자바스크립트로 ML 모델을 개발하고 브라우저 혹은 Node.js에서 실행할 수 있는 TensorFlow.js을 활용하여 실시간으로 사람의 자세를 추정하는 human pose estimation을 구현할 수 있습니다.
참고 자료 : https://blog.tensorflow.org/2018/05/real-time-human-pose-estimation-in.html
구글 라이브 데모 >> https://storage.googleapis.com/tfjs-models/demos/posenet/camera.html
PoseNet
- PoseNet은 MobileNet 혹은 ResNet 기반의 human pose estimation 네트워크이다.
- TensorFlow.js에서 실행할 수 있기 때문에
a) 웹캠 혹은 핸드폰 카메라 기반으로 어플리케이션 실행이 가능하다
b) 자바 스크립트로 코딩할 수 있다
c) 브라우저 상에서 실행되고, 데이터가 남지 않기 때문에 개인정보 이슈에서 비교적 자유롭다.
Pose Estimation 이란
- 이미지 혹은 영상으로부터 사람 형상을 찾아내고, 주요 관절의 위치 등을 찾아내는 컴퓨터 비전 기술을 의미
- "누가" 영상에 있는지 개인정보를 식별하는 것이 아니라 관절 위치를 찾아내는 것이 키 포인트
PoseNet에서는 RGB 이미지를 인풋으로 받아 CNN 아키텍처를 거쳐 다음의 아웃풋을 반환한다 :
● pose (pose object) : keypoint의 리스트 & 인스턴스 레벨의 스코어
● pose confidence score : pose에 대한 전반적인 점수 (0-1 사이의 값)
→ 불확실하게 추론한 포즈는 숨기는 용도로 사용할 수 있음
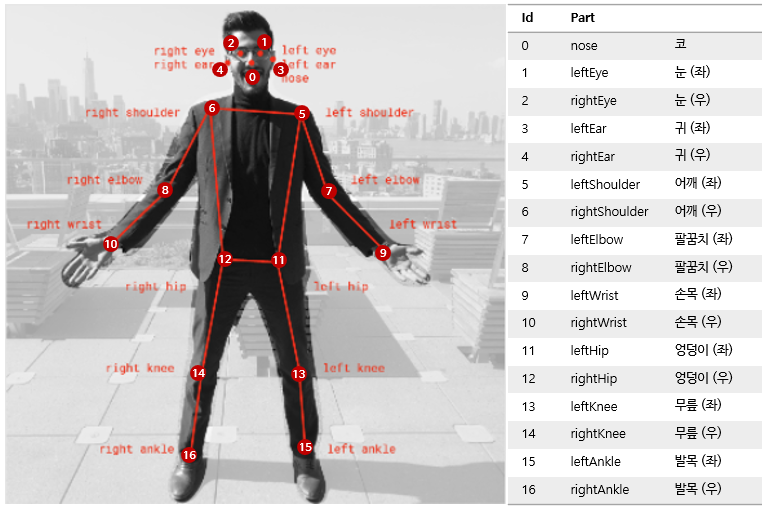
● keypoint : pose를 구성하는 17개의 핵심 관절들. position과 confidence score을 포함
● keypoint confidence score : 추정한 keypoint의 위치가 정확한지에 대한 점소 (0-1 사이의 값)
● keypoint position : 인풋 이미지 스케일에서 keypoint에 대한 (x,y) 좌표
TensorFlow.js에서 PoseNet 사용하는 방법
[1] TensorFlow.js & PoseNet 라이브러리 불러오기
npm으로 라이브러리를 설치한 후 es6 모듈을 사용하거나 페이지의 bundle로 불러올 수 있다.
npm install @tensorflow-models/posenet
- es6 모듈로 불러오기 :
import * as posenet from '@tensorflow-models/posenet';
const net = await posenet.load();
- bundle in page :
<html>
<body>
<!-- Load TensorFlow.js -->
<script src="https://unpkg.com/@tensorflow/tfjs"></script>
<!-- Load Posenet -->
<script src="https://unpkg.com/@tensorflow-models/posenet">
</script>
<script type="text/javascript">
posenet.load().then(function(net) {
// posenet model loaded
});
</script>
</body>
</html>
[2] Single-Person Pose Estimation
const imageScaleFactor = 0.50;
const flipHorizontal = false;
const outputStride = 16;
const imageElement = document.getElementById('cat');
// load the posenet model
const net = await posenet.load();
const pose = await net.estimateSinglePose(imageElement, scaleFactor, flipHorizontal, outputStride);
▨ Inputs
- input image : 이미지 혹은 영상 , 반드시 square 형태로 넣어야 한다
- image scale factor (0.2 - 1 사이의 값, default = 0.5) : 이미지 크기를 얼마나 scale down할지 결정 (추론 속도 향상)
- flip horizontal (default = False) : WebCam 등으로 이미지가 반전되어서 들어올 경우, True로 설정해야 함
- output stride (32/16/8 default = 16) : 네트워크 레이어의 height / width를 결정해 아웃풋 정확도와 속도에 영향
-> 작은 값으로 설정 시 정확도는 올라가지만 추론 속도가 느려짐
-> 큰 값으로 설정 시 정확도는 떨어지지만 추론 속도가 빨라짐
▨ Outputs
- pose confidence score & 17 keypoint의 array
- 각각의 keypoint는 keypoint position & keypoint confidence score을 포함함
아웃풋 json 예시 :
{
"score": 0.32371445304906,
"keypoints": [
{ // nose
"position": {
"x": 301.42237830162,
"y": 177.69162777066
},
"score": 0.99799561500549
},
{ // left eye
"position": {
"x": 326.05302262306,
"y": 122.9596464932
},
"score": 0.99766051769257
},
{ // right eye
"position": {
"x": 258.72196650505,
"y": 127.51624706388
},
"score": 0.99926537275314
},
...
]
}
Single Person Pose Estimation 예시 >>


'AI' 카테고리의 다른 글
| Topic Segmentation 서베이 (2) | 유사도 기반의 클러스트링 - Dot Plotting (0) | 2021.10.10 |
|---|---|
| Topic Segmentation 서베이 (1) | Lexical Similarity 기반 기법 - TextTiling in Python (0) | 2021.10.05 |
| [논문리뷰] VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text (1) | 2021.06.25 |
| 한국어 언어모델: Korean Pre-trained Language Models (2) | 2021.05.16 |
| [딥러닝 시리즈] ③ Loss 함수 설계하기 (2) (0) | 2021.05.16 |



