HiPlot이란?
- 고차원 상의 공간에서 상관관계와 패턴을 찾아낼 수 있도록 도와주는 대화형 시각화 툴
- 평행 좌표 플롯(parallel plot)을 비롯한 시각화 방법들을 이용해 정보를 명확하게 표현함
- 셋업 과정 없이 주피터 노트북에서 빠르게 실행할 수 있음
하이플롯은 하이퍼파라메터(hyper-parameter, 학습률, 정규화 등)가 미치는 영향을 쉽게 평가할 수 있도록 한다.
뿐만 아니라 데이터와 관련된 다양한 분야에서 데이터상에 존재하는 상관관계를 조사할 수 있도록 도와준다.
Parallel Coordinate Plots
- 다변량 데이터를 분석하고 시각화할 때 자주 사용하는 방법
- n차원의 공간을 n개의 수직 평행선으로 표현하고, 각각의 데이터 포인트를 폴리 라인으로 이어 나타냄
- 아래 예시는 피셔의 붓꽃 데이터에서 3가지 종류의 붓꽃과 네 가지 변수의 상관관계를 시각화한 평행 좌표 플롯.
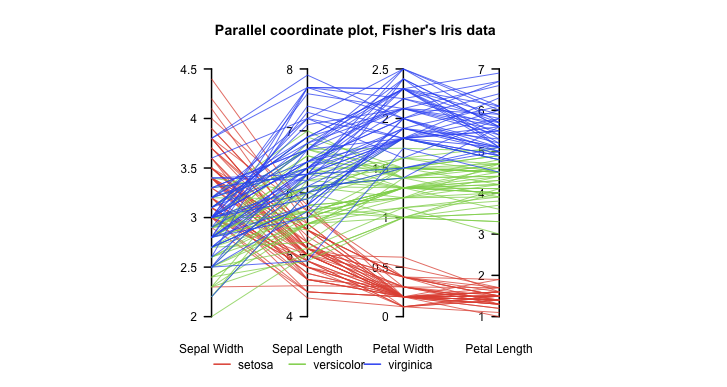
▲ 붓꽃의 종류를 빨강, 초록, 파랑의 구분된 선으로 표현하고, 각각의 데이터포인트를 4가지 변수 축에 대해 이었다.
그 결과 setosa는 꽃받침(Sepal)의 넓이는 크지만 꽃받침의 길이가 짧고 꽃잎(Petal)의 너비 및 길이도 짧은 반면,
virginica는 꽃받침 너비가 작으면서 길이는 길고, 꽃잎의 넓이과 길이가 크다는 관계를 한 눈에 파악할 수 있다
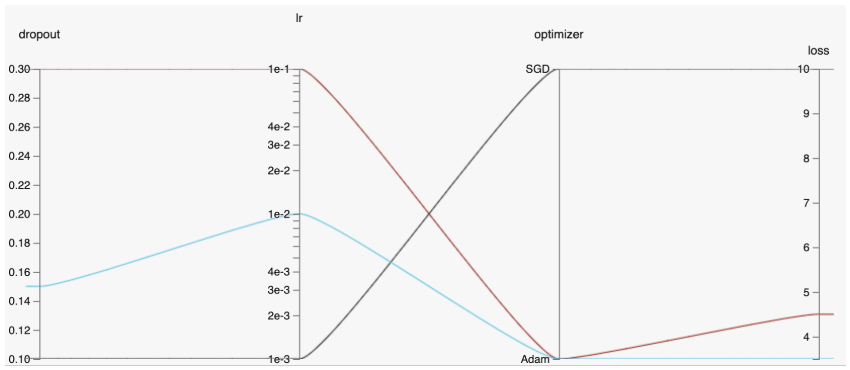
평행 좌표 플롯을 이용해 딥러닝에 설정해야 하는 하이퍼파라메터와 학습 성능과의 관계를 시각화하는 데에 활용할 수 있다. 예를 들어 드롭아웃과 학습률, 옵티마이져(SGD or Adam)를 다르게 설정하여 여러 개의 학습을 동시에 진행하는 상황을 생각해보자. 하이플랏에서는 각기 다른 설정값에 따른 학습 결과를 아래와 같은 평행 좌표 플롯으로 도식화하여 보여준다. 드롭아웃과 학습률, 그리고 loss는 스칼라 값이기 때문에 연속된 스케일로 표시되어있고, 범주형 선택지인 옵티마이저는 3번째 축에 binary화 되어 표현되어 있다. 세 번의 훈련 결과 SGD를 사용한 학습 결과가 Adam에 비해 좋지 않았고, 상대적으로 작은 드롭아웃과 학습률을 설정한 하늘색 학습 결과가 loss가 가장 작게 나타난 것을 볼 수 있다.
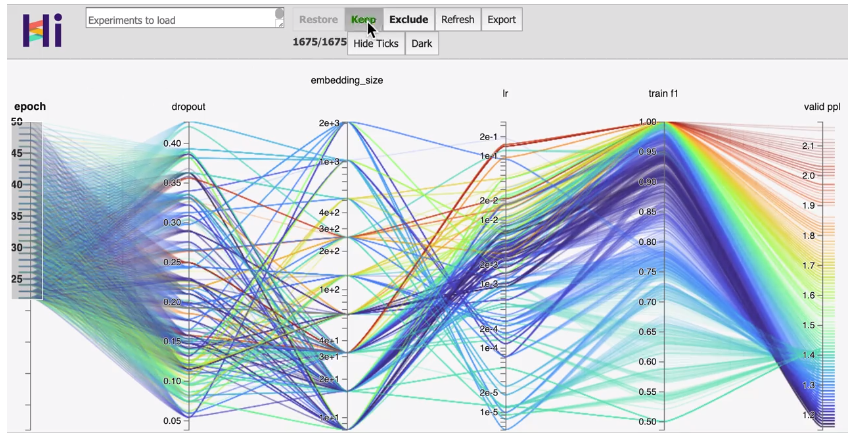
특징 및 장점
Interactivity (대화식) : 시각화의 범위를 쉽게 바꿀 수 있음
- 특정 축(epoch, 드롭아웃 등)에서 일정 범위의 값에 대해서만 관심이 있는 경우 드래그를 통해 범위 조정
- 특정 축의 값에 대해 색깔 변화 적용
- 데이터에서 특정 축이나 특정 범주의 데이터를 제거하고 시각화
Simplicity (간결함) : 두 가지 직관적인 방법으로 HiPlot 실행 가능
- 주피터 노트북에서 실행하기: data에 대해 아래와 같은 명령어를 실행시키면 바로 실행
import hiplot as hip
data = [{'dropout':0.1, 'lr': 0.001, 'loss': 10.0, 'optimizer': 'SGD'},
{'dropout':0.15, 'lr': 0.01, 'loss': 3.5, 'optimizer': 'Adam'},
{'dropout':0.3, 'lr': 0.1, 'loss': 4.5, 'optimizer': 'Adam'}]
hip.Experiment.from_iterable(data).display(force_full_width=True)- 서버에서 실행하기: hiplot 명령어로 실행한 후 http://127.0.0.1:5005/에 접속하여 결과를 시각화, 관리, 공유.
Extendability (확장성)
- 기본적으로 HiPlot의 웹 서버는 CSV나 JSON 파일을 지원함
- 필요하다면 커스터마이징한 Python 파서를 이용해 실험 결과를 HiPlot으로 변경할 수 있음
- 또한 하이퍼파라메터 탐색을 돕기 위해 현존하는 페이스북 AI 라이브러리(wav2letter@anywhere, Nevergrad, fairseq 등)와의 호환성을 지원함
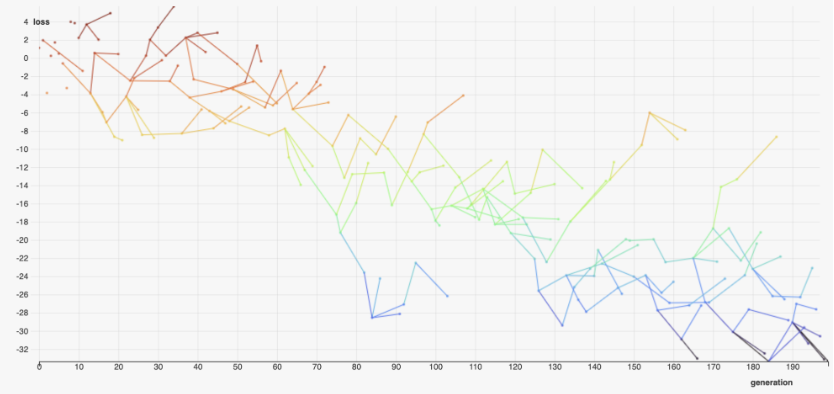
Visualization for Population-Based Training (모수 기반의 훈련을 위한 시각화)
- 현재의 하이퍼파라메터 튜닝은 Population-Based Training 등의 유전 알고리즘을 포함함
- 이런 실험은 분석하기가 까다로운데, 버그가 존재할 수도 있으나 찾아내기가 어렵기 때문
- HiPlot에서는 이런 실험도 XY플롯을 통해 시각화하여 관계 있는 데이터 사이의 엣지를 만들어 보여줌
c.f.) Population-Based Training:
최적의 설정을 빠르게 찾기 위해 네트워크의 시리즈를 동시에 훈련하고 최적화하는 방법. 랜덤하게 설정된 하이퍼파라메터를 사용해 병렬적으로 네트워크를 훈련을 시작하되, population에 존재하는 정보를 활용하여 가능성 있는 모델을 만들 수 있는 방향으로 하이퍼파라메터를 조정해 나감. 이는 유전 알고리즘에서 모티브를 따온 방법으로, 모수(population) 집단의 한 워커(worker)는 나머지 모수로부터 정보를 착취(exploit)하여 사용할 수 있음. 예를 들어 잘 작동하고 있는 다른 워커의 모델 파라메터를 복사하는 식. 반면, 현재 값을 랜덤 하게 바꾸는 식으로 새로운 하이퍼파라메터를 탐색(explore)하여 성능을 높이기도 함.
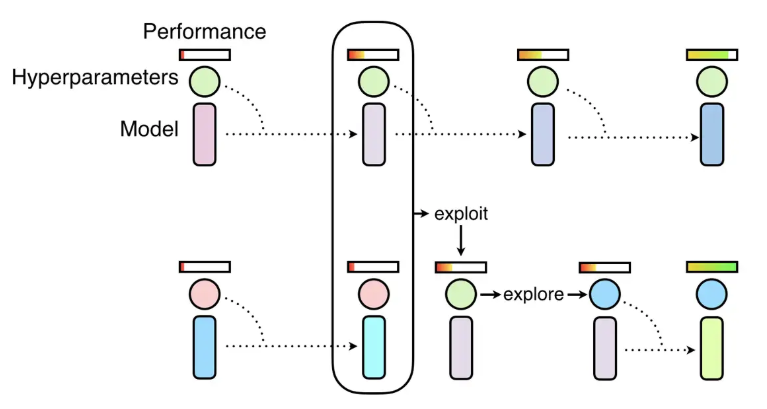
Facebook의 HiPlot에서는 이러한 유전 알고리즘적인 PBT에서 탐색이 진행되어가는 과정을 도식화해서 보여준다.
** 출처: https://ai.facebook.com/blog/hiplot-high-dimensional-interactive-plots-made-easy/
HiPlot: High-dimensional interactive plots made easy
We are releasing HiPlot, a lightweight interactive visualization tool to help AI researchers discover correlations and patterns in high-dimensional data.
ai.facebook.com

'AI' 카테고리의 다른 글
| AutoML-Zero: 'zero' 에서부터 스스로 진화하는 기계학습 알고리즘 (1) (0) | 2020.03.13 |
|---|---|
| Graph Convolutional Networks (GCN) 개념 / 정리 (7) | 2020.03.11 |
| Graph Neural Networks (GNN) / 그래프 뉴럴 네트워크 기초 개념 정리 (2) | 2020.03.10 |
| Explainable AI : 설명 가능한 인공지능 / XAI / DARPA / Google XAI / What-if 툴 (0) | 2020.02.23 |
| 자연어 생성에서의 Beam Search / 파이썬으로 Beam Search 구현하기 (3) | 2020.02.23 |



