왜 설명 가능한 AI인가
AI는 이제 전 세계적인 생산성을 높이고 일하는 방식과 생활 패턴을 바꾸는 등 우리의 삶 안으로 들어왔다. 자율주행차와 지능형 RPA는 우리의 삶을 자동화하는 방식으로 생활 반경 안에 들어왔고, 의료 진단, 헬스케어, 공정 자동화, 마케팅 등에 활용되는 인공지능 기술은 산업의 방식을 바꾸는 Digital Transformation을 이룩하게 되었다. 이에 따라 가트너는 2022년까지 AI로 인해 창출되는 경제 가치는 3.9조 달러에 이를 것이라 전망했다.
이러한 AI 시장 성장의 배경에는 딥러닝 기술이 기존 머신러닝 방법론들에 비해 탁월한 성능을 보인다는 점이 있다. 이미지 분야에서의 분류 모델의 정확도는 사람 성능을 넘어서 완벽에 가까워졌고, 자연어처리 분야의 태스크들에서 역시 인간의 능력을 상회하는 모델들이 발표되었다.
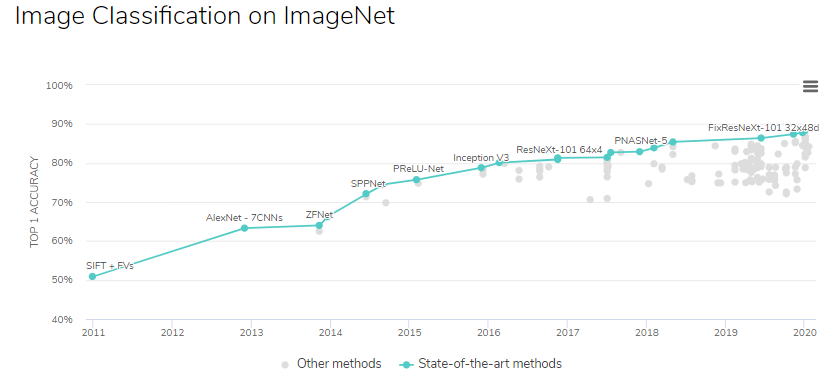
그러나 현재의 딥러닝 모델은 높은 성능을 내는 대가로 설명력을 포기해야 했다. 딥러닝 모델들은 수백만개의 파라메터가 고차원적이고 복잡한 비선형의 속성(representation)을 사용해 예측 결과를 내는 black-box 모델로, 모델이 결론에 이르게 된 경로를 추적하기가 어렵다.

이러한 딥러닝의 블랙박스적인 측면은 인공지능을 산업에 적용하기 위해 반드시 풀어야 할 문제이다.
예를 들어 딥러닝을 CRM, 이탈 방지, 마케팅등의 경영 의사 결정에 활용할 때에는 모델이 결론에 다다르게 된 증거를 제시할 필요가 있다. 대부분의 기관에서 직관적으로 설명되지 않는 모델의 결과는 절대 채택되지 않기 때문이다. 의료 진단과 같이 100%의 정확도가 요구되는 분야에서는 어떤 경우에 모델을 신뢰할 수 있을지 판단하여 애매한 경우 반드시 전문가가 검토할 수 있도록 하는 시스템이 필요하고, 자율주행 분야에서 역시 사고에 대비한 윤리적인 문제 등으로 설명 가능한 인공지능에 대한 니즈가 높아지고 있다.
따라서 향후 설명 가능한 인공지능, XAI는 다음의 다섯 가지 질문에 답할 수 있어야 한다.
- 모델이 왜 그런 결정을 내렸는가
- 왜 다른 결정은 내리지 않았는가
- 모델은 어떤 경우에 예측하고 어떤 경우에 실패하는가
- 어떤 경우에 모델을 신뢰할 수 있는가
- 어떻게 모델의 오류를 수정할 수 있는가 (Debugging)
이에 XAI는 AI 시스템이 다음과 같이 작동할 수 있을 것을 목표로 한다.
- 인간의 가독성(readability)를 증진시킨다
- 기계가 내린 결정이 납득 가능한지 결정할 수 있도록 한다
- 결정에 대한 책임을 명확히 하여 좋은 의사결정을 내릴 수 있도록 한다
- 차별을 피한다
- 사회적 편향(bias)을 줄인다
** 참고 자료:
https://www.darpa.mil/program/explainable-artificial-intelligence
https://towardsdatascience.com/googles-new-explainable-ai-xai-service-83a7bc823773
DARPA XAI
미국 국방성(U.S. Department of Defence)에서는 보다 똑똑하고 자동화된 시스템을 구축하기 위해 XAI 연구에 투자하고 있다. DARPA의 XAI 프로그램에서는 다음을 만족하는 머신러닝 기술을 개발하는 것을 목표로 한다.
- 설명 가능한 모델을 개발하면서 높은 성능을 유지한다.
- 인간 사용자가 AI 파트너들을 이해하고, 적절하게 신뢰하며 효율적으로 관리할 수 있다.

2018년 5월까지 진행된 Phase 1 평가에서는 연구자들이 개발한 설명 가능한 학습 시스템(explainable learning systems)에 대한 파일럿 평가를 마쳤고, 같은 해 11월에는 전체 Phase 1 평가를 한 상태이다. 이 프로그램이 종료되는 시점에는 최종적으로 미랴의 설명 가능한 AI 시스템을 개발할 수 있는 머신러닝 툴킷과 사람-컴퓨터 인터페이스 소프트웨어 모듈을 발표하는 것을 목표로 하고 있다.
Google XAI
Google Cloud XAI service
** 이 부분의 내용은 다음의 페이지의 내용을 번역 / 요약하여 작성함 : https://cloud.google.com/ai-platform/prediction/docs/ai-explanations/overview
구글 클라우드의 AutoML 서비스에서는 데이터에 있는 특성들이 모델 아웃풋 예측에 얼마나 기여했는지 시각화하는 서비스를 제공한다. 현재는 테이블 데이터에 대한 회귀/ 분류 문제와 이미지 데이터 분류 문제에 대한 설명력을 제공하고 있다.
예를 들어 자전거 타는 시간을 예측하는 DNN 모델에 대해 explanations를 요청하면, 아래와 같이 datapoint의 설명변수들이 베이스라인 값 대비 예측 결과에 얼마나 영향을 미쳤는지를 보여준다. 예를 들어 아래 데이터에서는 모델이 11분간 자전거를 탈 것이라고 예측했고, (실제값=10분) 그렇게 결정한 요인에는 최고 기온(max_temp)의 기여가 가장 높았던 것으로 나타났다.

이미지 분류 문제에서 역시 explanation을 요구하면, 모델이 이미지를 해당 클래스로 예측할 때 집중한 이미지의 픽셀을 시각화하여 나타내 준다.

이러한 모델의 explainability는 모델 디버깅과 모델 최적화에 활용할 수 있다. 예를 들어 흉부 X-ray를 통한 폐암 진단 모델이 테스트 데이터에서 의심스럽게 좋은 성능을 낸 이유가 의사가 미리 표시해 둔 펜 자국 때문이었음을 알아내 모델을 디버깅하는데 사용할 수 있고, 중요하지 않는 변수를 제거해 더 효율적인 모델을 만드는 데에 사용할 수 있다.
하지만 Google Cloud의 XAI 서비스는 아래와 같은 세 가지 한계점에 대해 경고한다.
- 예측에 대한 변수의 기여도는 각각의 예제에 한정된다. 물론 각각의 예제에 대한 기여도를 찾는 것도 좋은 통찰력을 제공할 수 있지만, 이 통찰력은 모델 전체에 대한 것으로 일반화할 수는 없다.
- 변수 기여도는 모델 디버깅에 도움이 될 수는 있지만, 문제점이 모델에서 비롯된 것인지 혹은 데이터에서 비롯된 것인지를 항상 명확하게 알려주지는 않는다.
- 복잡한 모델로부터 얻어낸 변수 기여도는 adversarial 공격에 대해 주관적일 수 있다.
What-if Tool
https://www.youtube.com/watch?v=qTUUwfG1vSs&feature=youtu.be&autoplay=1
구글의 What-if 툴은 데이터셋과 머신러닝 모델의 아웃풋을 이해할 수 있도록 도와주는 비주얼 인터페이스이다. 주피터 노트북, 텐서보드, 클라우드 AI 플랫폼 등을 이용하여 최소한의 코딩만으로도 설명 가능한 AI를 구현할 수 있도록 도와준다. 텐서플로우뿐만 아니라 다른 프레임워크로 구축한 모델에 대해서도 사용할 수 있다.

이 툴에서는 세 가지 시각화 탭을 제공한다.
- Datapoint editor : 데이터에 대한 시각화를 제공하는 탭. Classification 데이터의 경우 X축과 Y축에 설명 변수를, 색깔로 데이터의 클래스를 표현하여 3차원으로 데이터를 시각화하여 보여준다.
- Performance & Fairness : 모델 성능에 대한 ROC curve, PR curve, Confusion matrix 등 자세한 진단 수치들을 시각화하여 보여준다.
- Features : 데이터셋이 편향되어 있지는 않은지 확인할 수 있는 탭으로, 각각의 설명변수에 대한 라벨의 분포, 통계치 등을 확인할 수 있다.


'AI' 카테고리의 다른 글
| AutoML-Zero: 'zero' 에서부터 스스로 진화하는 기계학습 알고리즘 (1) (0) | 2020.03.13 |
|---|---|
| Graph Convolutional Networks (GCN) 개념 / 정리 (7) | 2020.03.11 |
| Graph Neural Networks (GNN) / 그래프 뉴럴 네트워크 기초 개념 정리 (2) | 2020.03.10 |
| 페이스북 HiPlot : 딥러닝 하이퍼파라메터 탐색을 돕는 오픈소스 고차원 시각화 툴 (0) | 2020.03.01 |
| 자연어 생성에서의 Beam Search / 파이썬으로 Beam Search 구현하기 (3) | 2020.02.23 |



