한다고 해서 성능이 유의미하게 향상되지는 않았다. 이 결과로 미루어볼 때, VATT는 raw audio로부터 semantic representation을 학습할 능력이 있는 것으로 보인다.
4.5.2 DropToken
DropToken에 사용하는 drop rate를 바꾸어가며 실험을 진행해보았다. 50%의 토큰을 drop하는 결과는, 이와 같이 라지 스케일로 사전학습을 진행함에 있어 GFLOPs와 성능 사이의 trade-off 측면에서 적정 수준인 것을 알 수 있었다.
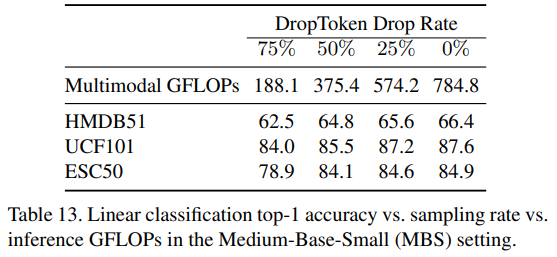
또한, 50% DropToken을 적용한 VATT의 마지막 체크포인트를 사용해 Kinetics-400 데이터에 대해 각기 다른 DropToken 비율을 사용해 실험을 진행해 보았다. 이 실험은 높은 해상도를 가지는 인풋에 DropToken을 적용한 것과, 낮은 해상도를 가지지만 DropToken을 하지 않은 것에 대해 fine-tuning 과정에서 어떤 차이가 있는지 보기 위함이다. 일반적으로 학습 과정에서 계산 비용을 줄이기 위해서는 후자의 방법, 즉 저해상도의 인풋을 사용하는 방법을 선택한다. 하지만 이 실험 결과는 고해상도의 인풋을 그대로 사용하면서 DropToken을 사용하는 전자의 방법이 성능과 학습 비용 측면에서 비견할만하거나 좋다는 것을 제시한다.
5. Conclusion
- 트랜스포머 아키텍처를 사용해 self-supervised multimodal representation learning을 수행하는 프레임워크를 제안함
- 순수히 어텐션만을 사용한 모델을 multimodal 영상 인풋에 대해 학습을 시켰고, 이러한 라지 스케일의 자기 지도 학습 기반 사전학습법이 트랜스포머 기반의 모델을 학습함에 있어 데이터 확보에 대한 부담을 덜어줄 수 있다는 가능성을 제시함.
- DropToken 방식을 사용해 트랜스포머가 가지는 quadratic training complexity 문제를 완화함.
- video action recognition와 audio event classification에 있어 SOTA 성능을 달성하였고, 이미지 분류와 video retrieval에서도 기존 연구에 비견할만한 성능을 보여 SSL을 통해 학습한 representation을 각기 다른 modality에 대해 일반화, 전이 가능함을 보임.
- 향후 학습에 있어 data augmentation 기법을 좀 더 탐색하고, modality agnostic 백본에 대해 모델을 적절하게 regularize할 수 있는 방법을 연구할 계획
