자연어 생성 모델
자연어 생성은 단어들의 시퀀스를 아웃풋으로 예측해내는 태스크이다. 일반적으로 생성 모델은 각각의 디코딩 타임 스텝에서 전체 단어 사전에 대한 확률 분포를 예측한다. 따라서 실제로 단어를 생성해내기 위해서는 모델의 예측 확률 분포를 이용해 각 타임스탭의 단어로 변환하는 과정이 필요하다.
아래 그림은 Image Captioning 태스크에서 모델이 4개의 타임 스텝 동안 생성한 확률 분포를 나타낸 예시이다. 첫 번째에서는 V차원의 단어 사전에 대해 '고양이' 토큰의 확률 값이 가장 높은 softmax 값을 예측했고, 마지막 타임 스텝에서는 문장 종료를 나타내는 '<eos>' 토큰에 대한 값이 가장 높은 확률분포를 예측한 것을 볼 수 있다.

이제, 위와 같이 모델이 예측한 확률 분포에 대해 디코딩하기 위해서는 예측된 확률 분포에 따라 가능한 모든 아웃풋 시퀀스의 조합을 탐색(Search) 해야 한다. 그런데 일반적으로 단어 사전은 수만 개의 토큰을 포함하고 있기 때문에 전체 공간을 탐색하는 것은 계산적으로 불가능하다. 따라서 실제로는 휴리스틱한 방법을 사용해 "충분히 좋은" 아웃풋 시퀀스를 생성해내도록 한다.
Greedy Search Decoder
가장 직관적인 방법은 아웃풋 시퀀스에서 생성된 각각의 확률 분포에서 가장 값이 높은 토큰을 선택하는 탐욕 방법이다. 예를 들어 위의 예시에서는 각각의 타임 스텝에서 가장 값이 높았던 '고양이', '위를', '본다', '<eos>'를 최종 시퀀스로 사용한다. 이 방법은 직관적이고 구현이 간단하며 속도가 빠르기 때문에 많은 경우 이 휴리스틱이 잘 작동한다. 하지만 몇몇 경우에서는 실제 최적점과는 거리가 있을 수 있다.
Beam Search Decoder
Beam Search는 탐욕 방법과 함께 가장 많이 사용되는 휴리스틱 방법이다. 각각의 타임 스텝에서 가능도가 가장 높은 하나의 토큰을 선택하는 탐욕법과 달리 beam search에서는 각 스텝에서 탐색의 영역을 k개의 가장 가능도가 높은 토큰들로 유지하며 다음 단계를 탐색한다. 이때 k는 사용자가 지정하는 hyper-parameter이다. k를 크게 가져가면 더 넓은 영역을 탐색하기 때문에 더 좋은 타겟 시퀀스를 생성할 수 있지만, 그만큼 속도가 느려지기 때문에 조절이 필요하다. 일반적으로 기계번역 태스크에서는 beam size k를 5 혹은 10으로 설정한다.
Beam Search Algorithm
parameter k가 주어질 때 예측된 확률 분포의 시퀀스에 대해 beam search를 진행하는 과정은 다음과 같다.
- 각 스텝에서 각각의 후보 시퀀스를 모든 가능한 다음 step으로 확장한다.
- 확장된 후보 스텝에 대해 점수를 계산하는데, 점수는 모든 확률 값을 곱하여 얻는다.
- 가능도가 높은 k개의 시퀀스만 남기고, 나머지 후보들은 제거한다.
- 시퀀스가 끝날 때까지 위의 과정을 반복한다.
여기서 4번째 단계에서 시퀀스의 끝을 판별할 때
- <eos> 토큰이 등장함
- 설정한 최대 길이에 도달
- threshold likelihood 밑으로 가능도가 낮아짐
등의 기준을 추가로 사용할 수 있다.
이때 각 타임 스텝에서의 확률 값은 V차원 단어 사전에 대한 softmax 값으로 매우 작은 값을 가질 수 있다. 따라서 디코딩 스텝이 진행됨에 따라 이 값들을 계속 곱하게 되면 부동소수점 연산에서 underflow가 나타날 수 있기 때문에, 확률 값에 자연로그(log) 변환을 취해 사용한다. 또한 최소화를 통해 해를 찾기 위해 부호 변환을 적용하여 확률 값에 대한 negative log를 곱하는 방식을 사용하는 것이 일반적이다.
Beam Search with Python
아래 코드는 파이썬에서 반복문과 sort 기능을 사용해 beam search를 구현한 예시이다.
import numpy as np
def log(number):
# log에 0이 들어가는 것을 막기 위해 아주 작은 수를 더해줌.
return np.log(number + 1e-10)
def naive_beam_search_decoder(predictions, k):
# prediction = (seq_len , V)
sequences = [[list(), 1.0]]
for row in predictions:
all_candidates = list()
# 1. 각각의 timestep에서 가능한 후보군으로 확장
for i in range(len(sequences)):
seq, score = sequences[i]
# 2. 확장된 후보 스텝에 대해 점수 계산
for j in range(len(row)):
new_seq = seq + [j]
new_score = score * -log(row[j])
candidate = [new_seq, new_score]
all_candidates.append(candidate)
# 3. 가능도가 높은 k개의 시퀀스만 남김
ordered = sorted(all_candidates, key=lambda tup:tup[1]) #점수 기준 정렬
sequences = ordered[:k]
return sequences
단어 사전 V = 10에 대해 4개의 타임 스텝 확률분포를 담은 predictions를 생성해 위의 함수를 테스트해보았다.
import random
seq_len = 4
V = 10
predictions = [[random.random() for _ in range(V)] for _ in range(seq_len)]
그 결과 각 타임 스텝에서 확률 값이 높게 나왔던 index들이 아웃풋 시퀀스의 후보로 뽑혀 나온 것을 볼 수 있다.
최종적으로는 output으로 나온 시퀀스의 인덱스를 단어 사전에서 찾아 자연어 토큰으로 표현해주면 디코딩이 완성된다.
Beam Search Example
아래 그림은 k = 5를 사용한 beam search 과정을 시각화한 것이다.
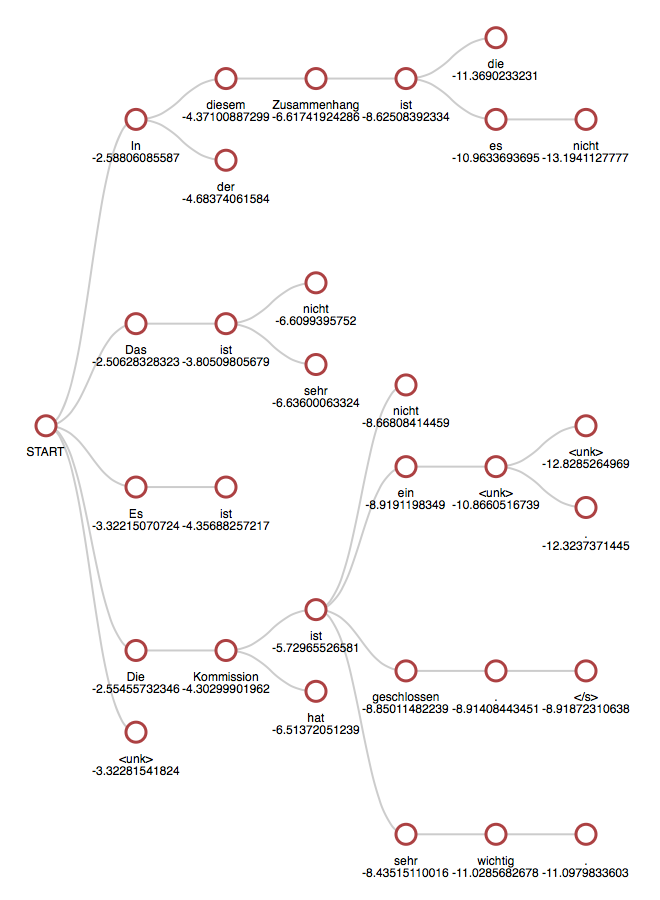
START에서 시작하여 각 타임 스텝을 진행할 때 탐색 사이즈인 5개의 후보군이 유지되며, 최종적으로 다음의 다섯 개 시퀀스로 디코딩된 것을 확인할 수 있다.
- In diesem Zusammenhagn ist es nicht (Not in this group)
- Die Kommission ist ein <unk> <unk> (The commission is <unk> <unk>)
- Die Kommission ist <unk> . (The commission is <unk> .)
- Die Kommission ist geschlossen . </s> (The commission is closed . </s>)
- Die Kommission ist sehr wichtig . (The commission is very important .)

'AI' 카테고리의 다른 글
| AutoML-Zero: 'zero' 에서부터 스스로 진화하는 기계학습 알고리즘 (1) (0) | 2020.03.13 |
|---|---|
| Graph Convolutional Networks (GCN) 개념 / 정리 (7) | 2020.03.11 |
| Graph Neural Networks (GNN) / 그래프 뉴럴 네트워크 기초 개념 정리 (2) | 2020.03.10 |
| 페이스북 HiPlot : 딥러닝 하이퍼파라메터 탐색을 돕는 오픈소스 고차원 시각화 툴 (0) | 2020.03.01 |
| Explainable AI : 설명 가능한 인공지능 / XAI / DARPA / Google XAI / What-if 툴 (0) | 2020.02.23 |



