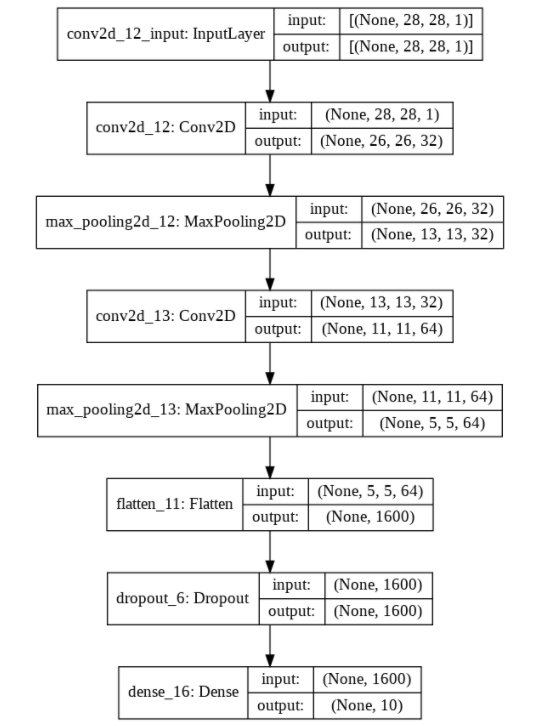
🙋♀️ TensorFlow Conv2D와 MaxPooling2D layer을 익히고, 모델을 만들어 학습하기 1. TensorFlow Conv2D TensorFlow Conv2D> https://www.tensorflow.org/api_docs/python/tf/keras/layers/Conv2D tf.keras.layers.Conv2D( filters, kernel_size, strides=(1, 1), padding='valid', data_format=None, dilation_rate=(1, 1), groups=1, activation=None, ... ) filters : 아웃풋 차원 수 kernel_size : 2d ConV 윈도우의 height & width 설정 strides : stri..