키워드 기반의 랭킹 알고리즘 - BM25
BM25(a.k.a Okapi BM25)는 주어진 쿼리에 대해 문서와의 연관성을 평가하는 랭킹 함수로 사용되는 알고리즘으로, TF-IDF 계열의 검색 알고리즘 중 SOTA 인 것으로 알려져 있다. IR 서비스를 제공하는 대표적인 기업인 엘라스틱서치에서도 ElasticSearch 5.0서부터 기본(default) 유사도 알고리즘으로 BM25 알고리즘을 채택하였다.
BM25 step by step 살펴보기
BM25는 Bag-of-words 개념을 사용하여 쿼리에 있는 용어가 각각의 문서에 얼마나 자주 등장하는지를 평가한다.
키워드 q1,..., q_n을 포함하는 쿼리 Q가 주어질 때 문서 D에 대한 BM25 점수는 다음과 같이 구한다.

식은 복잡해 보이지만, 요소 하나하나를 뜯어보면 이 알고리즘은 상당히 직관적이다.
q_i : 쿼리에서 i번째 토큰 (형태소 / bi-gram /BPE 등을 사용할 수 있음)
IDF(q_i) : 쿼리의 i번째 토큰에 대한 inverse document frequency
- 자주 등장하는 단어는 penalize 하여 지나치게 높은 가중치를 가지게 되는 것을 방지함.
- 예를 들어 "the"라는 단어는 영어 문서에서 아주 자주 등장하는 단어이기 때문에 쿼리에 있는 the라는 글자가 문서에 자주 나타났다고 해서 의미 있는 것이 아님.
- 루씬(Lucene)에서는 다음과 같은 식으로 IDF를 계산함:

- 예를 들어 총 10개의 문서가 있을 때 10개의 문서에서 모두 등장하는 단어(the 등)는 IDF값이 0.05, 한 번만 등장하는 단어는 1.99의 값을 가짐.
- BM25 스코어링 식에서 IDF값이 곱해진다는 것은 자주 등장하지 않는 단어에 더 큰 가중치를 둔다는 것을 의미함.
|D|/avgdl : 문서의 길이에 대한 부분
- 해당 문서가 평균적인 문서 길이에 비해 얼마나 긴지를 고려함.
- 이 항은 점수 계산에 있어 분모에 있기 때문에, 평균 대비 긴 문서는 penalize됨.
- 열 페이지가 넘는 문서에서 어떤 단어가 한 번 언급되는 것과, 트위터같은 짧은 문장에서 단어가 한 번 언급되는 것 중에서는 두 번째 경우가 더 의미 있다고 보는 것.
b : 일반적으로 0.75 사용
- b가 커지면 문서의 길이가 평균 대비 문서의 길이에 대한 항의 중요도가 커짐.
- b가 0에 가까워지면 문서의 길이에 대한 부분은 무시됨.
f(q_i, D) : 쿼리의 i번째 토큰이 문서 D에 얼마나 자주 나타나는가 (Term Frequency)
- 쿼리에 있는 키워드가 문서에 자주 나타나면 점수가 높아짐
k1 : TF의 saturation을 결정하는 요소 (1.2~2.0의 값을 사용하는 것이 일반적)
- 하나의 쿼리 토큰이 문서 점수에 줄 수 있는 영향을 제한함.
- 직관적으로 k1은 어떤 토큰이 한 번 더 등장했을 때, 이전까지에 비해 점수를 얼마나 더 높여주어야 하는가를 결정함.
- 어떤 토큰의 TF가 k1보다 작거나 같으면 TF가 점수에 주는 영향이 빠르게 증가하는데, k1번 등장하기 전 까지는 해당 키워드가 문서에 더 등장하게 되면 문서의 BM25 스코어를 빠르게 증가시킨다는 뜻임.
- 반대로 토큰의 TF가 k1보다 크면 TF가 점수에 주는 영향이 천천히 증가하고, 해당 키워드가 더 많이 등장해도 스코어에 주는 영향이 크지 않음.
- k1의 존재로 인해 BM25에서 term frequency는 어느정도 이상부터는 점수에 주는 영향이 거의 증가하지 않음.
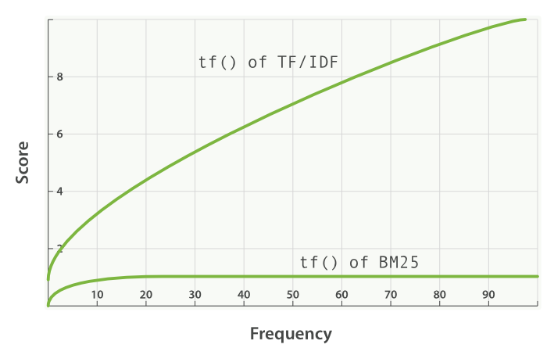
- Elastic Search에서는 k1=1.2로 설정되어 있음.
파이썬에서 BM25 사용하기
** 참고문서: https://pypi.org/project/rank-bm25/
rank-bm25 패키지를 설치하면 Okapi BM25와 더불어 변형된 알고리즘인 BM25L, BM25+를 사용할 수 있다.
설치 방법: pip 설치
pip install rank_bm25
패키지를 설치하고 나면 대상 코퍼스들에 대해 BM25 클래스를 인스턴스화하여 인덱싱을 수행한다.
from rank_bm25 import BM25Okapi
corpus = [
"세계 배달 피자 리더 도미노피자가 우리 고구마를 활용한 신메뉴를 출시한다.도미노피자는 오는 2월 1일 국내산 고구마와 4가지 치즈가 어우러진 신메뉴 `우리 고구마 피자`를 출시하고 전 매장에서 판매를 시작한다. 이번에 도미노피자가 내놓은 신메뉴 `우리 고구마 피자`는 까다롭게 엄선한 국내산 고구마를 무스와 큐브 형태로 듬뿍 올리고, 모차렐라, 카망베르, 체더 치즈와 리코타 치즈 소스 등 4가지 치즈와 와규 크럼블을 더한 프리미엄 고구마 피자다.",
"피자의 발상지이자 원조라고 할 수 있는 남부의 나폴리식 피자(Pizza Napolitana)는 재료 본연의 맛에 집중하여 뛰어난 식감을 자랑한다. 대표적인 나폴리 피자로는 피자 마리나라(Pizza Marinara)와 피자 마르게리타(Pizza Margherita)가 있다.",
"도미노피자가 삼일절을 맞아 '방문포장 1+1' 이벤트를 진행한다. 이번 이벤트는 도미노피자 102개 매장에서 3월 1일 단 하루 동안 방문포장 온라인, 오프라인 주문 시 피자 1판을 더 증정하는 이벤트다. 온라인 주문 시 장바구니에 2판을 담은 후 할인 적용이 가능하며, 동일 가격 또는 낮은 가격의 피자를 고객이 선택하면 무료로 증정한다."
]
def tokenizer(sent):
return sent.split(" ")
tokenized_corpus = [tokenizer(doc) for doc in corpus]
bm25 = BM25Okapi(tokenized_corpus)
위 예제에서는 간단하게 띄어쓰기 단위로 문서를 파싱하여 BM25 클래스를 인스턴스화하였다. 한국어의 경우 결합어적인 특성상 위와 같은 띄어쓰기 단위보다는 형태소 단위로 분석하는 것이 더 좋을 수 있다. 또한 rank_bm25 라이브러리에서는 텍스트 정규화(소문자화, 불용어 제거 등) 기능을 제공하지 않기 때문에 필요한 경우 텍스트 전처리를 한 후 인덱싱을 하는 것이 검색 성능을 높이는 데에 필수적이다.
인덱싱된 결과를 살펴보면 BM25 점수 계산에 필요한 항들이 들어 있는 것을 볼 수 있다.
doc_len : 파싱된 문서의 길이
bm25.doc_len 
doc_freqs : 문서에 있는 각각의 토큰의 빈도 (각 문서 내에서 딕셔너리 형태로 저장)
bm25.doc_freqs 
idf : 토큰의 inverse term frequency를 계산해둠
bm25.idf
이제 쿼리가 들어오면 토큰화를 진행하고 bm25 클래스의 get_scores 메서드를 통해 문서 점수를 받아올 수 있다.
query = "도미노피자 신메뉴"
tokenized_query = tokenizer(query)
doc_scores = bm25.get_scores(tokenized_query)
doc_scores
get_top_n 메서드는 점수에 따른 상위 n개의 문서를 바로 리턴해주기 때문에 유용하게 활용할 수 있다.
bm25.get_top_n(tokenized_query, corpus, n=1)
(참고) 엘라스틱서치
엘라스틱서치의 similarity 모듈에서는 기본 설정인 BM25 이외에 다양한 문서 스코어링/ 랭킹 모듈을 제공하고 있음.
- BM25 similarity (default) : 이름 등 짧은 필드에 대해서 잘 작동하는 것으로 알려짐
- DFR similarity : divergence from randomness 프레임워크에 따른 유사도 측정
- DFI similarity : divergence from independence 모델에 기반함. 이 척도를 사용할 경우 반드시 불용어를 제거해야 하고, 기대 빈도보다 적은 빈도수는 모두 0으로 점수 매겨짐에 유의
- IB similarity : Information 기반의 모델
- ...
기타 모듈들은 ES 가이드 참고: https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-similarity.html
Similarity module | Elasticsearch Reference [7.6] | Elastic
While scripted similarities provide a lot of flexibility, there is a set of rules that they need to satisfy. Failing to do so could make Elasticsearch silently return wrong top hits or fail with internal errors at search time:
www.elastic.co

'Others > Coding' 카테고리의 다른 글
| [TopCoder 알고리즘] 시뮬레이션 - 키위주스 (0) | 2022.03.31 |
|---|---|
| [2021 Hackathon] 2. Modeling (0) | 2021.01.31 |
| [2021 Hackathon] 1. Data Preprocessing (1) | 2021.01.29 |
| 라빈 카프 알고리즘(Rabin-Karp Algorithm) : 해싱을 통해 효율적으로 문자열 검색하기 / 해싱 / 해시함수 (0) | 2020.03.01 |
| [Python] 힙 자료구조 / 힙큐(heapq) / 파이썬에서 heapq 모듈 사용하기 (4) | 2020.02.23 |